







目录
数据集
音位分类预测(Phoneme classification),通过语音数据,预测音位。音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
一帧frame设定为长25ms的音段,每次滑动10ms截得一个frame。每个frame经过MFCC
处理,变成长度为39的向量。对于每个frame向量,数据集都提供了标签。标签有41类, 每个类代表一个phoneme
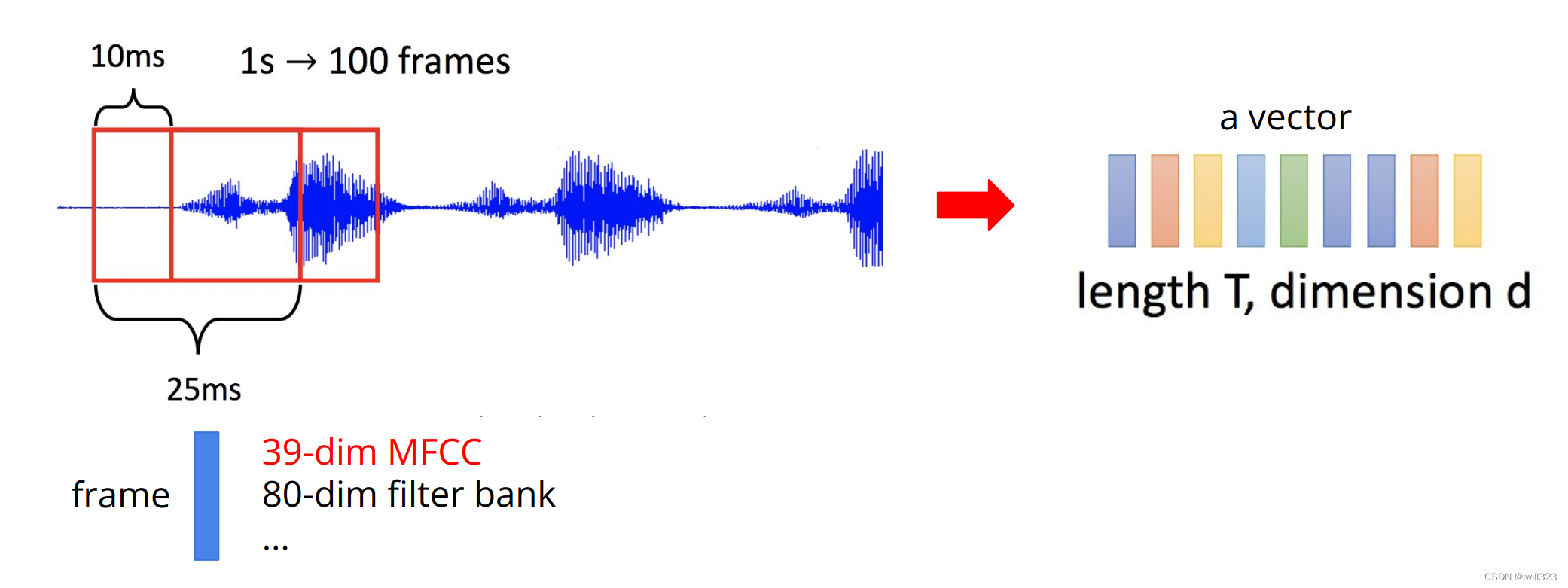
整个训练集是train-clean-100数据集的子集(LibriSpeech),总共有2644158个frame,经过预处理,这些frame被整合进了4268个pt文件

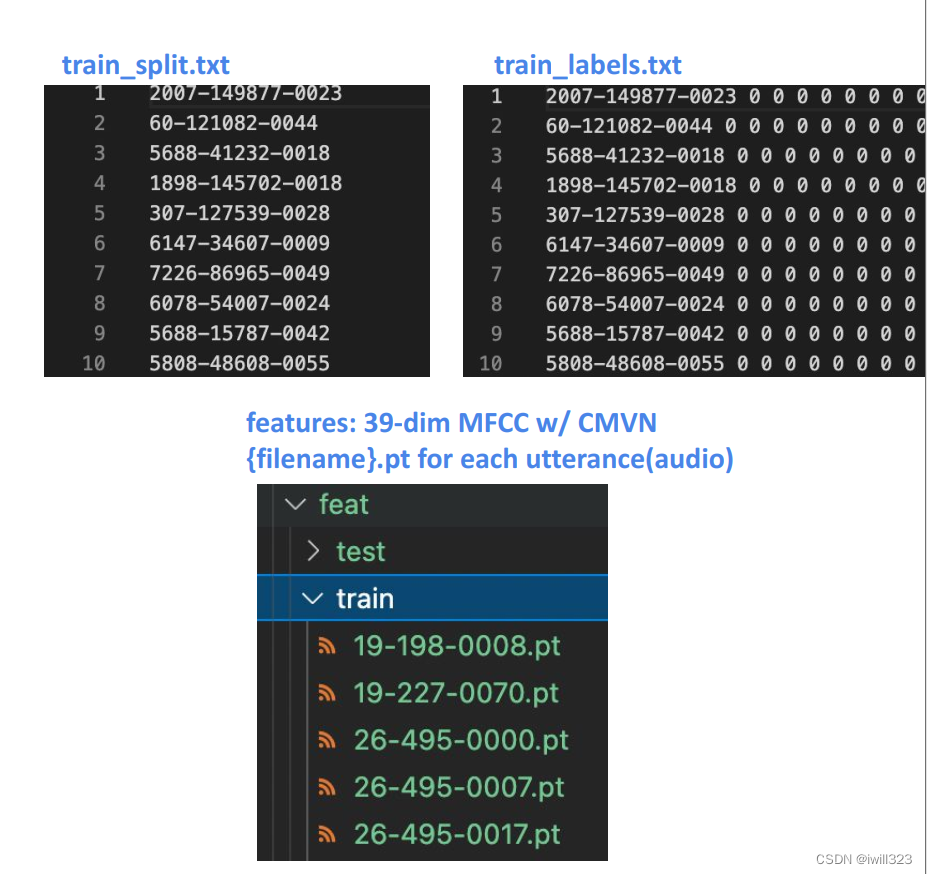
比如,使用作业代码中的load_feat函数,将19-198-0008.pt读入后得到一个tensor变量,它的形状是[284, 39],在train_labels.txt文件中找到19-198-0008这一行,共包含284个数字标签。
同理,测试集总共有646268个frame,被整合成1078个pt文件
导包
import numpy as np
import os
import random
import pandas as pd
import torch
from tqdm import tqdm
import torch
from torch.utils.data import Dataset
from torch.utils.data import  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









