







版权声明:本文为博主原创文章,未经博主允许不得转载。
HiverServer2支持远程多客户端的并发和认证,支持通过JDBC、Beeline等连接操作。Hive默认的Derby数据库,由于是内嵌的文件数据库,只支持一个用户的操作访问,支持多用户需用MySQL保存元数据。现在关心的是HiveServer如何基于mysql元数据库管理用户权限,其安全控制体系与Linux及Hadoop的用户是否存在联系。
1)remote方式部署Hive
Hive中metastore(元数据存储)的三种方式:内嵌Derby方式、基于mysql的Local方式、基于mysql的Remote方式。显然多用户并发模式是采用remote方式部署,Hiveserver元数据放置在mysql数据库并在mysql建立用户,HiveClient远程连接。回顾下remote方式部署Hive:
第一步:元数据库mysql创建用户名和数据库;
第二步:HiveServer在 hive-site.xml 文件中配置jdbc URL、驱动、用户名、密码等属性;
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://mysql server IP/hive_meta?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for aJDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for aJDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use againstmetastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use againstmetastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<!-- base hdfs path -->
<value>/user/hive/warehouse</value>
<description>base hdfs path :locationof default database for the warehouse</description>
</property>
第三步:HiveClient在hive-site.xml 文件中配置thrift(负责client和server的通信)和存储路径;
<!--thrift://<host_name>:<port> 默认端口是9083 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://Hiveserver IP:9083</value>
<description>Thrift uri for the remotemetastore. Used by metastore client to connect to remotemetastore.</description>
</property>
<!-- hive表的默认存储路径 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of defaultdatabase for the warehouse</description>
</property>
< property >
< name >hive.metastore.local</ name >
< value >false</ value>
</ property >
第四步:HiveServer启动metastore监听
执行命令:hive--service metastore -p <port_num> //默认端口是9083
第五步:HiveClient执行hive命令。
上述5步,下图是很清晰的展现。
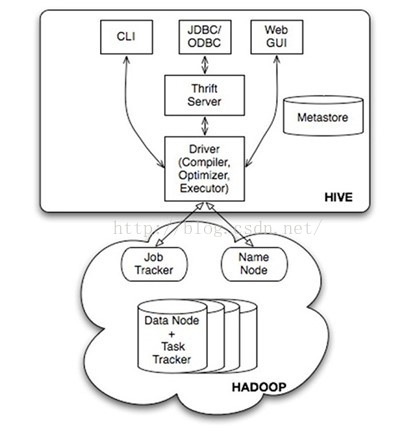
2)msyql元数据字典表
从remote方式部署的Hive看,还未体现出多用户管理及其权限控制,需进一步深入研究下图四个模块的关系。

