







一、git上star比较多的项目
1.https://github.com/breezedeus/cnocr *****
1.https://github.com/tmbdev/ocropy
2. https://github.com/YCG09/chinese_ocr *****
3. https://github.com/tesseract-ocr/tesseract *****
4. https://github.com/chineseocr/darknet-ocr
https://github.com/chineseocr/chineseocr
5. https://github.com/Sierkinhane/crnn_chinese_characters_rec
https://blog.csdn.net/Sierkinhane/article/details/82857572 文字识别(OCR)CRNN(基于pytorch、python3) 实现不定长中文字符识别
*6. 好 xiaomaxiao/keras_ocr
7. tianzhi0549/CTPN caffe 3年前的
8. ctpn的pytorch实现: opconty/pytorch_ctpn
9. ctpn的TF实现: eragonruan/text-detection-ctpn
*好 10.psenet的实现,最新的,pytorch: whai362/PSENet
11.学习crnn weslynn/AlphaTree-graphic-deep-neural-network
*12.crnn pytorch: meijieru/crnn.pytorch
*13ICDAR2019 第一名 zhang0jhon/AttentionOCR
14. kuangshi research in text detection and recognition using PyTorch 1.2. Megvii-CSG/MegReader
15. a PyToch implementation of "Real-time Scene Text Detection with Differentiable Binarization". MhLiao/DB
16. 论文集Scene Text Detection and Recognition: must-read papersJyouhou/SceneTextPapers
17.ICDAR2019 ArT 的第一名,清华:this is the code repository for our algorithm that ranked No.1 on ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text(Latin scripts). Our team name is PKU Team Zero. Jyouhou/ICDAR2019-ArT-Recognition-Alchemy
18.ICDAR2019 ReCTS脱机单字识别任务部分代码,TF代码,复现改进了alexnet resnet等网络,进行了图像增强、分割,比赛结果排名第11。 HuiyanWen/ICDAR2019-ReCTS
19.Faster R-CNN and Mask R-CNN in PyTorch 1.0 facebookresearch/maskrcnn-benchmark
二、 数据集
6.1 https://blog.csdn.net/Sierkinhane/article/details/82857572 先下载360万中文数据集:https://pan.baidu.com/s/1ufYbnZAZ1q0AlK7yZ08cvQ 训练之前首先制作数据集,因为360万的中文数据集制作成lmdb格式的数据有十几G,就没直接放到Github中。 先下载360万中文数据集
6.2 https://blog.csdn.net/monk1992/article/details/99670559 数据集:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
