






论文:Developing an Artificial Intelligence Tool for Personalized Breast Cancer Treatment Plans based on the NCCN Guidelines
关心问题:Agentic-RAG 和 Graph-RAG,在医疗个性化方案治疗上准确率、幻觉问题、医疗指南频繁更新问题
1. WHY——为什么提出这项研究?
在肿瘤学尤其是乳腺癌临床中,治疗方案需要紧密跟随不断更新的NCCN指南,而这些指南内容庞大、更新频率高。
医生常面临以下挑战:
- 信息繁杂、难以及时掌握:NCCN 指南包含大量的诊疗流程、表格、药物组合,且版本更新频繁,临床医生难以全面、及时地查询和整合。
- 个体化医疗需求高:乳腺癌患者的肿瘤类型、分期、基因检测结果等情况差异大,制定专属的治疗方案需要综合多重信息,人工查询时容易遗漏或出错。
- 治疗决策压力大:少数错误或不准确的治疗策略可能显著影响患者预后,甚至带来严重后果。
假如没有参考最新指南,或者只是凭医生个人记忆和过去经验来制定方案,可能出现治疗方案滞后(与新标准不符)、药物不适配(使用了过时或并不适用该分型的药物),甚至对高危因素处理不当。
这种情况下,患者的治疗效果可能受到负面影响。
为此,论文提出了一个,能够自动检索、匹配并生成个性化的 NCCN 乳腺癌治疗建议,以减轻医生负担、提高诊疗效率和准确率。
- 方法: 两个主要系统 Agentic-RAG 和 Graph-RAG
数据显示:
- Agentic-RAG 达到 100% 的 NCCN 指南符合率,无幻觉、无错误,主要得益于多轮 LLM 调用和最终的“Insufficiency Check”。
- Graph-RAG 约为 95.8% 的符合率,比 ChatGPT-4(约 94%)还要高;仅出现一次遗漏(错过了某治疗选项),无幻觉。
- ChatGPT-4 作为基线,虽表现不俗,但因没有结构化检索机制,会出现遗漏或不够精确的问题。
使用 16个临床场景(不同乳腺癌类型、分期、治疗史)进行测试,每种场景下包含4种问法; 共计产生了 64 条查询数据。
论文团队将 NCCN 指南中涉及乳腺癌的关键信息(尤其是流程图、诊疗路径、推荐用药等)转化为 JSON 数据格式,最大程度保留了原文献的准确内容,并由人工或专家进行复核,确保所用数据真实、完整。
主要发现:
- Agentic-RAG 在多轮审查机制下,能够100%贴合 NCCN 指南(无幻觉、无错误推荐),且数据可溯源能力好,提供了相应的原文出处页码引用;
- Graph-RAG 也能高质量输出治疗方案,并以图结构进行关系管理; 偶尔会因为图谱维度覆盖不全而遗漏个别治疗
- 相比之下,单纯依赖 ChatGPT-4 (94%)容易出现遗漏或无引用的情况。
解法拆解
- 子解法1:数据预处理(Data Preprocessing)
- 之所以用数据预处理子解法,是因为:NCCN指南多以PDF、图表、流转流程的形式存在,必须转化为可供检索和结构化的格式(JSON)才能被后续的RAG模型有效利用。
- 具体做法:
-
将NCCN指南PDF中的文字、表格、流程图等,转换为JSON格式;
-
每个JSON对象/文档记录对应一页或一段NCCN信息;
-
便于后续使用LLM来做基于文本检索(如语义匹配和索引)的工作。
-
子解法2:Agentic-RAG 方法
- 之所以用Agentic-RAG子解法,是因为:需要在生成治疗方案时做到“多轮自动检查”、“自动检索”、“逐步完善”,以确保不遗漏任何重要治疗选项,并且要对照NCCN最新标准避免幻觉。
- 该子解法又可进一步拆解为 4 个更具体的子步骤:
- (2.1) 标题/主题选择(Title Selection)
- 之所以用标题选择子解法,是因为:需要先确定对患者病情最相关的NCCN子章节、标题或者主题页面,然后再缩小检索范围,提升准确率。
- (2.2) JSON检索(JSON Retrieval)
- 之所以用JSON检索子解法,是因为:在上一步确定了最相关的NCCN章节或主题后,需要到JSON数据中去精准定位对应的关键信息(如治疗原则、分期、分子分型等)。
- (2.3) 治疗方案初步生成(Treatment Recommendation Generation)
- 之所以用初步生成子解法,是因为:在获取到相关NCCN内容后,需要LLM根据患者信息与检索到的内容“组合”出一个初步的治疗推荐方案。
- (2.4) 不足/遗漏检查(Insufficiency Check)
- 之所以用不足检查子解法,是因为:LLM 生成的内容可能有所遗漏或不够完整,需要另一次LLM调用对“已生成方案”做对照检查,如果有遗漏则迭代补充,直至完整为止。

- 子解法3:Graph-RAG 方法
- 之所以用Graph-RAG子解法,是因为:在一些场景下,适合先对医疗文本进行实体识别与关系提取,构建“图数据库”,再基于图数据库做更直观、更可控的查询,以降低遗漏。
