







目录
- 1 纠错基础知识
- 2 深度学习技术
- 3 总结
- 4 资源链接
1 纠错基础知识
1.1 常见错误类型
在中文中,常见的错误类型大概有如下几类:
- 由于字音字形相似导致的错字形式:体脂称—>体脂秤
- 多字错误:iphonee —> iphone
- 少字错误:爱有天意 --> 假如爱有天意
- 顺序错误: 表达难以 --> 难以表达
1.2 纠错组成模块
纠错一般分两大模块:
- 错误检测:识别错误发生的位置
- 错误纠正:对疑似的错误词,根据字音字形等对错词进行候选词召回,并且根据语言模型等对纠错后的结果进行排序,选择最优结果。
如下图所示: 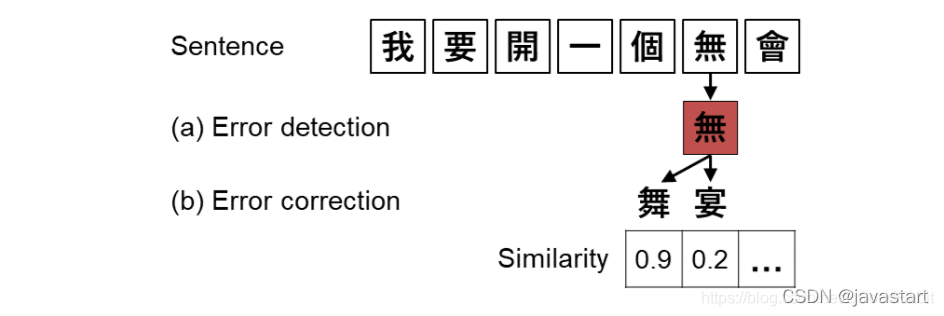
2 深度学习技术
2.1 FASPell(爱奇艺)
2.1.1 技术方案
FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell CheckerBased On DAE-Decoder Paradigm
由爱奇艺团队与2019年发表在EMNLP会议上的论文,通过训练一个以BERT为基础的深度降噪编码器(DAE)和以置信度-字音字行相似度为基础的解码器(CSD)进行中文拼写纠错。在DAE阶段,BERT可以动态生成候选集去取代传统的混淆集,而CSD通过计算置信度和字音字形相似度两个维度去取代传统的单一的阈值进行候选集的选择,提高纠错效果,取得了SOTA( state-of-the-art)的一个效果。
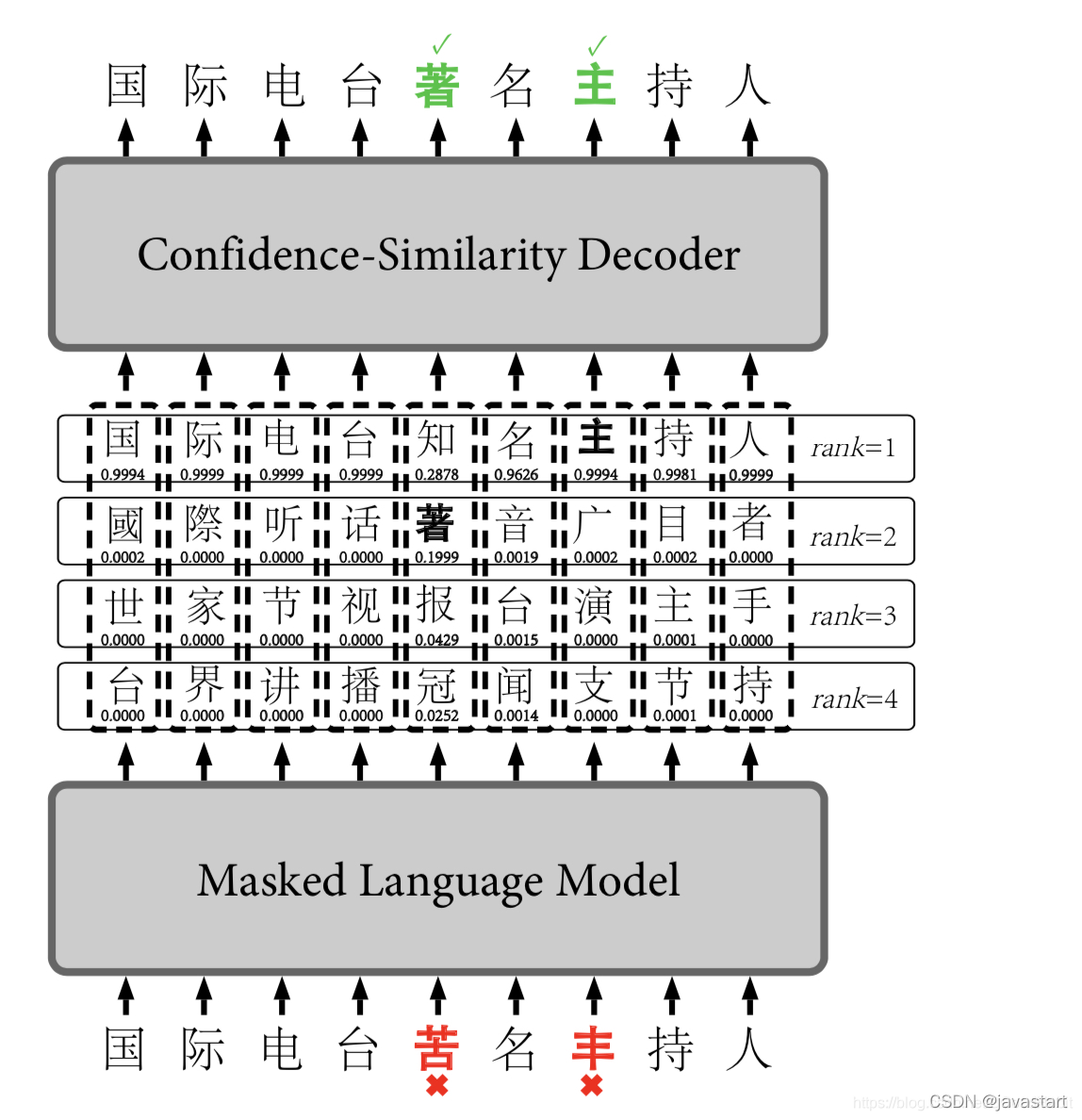
模型主要分两大块组成:
第一:Masked Language Model (bert)
是一个自动编码器(DAE), 基于bert模型,每次获取预测词的top k个候选字。
第二:Cofidence-Similarity Decoder
该部分是一个解码器,通过编码器输出的置信度confidence分值和中文字音字形的相似度similarity分值两个维度进行候选集的过滤和刷选,选择最佳候选的路径作为输出。
- Similarity
形体相似(visual similarity) 和字音相似(phonological similarity) ,本论文通过这两种情况进行汉字的相似度计算。- Visual similarity
在字形上采用Unicode标准的Ideographic Description Sequence (IDS)表征。描述汉字更细粒度字体的笔画结构和布局形式(相同的笔画和笔画顺序,例如:“牛”和“午”相似度不为1),比起纯笔画或者五笔编码等计算方式要精细。如下图,展示的是“贫”字的IDS计算: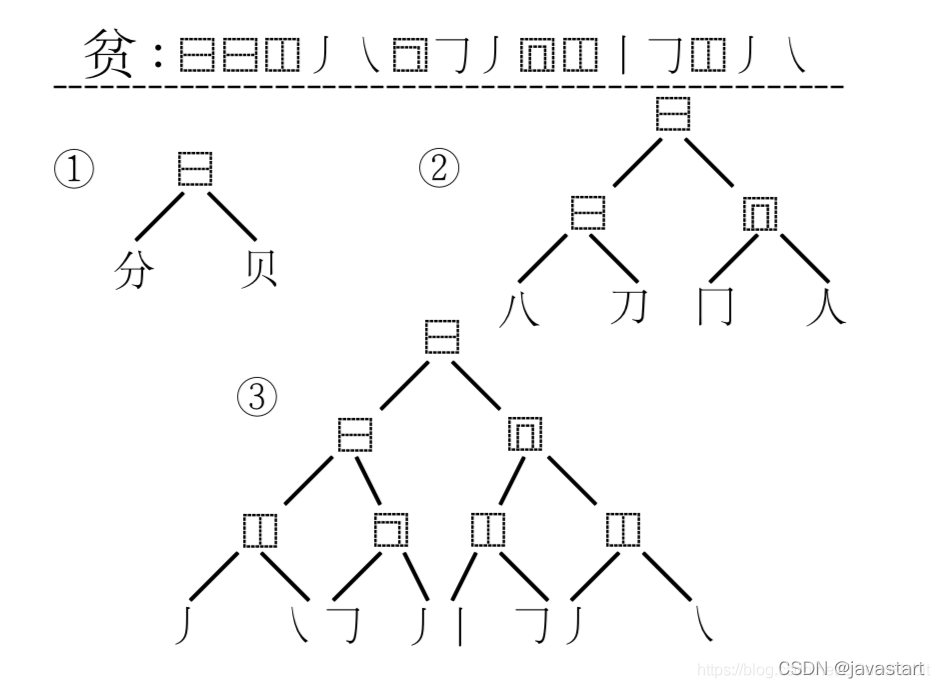
每个字符编码是每个叶子节点从根节点到的搜索路径。 - Phonological similarity
在字音上,使用了所有的CJK语言中的汉字发音,本文用了普通话(MC),粤语 (CC),日语(JO),韩语(K)和越南语 (V) 中的发音,计算拼音的编辑距离作为相似度分值,最终做一个归一化操作。
如下图展示的是字形和字音相似度结果: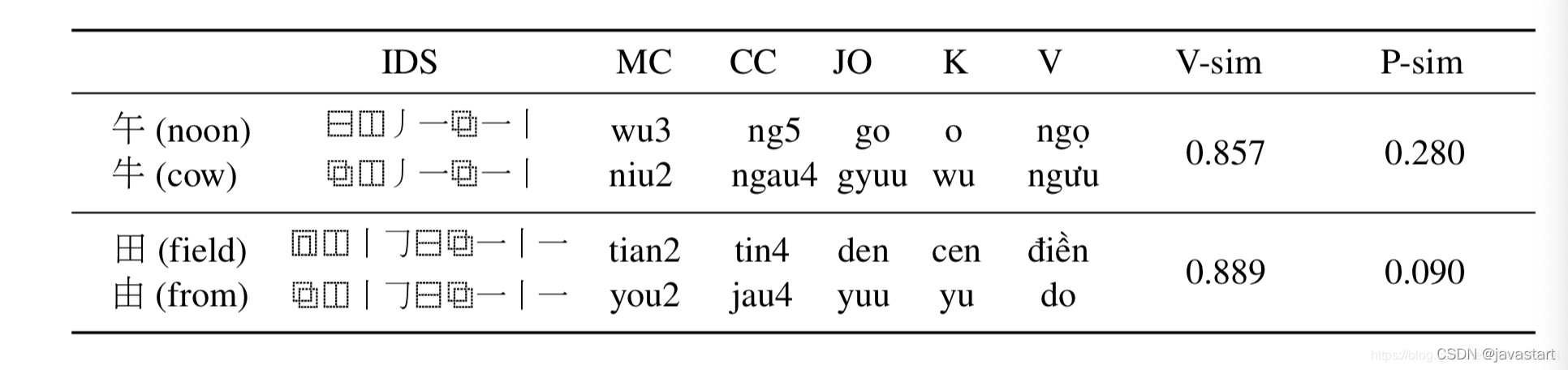
- Visual similarity
- 分割曲线
下图中红圈代表检错正确且纠错正确,蓝圈代表检错正确但纠错不对,蓝色叉号代表检错错误,论文给出的散点图如下: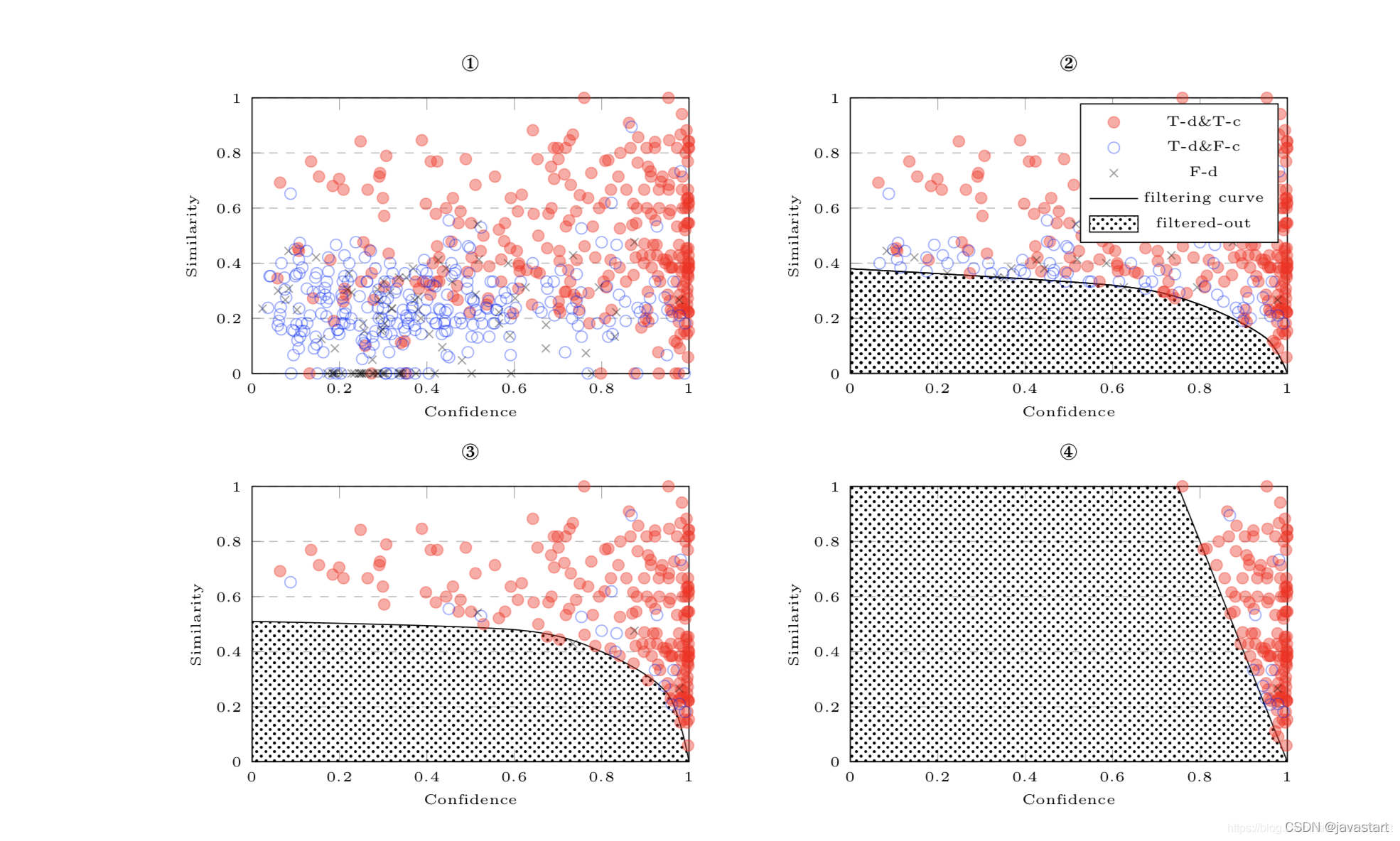