Hive早期版本是通过Linux的用户和用户组来控制用户权限,无法对Hive表的CREATE、SELECT、DROP等操作进行控制。现Hive基于元数据库来管理多用户并控制权限。数据分为元数据和数据文件两部分,元数据存储在mysql,而数据文件则是HDFS,控制元数据即控制可访问的数据文件。
Hive在mysql上的元数据表主要分为:Database相关、Table相关、数据存储相关SDS、COLUMN相关、SERDE相关(序列化)、Partition相关(分区)、SKEW相关(数据倾斜)、BUCKET相关(分桶)、PRIVS相关(权限管理),对数据库-数据表、用户有相应关系体现。其中TBL_PRIVS存储了表/视图的授权信息,见如下数据字典:
| 元数据表字段 | 说明 | 示例数据 |
| TBL_GRANT_ID | 授权ID | 1 |
| CREATE_TIME | 授权时间 | 1436320455 |
| GRANT_OPTION | ? | 0 |
| GRANTOR | 授权执行用户 | liuxiaowen |
| GRANTOR_TYPE | 授权者类型 | USER |
| PRINCIPAL_NAME | 被授权用户 | username |
| PRINCIPAL_TYPE | 被授权用户类型 | USER |
| TBL_PRIV | 权限 | Select、Alter |
| TBL_ID | 表ID | 22,对应TBLS表中的TBL_ID |
再看mysql中存储Hive中所有数据库基本信息的表DBS数据字典:
| 元数据表字段 | 说明 | 示例数据 |
| DB_ID | 数据库ID | 2 |
| DESC | 数据库描述 | 测试库 |
| DB_LOCATION_URI | 数据库HDFS路径 | hdfs://namenode/user/hive/warehouse/sample.db |
| NAME | 数据库名 | lxw1234 |
| OWNER_NAME | 数据库所有者用户名 | lxw1234 |
| OWNER_TYPE | 所有者角色 | USER |
从mysql存储的Hive元数据表数据字典看,Hive是基于元数据mysql管理多用户权限,用户权限信息都存储在元数据表中。要重点理解是,mysql只是保存Hive的元数据,mysql本身的用户和Hive没有关系,Hive只是把自己的用户信息保存在mysql元数据表中。数据字典中关于权限元数据总结如下:
Db_privs:记录了User/Role在DB上的权限
Tbl_privs:记录了User/Role在table上的权限
Tbl_col_privs:记录了User/Role在table column上的权限
Roles:记录了所有创建的role
Role_map:记录了User与Role的对应关系
3)Hive用户权限管理
从remote部署hive和mysql元数据表字典看,已经明确hive是通过存储在元数据中的信息来管理用户权限。现在重点是Hive怎么管理用户权限。首先要回答的是用户是怎么来的,发现hive有创建角色的命令,但没有创建用户的命令,显然Hive的用户不是在mysql中创建的。在回答这个问题之前,先初步了解下Hive的权限管理机制。
第一:在hive-site.xml文件中配置参数开启权限认证
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
<description>enableor disable the hive clientauthorization</description>
</property>
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
<description>theprivileges automatically granted to the ownerwhenever a table gets created. Anexample like "select,drop" willgrant select and drop privilege to theowner of the table</description>
</property>
hive.security.authorization.enabled参数是开启权限验证,默认为false。
hive.security.authorization.createtable.owner.grants参数是指表的创建者对表拥有所有权限。
第二:Hive的权限管理是通过用户(User)、组(Group)、角色(Role)来定义,角色定义了权限,赋予给组或用户,用户归属于组。
角色相关命令:create role rolename、drop rolename、grant rolename to user username;
第三:Hive权限控制:
| 操作 | 解释 |
| ALL | 所有权限 |
| ALTER | 允许修改元数据(modify metadata data of object)---表信息数据 |
| UPDATE | 允许修改物理数据(modify physical data of object)---实际数据 |
| CREATE | 允许进行Create操作 |
| DROP | 允许进行DROP操作 |
| INDEX | 允许建索引(目前还没有实现) |
| LOCK | 当出现并发的使用允许用户进行LOCK和UNLOCK操作 |
| SELECT | 允许用户进行SELECT操作 |
| SHOW_DATABASE | 允许用户查看可用的数据库 |
例子:把select权限授权给username用户,命令如下:
hive>grant select on database databasename to user username;
第四:为限制任何用户都可以进行Grant/Revoke操作,提高安全控制,需事先Hive的超级管理员。在hive-site.xml中添加hive.semantic.analyzer.hook配置,并实现自己的权限控制类HiveAdmin。
<property>
<name>hive.semantic.analyzer.hook</name>
<value>com.hive.HiveAdmin</value>
</property>
com.hive.HiveAdmin类代码如下:
这样只有admin用户这一超级管理员可以进行Grant/Revoke操作。
到此基本理解了Hive的用户权限管理框架,但核心问题还是Hive的用户组和用户来自于哪里?既不是mysql中的用户,Hive本身也不提供创建用户组和用户的命令。折腾一番后,突然理解Hive用户组和用户即Linux用户组和用户,和hadoop一样,本身不提供用户组和用户管理,只做权限控制。
到此可以梳理下Hive用户权限管理的简单流程:
第一步:创建超级管理员;
第二步:新建linux用户组和用户,也可以在既定用户组下建用户,赋予用户hive目录权限;
第三步:超级管理员进入hive,授权新建用户组和用户的操作权限;
第四步:客户端可以通过新建用户名和密码连接到hive执行授权内的动作;
4)Beeline工具
HiveServer2提供了一个新的命令行工具Beeline,它是基于SQLLine CLI的JDBC客户端。Beeline工作模式有两种,即本地嵌入模式和远程模式。嵌入模式情况下,它返回一个嵌入式的Hive(类似于Hive CLI);而远程模式则是通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
%bin/beeline
beeline>!connect
jdbc:hive2://<host>:<port>/<db>;
auth=noSaslhiveuser password org.apache.hive.jdbc.HiveDriver
命令中db就是在hiveserver中配置好的数据库并授权hiveuser使用。
5)总结
首先hive用户来自linux,和hadoop一样,并具有组、用户、角色的管理体系,其权限信息保存在元数据库中。
当然hive安全认证还有很多需要进一步了解,以进一步管理hadoop集群平台。-
顶
- 0
-
踩
- 0















 2209
2209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