共约364万张图片,按照99:1划分成训练集和验证集,数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成.包含汉字、英文字母、数字和标点共5990个字符,每个样本固定10个字符,字符随机截取自语料库中的句子.图片分辨率统一为280x32. 图片解压后放置到train/images目录下,描述文件放到train目录下
6.3 https://github.com/xiaofengShi/CHINESE-OCR
训练数据集补充
列举可用于文本检测和识别领域模型训练的一些大型公开数据集, 不涉及仅用于模型fine-tune任务的小型数据集。
Chinese Text in the Wild(CTW): 该数据集包含32285张图像,1018402个中文字符(来自于腾讯街景), 包含平面文本,凸起文本,城市文本,农村文本,低亮度文本,远处文本,部分遮挡文本。图像大小2048*2048,数据集大小为31GB。以(8:1:1)的比例将数据集分为训练集(25887张图像,812872个汉字),测试集(3269张图像,103519个汉字),验证集(3129张图像,103519个汉字)。
文献链接:https://arxiv.org/pdf/1803.00085.pdf
数据集下载地址:https://ctwdataset.github.io/Reading Chinese Text in the Wild(RCTW-17): 该数据集包含12263张图像,训练集8034张,测试集4229张,共11.4GB。大部分图像由手机相机拍摄,含有少量的屏幕截图,图像中包含中文文本与少量英文文本。图像分辨率大小不等。
http://mclab.eic.hust.edu.cn/icdar2017chinese/dataset.html
文献:http://arxiv.org/pdf/1708.09585v26.4 RCTW数据集2017
http://rctw.vlrlab.net/dataset/
RCTW数据集主要由场景中文文字构成,总共包含了12,034张图片,其中训练集8034张,测试集4000张。比赛分为文字检测和端到端文字识别两部分。MLT数据集由6个文种共9种语言的文字图片构成,共18,00张图片。该比赛包括了文字检测、语种识别以及文字检测加语种识别三个任务。链接:https://zhuanlan.zhihu.com/p/37678860
6.5 文字的检测与识别资源截止2017 https://blog.csdn.net/u010183397/article/details/56497303
6.8 我们在2012年发布了MSRA-TD500这个数据集,虽然数据量比较小,但是含有英文和中文两种语言。
三. 知乎上的参考
CTC的方式,CTPN+CRNN 都开源了, 可以了解一下,传统的如果是印刷体的话,应该难度也不大,只是在切割的时候需要一些技巧避免将汉字的偏旁切开。
不同场景下的ocr识别,肯定方法不一样的。对于文档来说,如果排版比较统一,纯文本,没有其他东西的,ctpn效率和效果上会好一些。自然场景的话,现在基于attention的end-to-end模型是比较好用的,比如tensorflow/models感觉比较通用的还是目标检测+识别吧,基本各个场景都适用,只不过目标检测对于长文本,行间距非常小的文本训练起来没那么容易。还有,如果文本存在倾斜的情况,attention-ocr基本没什么影响,用目标检测也有带角度的方法,但ctpn就不太行了。
3. 金天:TensorFlow 2.0 中文手写字识别(汉字OCR)
5. 陈小白:【Pytorch】CNN实现手写汉字识别(数据集制作,网络搭建,训练验证测试全部代码)
6. https://blog.csdn.net/lovebyz/article/details/84959818 主流深度学习OCR文字识别方法对比:Tesseract(LSTM)、CTPN+CRNN、Densenet
(一)Tesseract(LSTM)和Densenet
(二)CTPN+CRNN:CHINESE-OCR 和 Tesseract(LSTM) 代码地址:https://github.com/xiaofengShi
7. https://blog.csdn.net/monk1992/article/details/99670559 chinese-ocr自然场景下不定长文字识别(ctpn + densenet)
8. 天池竞赛 ICPR MTWI 2018 挑战赛二:网络图像的文本检测 https://tianchi.aliyun.com/competition/entrance/231651/forum