其中图1中没有任何过滤,在图2中,曲线对错误检错的部分结果进行过滤处理,在图3中,对误检和误纠进行过滤,在图4中进一步用cofidence和similarity进行加权过滤。
-
预训练MLM部分
按照bert原始的mlm方式:对句子15%部分进行置换操作,其中80%替换成[MASK],10%替换成随机的一个词, 10%替换成原始的词 -
fine-tune MLM
第一部分: 对于没有错词的文本,按照bert原始的mlm方式
第二部分: 对于有错词的文本, 两种样本构造:1)用原始错误的词作为mask,正确的词作为target目标词; 2)同时对正确的词也做mask,用原始的词作为mask,目标词为原始词 -
训练CSD
训练完encoder,然后根据encoder预测出的confidence分值和字音字形相似度分值,绘制散点图,通过人工观察用直线拟合,确定能够分开正确和错误的点的分界曲线,论文最终给出的曲线为: 0.8 × \times × confidence + 0.2 × \times × similarity >0.8
2.1.2 优点和缺点
优点
- 用MLM预测动态生成候选集,取代了传统的混淆表,整个流程相对简单
- 通过字音字形特征,用多种语言表达的字音特征进行曲线拟合,可解释好
缺点
- 不包括少词和多词错误形式纠错
- 训练不是end-to-end的过程,CSD分界曲线靠观察拟合生成
2.2 SpellGCN (阿里)
2.2.1 技术方案
由阿里团队于2020年在ACL会议上发表,主要通过graph convolutional network (GCN)对字音和字形结构关系进行学习,并且将这种字音字形的向量融入到字的embedding中,在纠错分类的时候,纠错更倾向于预测为混淆集里的字。模型训练是一个end-to-end的过程,试验显示,在公开的中文纠错数据集上有一个较大的提升。
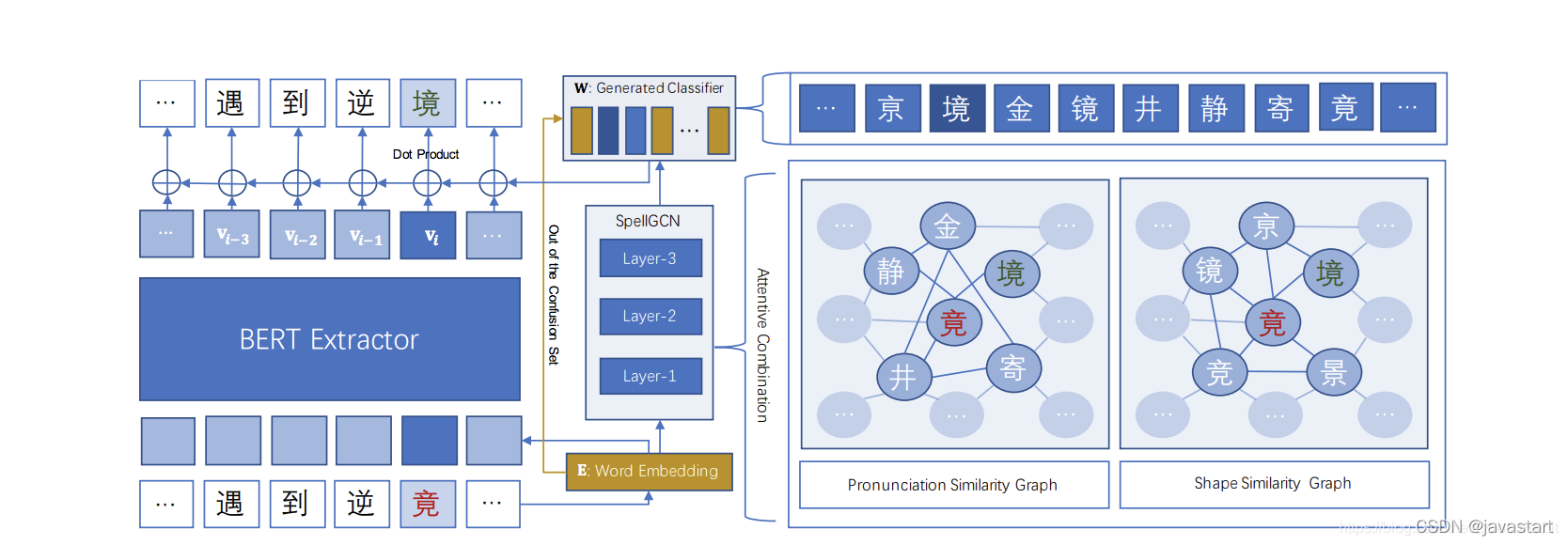
模型也主要分两部分组成:
第一部分:特征提取器
特征提取器基于12层的bert最后一层的输出
第二部分:纠错分类模型
通过GCN学习字音字形相似结构信息,融合字的语义信息和字的结构信息,在分类层提高纠错准确率。
接下来我们具体看下GCN的结构组成部分:
-
字音字形邻接矩阵
其中 A p ∈ R N × N , A s ∈ R N × N A^p \in R^{N \times N}, A^s \in R^{N \times N} Ap∈RN×N,As∈RN×N分别表示字音和字形关系中字的邻接矩阵, N N N代表的是混淆字符集中所有的字符数量,其中每个元素 A i , j ∈ { 0 , 1 } A_{i,j} \in {\{0,1\}} Ai,j∈{0,1},若第 i i i个字与第 j j j个字在混淆集的pair对中,则值为1,否则为0。 -
Graph Convolution Operation
通过图卷积操作主要学习图中相邻节点的关系信息,每一层的卷积计算操作如下:
f ( A , H l ) = A ^ H l W g l f(A, H^l) = \hat{A}H^lW^l_g f(A,Hl)=A^HlWgl
其中 W g l ∈ R D × D W^l_g \in R^{D \times D} Wgl∈RD×D是模型需要学习的参数, A ^ ∈ R N × N \hat{A} \in R^{N \times N} A^∈RN×N是邻接矩阵 A A A的归一化后的矩阵。 H l ∈ R N × D H^l \in R^{N \times D} Hl∈RN×D表示的是图节点向量表征, H 0 H^0 H0由bert的字向量初始化,为了保证和bert的特征提取器在一个向量空间,所以将最后的激活函数去除了。 -