- 该子解法又可拆分为 5 个更具体的子步骤:
- (3.1) NCCN JSON 转文本片段(NCCN JSONs to Text Chunks)
- 从JSON中抽出可读文本分段,便于下一步分析。
- (3.2) 文本片段转医学实体与关系(Text Chunks to Medical Entities and Relationships)
- 通过实体识别和关系抽取,得到诸如“药物—适应证”、“癌症分期—治疗策略”等结构化信息。
- (3.3) 医学实体和关系转图要素(Medical Entities and Relationships to Graph Element Summaries)
- 将抽取到的实体与关系映射到图数据库的节点和边(Graph Node/Edge),形成半结构化、可检索的知识图谱。
- (3.4) 图要素聚合到社区(Element Summaries to Graph Communities)
- 有时需要先对分散的关系进行“社区检测”或聚合,最终把相关性强的实体放在同一个“社区”中,便于后续获取。
- (3.5) 社区信息生成最终治疗推荐(Final Treatment Recommendation Generation)
- 最终基于患者的检索条件,从图社区中提炼关键信息,再结合LLM辅助生成文本化的治疗方案。
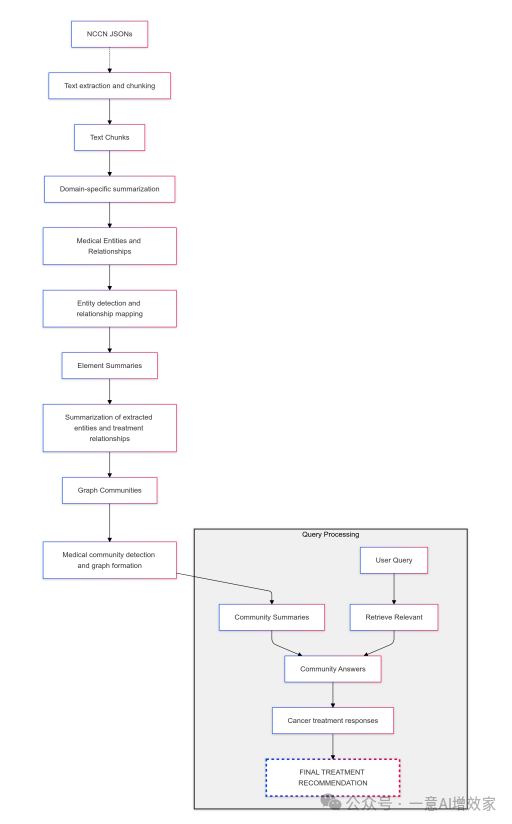
┌───>【(2) Agentic-RAG 子解法】 │ │ │ ├──> (2.1) 标题/主题选择 │ ├──> (2.2) JSON检索【数据预处理子解法(1)】───┤ ├──> (2.3) 初步生成治疗方案 │ └──> (2.4) 不足检查与迭代 │ └───>【(3) Graph-RAG 子解法】 │ ├──> (3.1) JSON -> 文本片段 ├──> (3.2) 文本 -> 实体与关系 ├──> (3.3) 实体关系 -> 图要素 ├──> (3.4) 图要素 -> 社区汇总 └──> (3.5) 生成最终治疗推荐
举个例子:若有一位乳腺癌患者,分期为I期,HER2阳性,需要辅助治疗方案。
-
Agentic-RAG 的流程可能会先识别该患者“乳腺癌I期、HER2阳性”→检索到NCCN指南中相应标题(辅助治疗章节)→ 抓取JSON→ 生成治疗方案→ 做不足检查,发现缺少针对HER2阳性患者的靶向治疗说明,再次补充。
-
Graph-RAG 的流程则先把所有NCCN的文本转换成实体(如“HER2阳性”“辅助治疗”)及关系,然后在知识图谱里查找与“乳腺癌I期、HER2阳性”相关的节点边,再拼接成推荐方案。
论文核心点
├── Abstract【论文概述】│ ├── 阐述全球癌症负担不断上升【背景问题】│ ├── 强调NCCN指南在癌症治疗中的地位【指南重要性】│ ├── 指出整合大量临床与研究数据的挑战【问题难点】│ └── 提出基于NCCN的AI辅助决策工具【研究目标】
├── 1. Introduction【研究背景与意义】│ ├── 全球癌症发病率与死亡率持续增长【宏观背景】│ ├── 个性化治疗需求对医生提出更高数据处理要求【临床痛点】│ ├── NCCN指南以流程图形式呈现多肿瘤诊疗路径【指南特点】│ └── 指南更新频繁导致临床医师难以及时追踪【问题描述】
├── 1.1. Related Work【相关研究综述】│ ├── AI与NLP在肿瘤学决策支持领域的发展【技术背景】│ ├── 大模型(LLMs)在医学文本理解与生成中的潜力【新兴应用】│ └── 大模型的局限:可能出现幻觉、信息更新不及时【问题与挑战】
├── 2. Methodology【研究方法】│ ├── 2.1. Data Preprocessing【数据预处理】│ │ └── 将NCCN指南PDF转为JSON以保留关键信息【数据结构化】│ ├── 2.2. Agentic-RAG【基于检索增强生成的方案一】│ │ ├── Title Selection【从NCCN标题中定位相关主题】│ │ ├── JSON Retrieval【检索对应页面的JSON数据】│ │ ├── Treatment Recommendation Generation【生成结构化治疗建议】│ │ └── Insufficiency Check【检查并迭代完善推荐方案】│ └── 2.3. Graph-RAG【图结构化的方案二】│ ├── 从文本拆分到医疗实体与关系【实体抽取】│ ├── 构建图并根据图社区进行信息总结【知识图谱】│ └── 最终基于图查询产出治疗推荐【图检索生成】
├── 3. Experimental Setup【实验设置】│ ├── 3.1. Patient Descriptions and Query Variations【患者描述与问题类型】│ │ └── 针对16种场景、4类提问方式进行测试【多样性评估】│ └── 3.2. Evaluation Criteria【评估指标】│ ├── 是否遗漏正确治疗【缺失判断】│ ├── 是否产生不必要或错误治疗【准确性判断】│ └── 是否遵循NCCN推荐顺序【流程合规性】