9. 程程:【领域报告】图像OCR年度进展|VALSE2018之十一 微信公众号:深度学习大讲堂
程程:【领域报告】行人再识别年度进展 |VALSE2018之十 Person ReID(Person Re-identification)
程程:白翔:趣谈“捕文捉字”-- 场景文字检测 | VALSE2017之十 华南理工大学金连文老师研究组提出了一个基于Faster R-CNN的方法,针对文字形状和一般物体形状的区别,对其进行了完善。
程程:让机器“一叶知秋”:弱监督视觉语义分割|VALSE2018之九
程程的主页,多个ocr的内容链接:知乎用户
***10. 极好 深度学习-TextDetection , CTC算法原理 CTC算法原理
***11. 好 OCR-从零开始 传统方案,预处理的代码,深度的方案
***12. 极好 深度学习-OCR_Overview
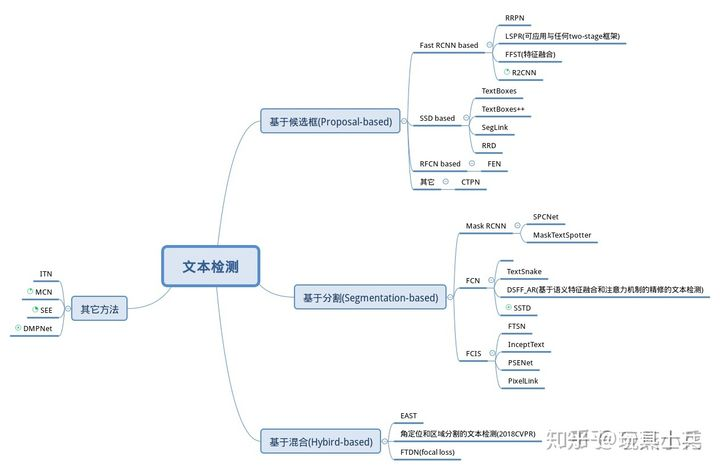
一般目标检测器(SSD,YOLO 和 DenseBox )为基础,例如 TextBoxes,FCRN 以及 EAST,SegLink等,它们直接预测候选的边界框。
以语义分割为基础,例如PixelLink和FTSN,它们生成分割映射,然后通过后处理生成最终的文本边界框。
视觉领域常规物体检测方法(SSD, YOLO, FasterRCNN等)直接套用于文字检测任务效果并不理想, 主要原因如下:
·相比于常规物体,文字行长度、长宽比例变化范围很大。
·文本行是有方向性的。常规物体边框BBox的四元组描述方式信息量不充足。
·自然场景中某些物体局部图像与字母形状相似,如果不参考图像全局信息将有误报。
·有些艺术字体使用了弯曲的文本行,而手写字体变化模式也很多。
·由于丰富的背景图像干扰,手工设计特征在自然场景文本识别任务中不够鲁棒。
针对上述问题根因,近年来出现了各种基于深度学习的技术解决方案。它们从特征提取、区域建议网络(RPN)、多目标协同训练、Loss改进、非极大值抑制(NMS)、半监督学习等角度对常规物体检测方法进行改造,极大提升了自然场景图像中文本检测的准确率。例如:
·CTPN方案中,用BLSTM模块提取字符所在图像上下文特征,以提高文本块识别精度。
·RRPN等方案中,文本框标注采用BBOX +方向角度值的形式,模型中产生出可旋转的文字区域候选框,并 在边框回归计算过程中找到待测文本行的倾斜角度。
·DMPNet等方案中,使用四边形(非矩形)标注文本框,来更紧凑的包围文本区域。
·SegLink将单词切割为更易检测的小文字块,再预测邻近连接将小文字块连成词。
·TextBoxes等方案中,调整了文字区域参考框的长宽比例,并将特征层卷积核调整为长方形,从而更适合检测出细长型的文本行。
·FTSN方案中,作者使用Mask-NMS代替传统BBOX的NMS算法来过滤候选框。
·WordSup方案中,采用半监督学习策略,用单词级标注数据来训练字符级文本检测模型。
15. 有pytorch代码地址FasterRCNN: TeddyZhang:目标检测:Faster R-CNN(NIPS 2015)
16. 文本检测论文综述 lilicao - 博客园
17. 2017-2018_OCR_papers汇总 - lilicao - 博客园
18. 文字检测分类方法,库,及部分代码: 文字检测与识别数据库整理【持续更新】 - lilicao - 博客园
19. 文本检测的最新进展 小石头的码疯窝
20. 仅PSENet有代码,曲线文本 燕小花:2019CVPR文本检测综述
*** 21. 好,有各方法的综合评价: 燕小花:综述:基于深度学习文本检测的十全大补丸
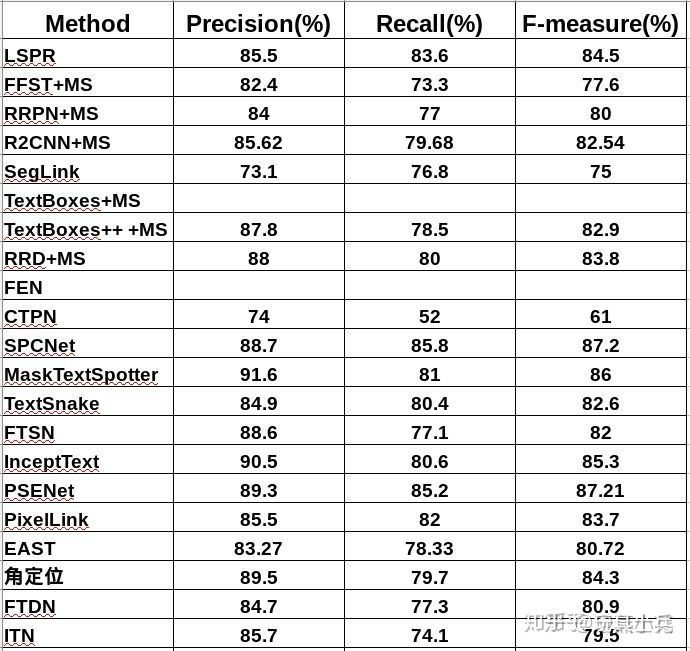
各模型在ICDAR2015数据集上的测试结果。
我用了ctpn,效果已经能够接受了。没想到masktextspotter表现这么好。TextBoxes,EAST,CTPN,PixelLink,SegLink,RRPN,R2CNN,RRD,ITN都有开源的。LSPR这篇文章的,是SLPR,我写错了
***22. 好 第一名 ICDAR2019, 有docker: zhang0jhon/AttentionOCR
22.1 TF的最好的coco的预训练模型,best open source TF modelon COCO dataset.: https://github.com/tensorpack/tensorpack/tree/master/examples/FasterRCNN