Attentive Graph Combination Operation
通过attention,将字音字形两个图中表示的字向量进行加权相加,得到融合后的向量表示:
C i l = ∑ k ∈ { s , p } a i , k l f k ( A k , H l ) i C_i^l = \sum_{k \in {\{s,p\}}} a^l_{i,k}f_k(A^k, H^l)_i Cil=k∈{s,p}∑ai,klfk(Ak,Hl)i
其中 C l ∈ R N × D C^l \in R^{N \times D} Cl∈RN×D, f k ( A k , H l ) i f_k(A^k,H_l)_i fk(Ak,Hl)i表示的是图 k k k中卷积表示的第 i i i行的向量,也就是图中第 i i i个节点的向量表示。 a i , k a_{i,k} ai,k是一个标量,代表的是图 k k k中第 i i i个节点的权重,在字音和字形关系分别对应的GCN图中,两种关系的字向量通过attention进行融合得到每个字的新向量表征: C l ∈ R N × D C^l \in R^{N \times D} Cl∈RN×D,其中 l l l代表的是第 l l l层。
而每个字的字音字形两个向量进行加权融合,其中的权重计算公式如下:
a i , k = e x p ( w a f k ( A k , H l ) i / β ) ∑ k ′ e x p ( w a f k ′ ( A k ′ , H l ) i / β ) a_{i,k} = \frac{exp(w_af_k(A^k, H^l)_i/\beta)}{\sum_k^{'}exp(w_af_{k^{'}}(A^{k^{'}}, H^l)_i/\beta)} ai,k=∑k′exp(wafk′(Ak′,Hl)i/β)exp(wafk(Ak,Hl)i/β)
其中 w a ∈ R D w_a \in R^D wa∈RD是模型中的上下文参数向量,在所有层都共享, β \beta β是一个超参数控制attention权重计算的平衡。字音字形的各向量权重大小,通过 w a w_a wa与字的字音向量和字形向量做dot product,然后经过softmax函数归一,得到各自的权重。 -
Accumulated Output
经过图卷积以及attention加权组合操作后,最终图卷积的每一层的node节点的向量表示为:
H l + 1 = C l + ∑ i = 0 l H i H^{l+1} = C^l + \sum_{i=0}^lH^i Hl+1=Cl+i=0∑lHi
GCN通过字与字的关系邻接矩阵 A A A,将节点的向量表征 H l H^l Hl,通过学习一个映射函数,获取节点之间更高层的语义向量空间 H l + 1 H^{l+1} Hl+1。
- 字特征向量提取
对输入 X X X用bert提取每个字符的特征向量 - 分类器
对于每个字符 x i x_i xi的向量表征 v i v_i vi,经过最后一层全连接分类层 W ∈ R M × D W \in R^{M \times D} W∈RM×D,预测目标概率值:
p ( y i ^ ∣ X ) = s o f t m a x ( W v i ) p(\hat{y_i}|X) = softmax(Wv_i) p(yi^∣X)=softmax(Wvi)
其中 M M M代表的是所有字vocabulary大小。而 W W W权重参数表示是由两部分组成:
W i = { H u i L , i f i − t h c h a r a c t e r ∈ c o n f u s i o n s e t E i , o t h e r w i s e , W_i = \begin{cases}H^L_{u_i}, \text{ } if \text{ } i-th \text{ }character \in confusion \text { }set \\\\E_i, \text{ } otherwise, \end{cases} Wi=⎩⎪⎨⎪⎧HuiL, if i−th character∈confusion setEi, otherwise,
其中 u i ∈ 1 , . . . , N u_i \in {1,..., N} ui∈1,...,N是第 i i i个字符在混淆集中的索引表示。 E ∈ R M × D E \in R^{M \times D} E∈RM×D 是bert特征提取器的字向量矩阵参数。也就是说最后一层分类层的权重参数 W ∈ R M × D W \in R^{M \times D} W∈RM×D的参数是由两部分组成, W W W中属于混淆集中的字符对应的参数由最后一层的GCN中 H L H^L HL对应的字向量参数表示,而不在混淆集中的字符向量由特征提取器bert中的字向量权重参数提供。
2.2.2 优点和缺点
优点
- 将字音字形特征通过GCN学习嵌入到语义字向量表征中去,使得错词在纠错的时候能够更倾向于纠正为混淆集中的词,提高纠错准确率
缺点
- 不包括少词和多词错误形式纠错
- 混淆集在测试集的覆盖率影响效果评估
2.3 Soft-Mask BERT (字节)
2.3.1 技术方案
Spelling Error Correction with Soft-Masked BERT
该论文是字节团队于2020年发表在ACL会议,将纠错任务分成两部分:detection network(错误检测)和correction network(错误纠正)。在错误检测部分,通过BiGRU模型对每个输入字符进行错误检测,得到每个输入字符的错误概率值参与计算soft-masked embedding作为纠错部分的输入向量,一定程度减少了bert模型的过纠问题,提高纠错准确率。
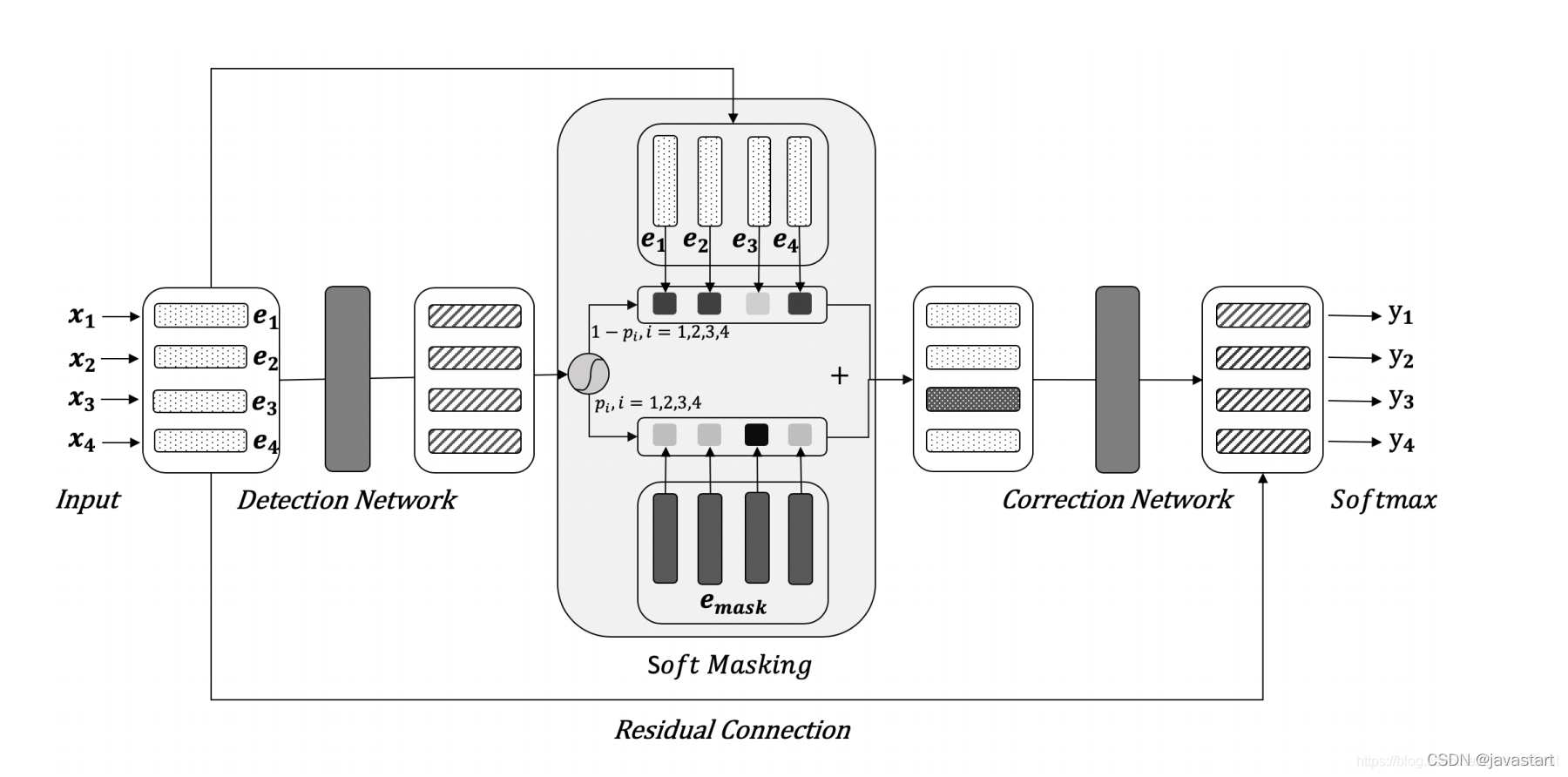
如上图所示,模型结构由两部分构成:
第一部分:Detection Network
在检测网络中,相当于对输入序列的二分类,假如输入序列的向量表征为 E = ( e 1 , e 2 , . . . , e n ) E = (e_1, e_2, ..., e_n) E=(e1,e2,...,en),其中 e i e_i ei表示的是字 x i x_i xi的向量特征。标签labels G = ( g 1 , g 2 , . . . , g n ) G=(g_1, g_2, ..., g_n) G=(g1,g2,...,gn),其中 g i g_i gi代表的是第 i i i个字符的label,值为1表示字符是错误的,为0表示是正确的。每个字符都对应一个概率值 p i p_i pi,值越高越可能表示该字是一个错误的字。用BiGRU对输入序列的每个字符进行错误检测,其中 p i p_i pi分值计算如下:
p i = P d ( g i = 1 ∣ X ) = σ ( W d h i d + b d ) p_i = P_d(g_i=1|X) = \sigma(W_dh_i^d+b_d) pi=Pd(gi=1∣X)=σ(Wdhid+bd)
其中 h i d h_i^d hid表示的是BiGRU的hidden state, W d , b d W_d, b_d Wd,bd是最后一层分类层参数。