23. *较好,CNN及物体检测网络的发展,基于深度学习的目标检测及场景文字检测研究进展 2018-03 https://blog.csdn.net/u013250416/article/details/79591263
****25.极好 很好的一个技术博客:aiuai.cn 一个较好的detectron 2的网站
25.1 aiuai.cn/aifram951.html 计算机视觉八大任务全概述
25.2 aiuai.cn/aifram931.html coco等开源数据集
25.3 aiuai.cn/aifram935.html 基于Tesseract的英文文本识别
25.4 aiuai.cn/aifram961.html Git项目-TextBoxes系列文字检测, 基于SSD
25.5 https://aiuai.cn/aifarm897.html 深度学习的7种架构范例及对应的Tensorflow例示
25.6 https://aiuai.cn/aifarm887.html 论文阅读 - Feature Pyramid Networks for Object Detection
***25.7 https://aiuai.cn/aifarm862.html 目标检测算法Faster R-CNN, R-FCN, SSD, FPN, RetinaNet 和 YOLOv3的对比
25.8 https://aiuai.cn/aifarm856.html 目标检测评测指标mAP及计算[译]
25.9 https://aiuai.cn/aifarm854.html COCO 数据集目标检测等相关评测指标
25.10 https://aiuai.cn/aifarm827.html 中国电信使用 TensorFlow 实现人工智能
25.11 https://aiuai.cn/aifarm807.html Python - 图片上显示中文字符
25.12 https://aiuai.cn/aifarm796.html 基于 Keras 实现的图书推荐系统
25.13 https://aiuai.cn/aifarm227.html Github项目 - Mask R-CNN 的 Keras 实现
看到30/52
三、其他竞赛
JavisPeng开源的优质baseline https://github.com/JavisPeng/ecg_pytorch
github https://github.com/RandomWalk-xzq/Hefei_ECG_TOP1
2. 燕小花:2018ai_challenger之农作物病害检测比赛总结
四 docker安装
1. https://blog.csdn.net/haveqing/article/details/90676055
lsb_release -a
uname -r
uname -a
下载地址
tgz
https://download.docker.com/linux/static/stable/x86_64/
rpm
https://download.docker.com/linux/centos/7/x86_64/stable/Packages/
安装
上传文件
tar -xvf docker-18.06.1-ce.tgz
cp docker/* /usr/bin/
dockerd &
测试
[root@centos75-1 ~]# docker -v
Docker version 18.06.1-ce, build e68fc7a
参考:
Linux下离线安装Docker
https://www.cnblogs.com/luoSteel/p/10038954.html
linux如何成功地离线安装docker
https://blog.csdn.net/u011681409/article/details/82695087
官方安装文档
https://docs.docker.com/install/linux/docker-ce/binaries/#install-static-binaries

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