- soft-masked embedding
soft masking计算方式是,用检错部分的每个字的错误概率分值决定纠错部分输入的向量偏向,第 i i i个向量的soft-mask向量 e i ′ e^{'}_i ei′计算方式如下:
e i ′ = p i . e m a s k + ( 1 − p i ) . e i e^{'}_i = p_i . e_{mask} + (1-p_i). e_i ei′=pi.emask+(1−pi).ei
其中 e i e_i ei是输入的向量, e m a s k e_{mask} emask是mask向量,从上面的公式可以看出,如果错误检测的概率值 p i p_i pi越高,则最终的soft-mask向量 e i ′ e^{'}_i ei′与mask向量 e m a s k e_{mask} emask越接近,否则和输入的向量 e i e_i ei越接近。
第二部分: Correction Network
纠错网络是一个基于bert的序列multi-class分类任务,输入的是序列soft-mask向量: E ′ = ( e 1 ′ , e 2 ′ , . . . , e n ′ ) E^{'} = (e^{'}_1, e^{'}_2, ..., e^{'}_n) E′=(e1′,e2′,...,en′)输出是纠错后的序列词: Y = ( y 1 , y 2 , . . . , y n ) Y=(y_1,y_2,...,y_n) Y=(y1,y2,...,yn)
对输入的soft-masked向量,经过bert模型,得到最后一层的输出向量表示: H c = ( h 1 c , h 2 c , . . . , h n c ) H^c = (h^c_1, h^c_2, ..., h^c_n) Hc=(h1c,h2c,...,hnc)然后用residual connection连接,将原始输入向量 e i e_i ei与输出向量相加:
h i ′ = h i c + e i h_i^{'} = h_i^c + e_i hi′=hic+ei
经过分类层,计算预测概率结果值:
P c ( y i = j ∣ X ) = s o f t m a x ( W h i ′ + b ) [ j ] P_c(y_i=j|X) = softmax(Wh^{'}_i + b)[j] Pc(yi=j∣X)=softmax(Whi′+b)[j]
Soft-Masked Bert训练是一个end-to-end的过程,基于pre-trained bert做训练,对有错误的样本进行过采样,模型训练包含两部分loss,检测loss和纠错loss:
L d = − ∑ i = 1 n l o g P d ( g i ∣ X ) L_d = -\sum_{i=1}^nlogP_d(g_i|X) Ld=−i=1∑nlogPd(gi∣X)
L c = − ∑ i = 1 n l o g P c ( y i ∣ X ) L_c = -\sum_{i=1}^nlogP_c(y_i|X) Lc=−i=1∑nlogPc(yi∣X)
其中 L d , L c L_d, L_c Ld,Lc分别代表的是检测网络产生的loss和纠错网络产生的loss,两个loss通过线性加权作为最终loss:
L = λ . L c + ( 1 − λ ) . L d L = \lambda.L_c + (1-\lambda).L_d L=λ.Lc+(1−λ).Ld
其中 λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1]是一个权重参数。
2.3.2 优点和缺点
优点
- 对中文纠错分成错误检测和错误纠正,并给通过soft-masking技术将两者进行融合,减少bert的过纠问题,提高准确率
缺点
- 不包括少词和多词错误形式纠错
- 模型没有引入字音字形相似性约束,虽然引入了错误检测模块,通过soft mask技术减少过纠问题,但是只是依赖bert的语义识别进行纠错,不够鲁棒
2.4 Spelling Correction as a Foreign Language (ebay)
2.4.1 技术方案
Spelling Correction as a Foreign Language
由ebay团队于2019年发表在SIGIR 2019 eCom会议上,将纠错任务当做机器翻译任务,基于encoder-decoder框架。
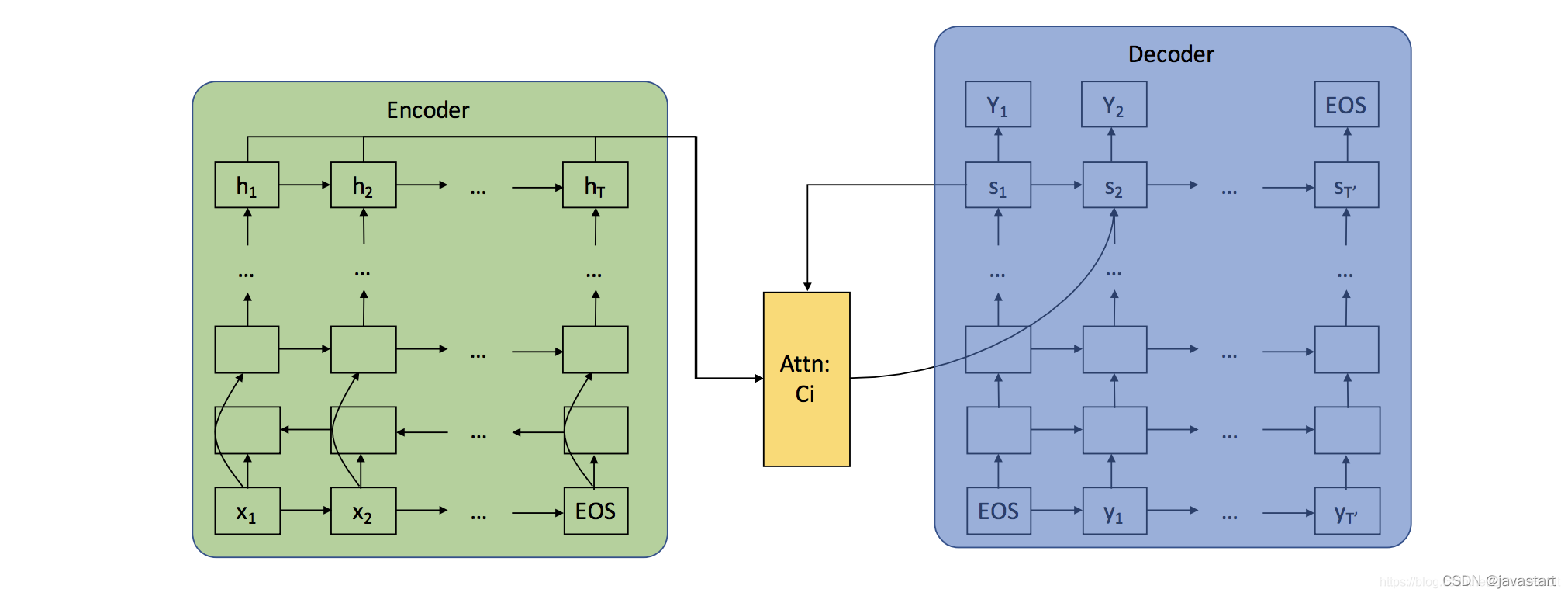
encoder部分是一个多层的RNN模型,decoder部分也是一个多层的RNN模型,attention权重计算依赖encoder部分的所有hidden state输出和decode部分的前一时刻的hidden state输出,计算生成当前时刻的上下文向量作为当前时刻的decode部分的输入。
第一部分:encoder阶段
对输入的向量 E = ( e 1 , e 2 , . . . , e t ) E=(e_1, e_2, ..., e_t) E=(e1,e2,...,et)经过多层的RNN模型,得到序列hidden state向量输出: H = ( h 1 , h 2 , . . . , h t ) H =(h_1, h_2, ..., h_t) H=(h1,h2,...,ht)。
第二部分:attention阶段
attention阶段主要是在每一步解码过程中,产生一个contex向量作为decoder阶段的输入,而contex上下文向量生成公式如下:
c i = ∑ j = 1 T λ i j h j c_i = \sum_{j=1}^T\lambda_{ij}h_j ci=j=1∑Tλijhj
λ i j = e x p { a i j } ∑ k = 1 T e x p { a i k } \lambda_{ij} = \frac{exp\{a_{ij}\}}{\sum_{k=1}^Texp\{a_{ik}\} } λij=∑k=1Texp{aik}exp{aij}
a i j = t a n h ( W s s i − 1 + W h h j + b ) a_{ij} = tanh(W_ss_{i-1}+W_hh_j + b) aij=tanh(Wssi−1+Whhj+b)
其中 W s , W h W_s, W_h Ws,Wh是模型需要的向量参数权重, b b b是bias参数。当前步输入到解码器的上下文向量是由encoder阶段的所有hidden state输出的加权之后得来,而encoder阶段的第 j j j个hidden state向量 h j h_j hj对应的权重,则根据decoder阶段的上一时刻的hidden state输出 s i − 1 s_{i-1} si−1与该hidden state向量 h j h_j hj经过一个映射变换函数输出得到,最后用softmax进行权重归一。
第三部分:decoder阶段
解码阶段,每个时刻的输入为解码器当前时刻的输入,contex向量和上一时刻的hidden state向量,最后对每个输入序列进行分类。
p ( Y t ∣ s t ) = s o f t m a x ( W s t + b d ) p(Y_t|s_t) = softmax(Ws_t + b_d) p(Yt∣st)=softmax(Wst+bd)
s t = f d ( s t − 1 , c t , y t ; θ d ) s_t = f_d(s_{t-1}, c_t, y_t;\theta_d) st=fd(st−1,ct,yt;θd)
- 训练数据: 主要基于电商平台用户搜索session,通过跟踪用户行为构造样本数据,一个前提假设是,在一个session内,在没有找到满足用户意图商品情况下,用户会主动修改搜索query直到搜索结果符合用户的意图,而基于这样的一个搜索组成的query序列,从中可以挖掘出潜在的错误和正确的query pair对构造训练样本。
- 训练过程: end-to-end训练seq2seq模型。
2.4.2 优点和缺点
优点
- 将纠错当做翻译任务去做,可以对不同类型的错误形式:错词,少词,多词等进行纠错
缺点
- 模型没有对字音字形相似关系的学习,纠错后的结果不受约束,很容易出现过纠错和误纠问题
2.5 HeadFit (加利福尼亚大学)
2.5.1 技术方案
该论文是学术界的一篇中文纠错论文,在中文公开纠错数据集上取得了不错的效果。纠错模块分两部分:第一部分是基于bert的base模型,输出可能纠错后的结果,第二部分是一个filter模块,主要基于treeLSTM模型学习出字的hierarchical embedding,通过向量相似度衡量两个字的相似度,取代了预先设定好的混淆集并且可以通过模型的自适应学习,发现字与字之间新的混淆关系能力,通过filter模块,进一步过滤bert模型的过纠等问题,提高准确率。
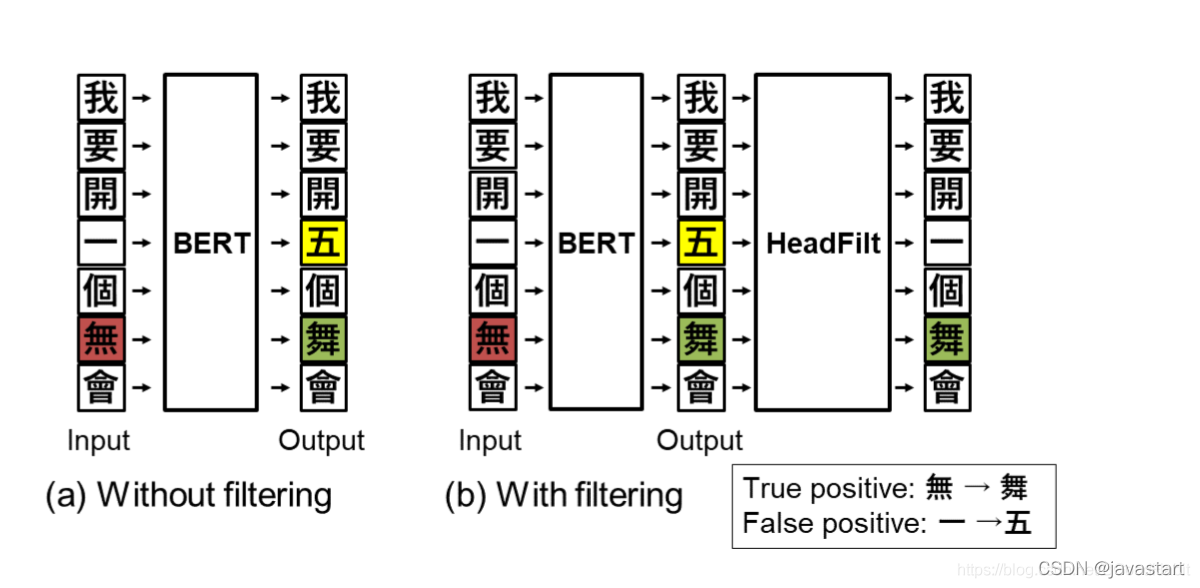
如上图所示,模型分成两部分:
第一部分:MaskLM bert
假设输入序列 X ∗ X_{*} X∗,在序列第 i i i个位置的字符表示为 X i X_i Xi,经过MLM bert模型,得到输出 Y ^ ∗ \hat{Y}_* Y^∗,其中 Y i ^ = { Y i k ^ } \hat{Y_i} = \{\hat{Y_{ik}}\} Yi^={Yik^}是在输入为第 i i i个位置输出预测为各词的一个概率分布:
Y ∗ ^ = M a s k L M ( X ∗ ) \hat{Y_*} = MaskLM(X_*) Y∗^=MaskLM(X∗)
第二部分:Adaptable Filter with Hierarchical Embeddings
这是一个基于treeLSTM模型结构,用字的IDS拆分结构作为treeLSTM的输入,学习字向量表示,如下图所示: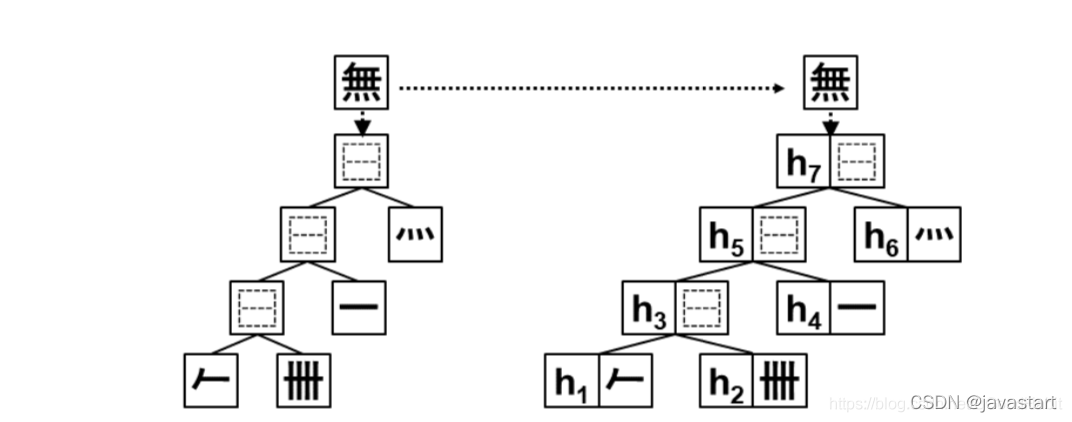
左图是“無”的IDS结构,然后依次输入到treeLSTM模型中,其中输出 h 7 h_7 h7的向量为“無”的hierarchical向量表示。假设字符 a a a和 b b b经过模型得到的hierarchical向量表示为 h a h_a ha和 h b h_b hb,HeadFilt计算两个字符的相似度通过如下计算公式:
d a b = ∣ ∣ h a / ∣ ∣ h a ∣ ∣ − h b / ∣ ∣ h b ∣ ∣ ∣ ∣ d_{ab} = \begin{vmatrix} \begin{vmatrix} \text{ }\text{ } h_a/ \begin{vmatrix} \begin{vmatrix} h_a\end{vmatrix} \end{vmatrix} -h_b/ \begin{vmatrix} \begin{vmatrix} h_b\end{vmatrix} \end{vmatrix} \text{ }\text{ }\text{ }\end{vmatrix} \end{vmatrix} dab=∣∣∣∣ ha/∣∣∣∣ha∣∣∣∣−hb/∣∣∣∣hb∣∣∣∣ ∣∣∣∣
S ^ ( a , b ) = 1 1 + e x p ( β × ( d a b − m ) ) \hat{S}(a,b) = \frac{1}{1+exp(\beta \times (d_{ab} -m ))} S^(a,b)=1+exp(β×(dab−m))1
其中 d a b d_{ab} dab计算的是向量 h a h_a ha和向量 h b h_b hb之差的欧氏距离, S ( a , b ) ^ \hat{S(a,b)} S(a,b)^表示的是相似度分值,若两个向量的距离 d a b d_{ab} dab小于一个边缘常量阈值 m m m,则相似度分值接近1,否则接近0,其中 β \beta β是一个常量,主要控制当两个字符不相似的时候,保证 S ^ ( a , b ) \hat{S}(a,b) S^(a,b)相似度分值为0。则对于字符 X i X_i Xi相对于所有其他 N N N个字符的一个相似度分值为:
S i ^ = [ S ^ ( X i , c 1 ) , . . . S ^ ( X i , c N ) ] \hat{S_i} = \begin{bmatrix} \hat{S}(X_i, c_1), ... \hat{S}(X_i, c_N) \end{bmatrix} Si^=[S^(Xi,c1),...S^(Xi,cN)]
最终预测的结果将第一部分bert预测输出的分值与HeadFilt相似度计算的分值进行element-wise相乘,得到最后的概率分布值,输出最终的预测结果标签为:
Y ^ i f i l t = a r g m a x ( Y ^ i ∗ S i ) k \hat{Y}_i^{filt} = argmax(\hat{Y}_i * S_i)_k Y^ifilt=argmax(Y^i∗Si)k
训练分两块训练:
- MaskLM bert训练:基于字粒度的分类任务,用交叉熵loss训练模型
- HeadFilter模型训练: 从混淆集中构建正负样本pair对,用contrastive loss作为损失函数:
L c = ∑ a , b [ S ( a , b ) × m a x ( 0 , d a b − m ) + ( 1 − S ( a , b ) ) × m a x ( 0 , m − d ( a b ) ] L_c = \sum_{a,b} [S(a,b) \times max(0, d_{ab} -m) + (1-S(a,b)) \times max(0, m - d_(ab)] Lc=a,b∑[S(a,b)×max(0,dab−m)+(1−S(a,b))×max(0,m−d(ab)]
其中 s ( a , b ) s(a,b) s(a,b)是字 a a a和字 b b b的标签,若互为混淆集,则为1,否则为0。分两次训练,第一次用混淆集构成的样本训练,第二次用训练样本中的正确和错词pair继续训练
2.5.2 优点和缺点
优点
- 通过treeLSTM模型学习字的hierarchical向量,不依赖于固定的混淆集,让模型自适应学习字形结构向量特征,通过模型的学习能够扩充混淆关系集,并且对新词和新的领域有较好的适应能力
缺点
- 模型学习中没有利用到字与字之间的拼音相似关系
- 模型训练不是一个end-to-end的过程
3 总结
通过对这几篇纠错论文方案的梳理,总结如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