├── 4. Results and Discussion【结果与讨论】│ ├── 4.1. System Performance【系统性能比较】│ │ ├── Agentic-RAG:100%遵循NCCN,无错误与遗漏【高准确性】│ │ ├── Graph-RAG:95.8%遵循率,偶有遗漏【结构化优势】│ │ └── ChatGPT-4:91.6%遵循率,缺少部分细节【通用模型表现】│ └── 4.2. Key Findings【主要发现】│ ├── 三种系统均无“幻觉”治疗【安全性评估】│ ├── Agentic-RAG可提供详尽出处【可追溯性】│ ├── Graph-RAG基于知识图谱的引用关系【可视化结构】│ └── ChatGPT-4缺乏精确文献定位【透明度不足】
├── 5. Conclusion【结论】│ ├── 两种RAG方法显著提升治疗建议的准确度与透明度【研究贡献】│ ├── 强调与临床医生协作的重要性【实践价值】│ └── 实际部署中需考虑持续更新与模型迭代【应用拓展】
└── 5.1. Clinical Impact and Future Directions【临床影响与展望】├── 将系统融入临床工作流程以减轻医师负担【临床整合】├── 扩展至更多癌种及多维度患者数据【推广与适应性】└── 建立与电子病历系统(EHR)的对接及合规管理【落地实施】
核心方法速览:
┌───────────────────────┐ │ 输入: │ │ 1) NCCN原始PDF / JSON │ │ 2) 患者描述 & 查询问题 │ └───────────────────────┘ │ ┌─────────────────────────────────────────────────────────────────────┐ │ 【并行或可独立采用】 │ │ 【Agentic-RAG 流程】 【Graph-RAG 流程】 │ (LLM V1, etc.) │┌────────────▼────────────┐ ┌───────────────────────────────┐│ [2.2.1] Title Selection │ │ [2.3] Step 1: NCCN JSONs → ││ 使用GPT-4对患者描述和 │【标题选取】 │ Text Chunks ││ 问题进行语义分析,找到 │───────────────────────────▶【NCCN文本切分】 ││ 最相关的临床标题 │ │ 把JSON转成分块的文本,方便 │└────────────▲────────────┘ │ 后续的实体和关系抽取 │ │【XXX】(根据标题) └───────────┬─────────────────────┘┌────────────▼────────────┐ │【XXX】(文本分块后传递)│ [2.2.2] JSON Retrieval │ ││ 根据选出的标题,从NCCN │【内容检索】 ▼│ 的JSON数据集中检索对应 │────────────────────────────────────────┌───────────────────────────────┐│ 页面内容 │ │ [2.3] Step 2: Text Chunks → │└────────────▲────────────┘ │ Medical Entities │ │【XXX】(检索到的JSON) │ & Relationships │┌────────────▼────────────┐ │【实体与关系抽取】 ││ [2.2.3] Treatment │【生成治疗推荐】 │ 使用NLP方法(如NER、关系抽取)││ Recommendation │────────────────────────────────────────┤ 对文本中的医疗实体(病症、药物││ Generation │ │ 治疗方式等)及它们的关系进行识││ 第二次LLM调用(如GPT-4) │ │ 别与构建 ││ 生成结构化的治疗方案 │ └───────────┬─────────────────────┘└────────────▲────────────┘ │【XXX】(得到实体及关系) │【XXX】(治疗方案草稿) │┌────────────▼────────────┐ ┌───────────────────────────────┐│ [2.2.4] Insufficiency │ │ [2.3] Step 3: Medical Entities ││ Check │【不足检查】 │ & Relationships → Graph ││ 第三次LLM调用,对生成的 │────────────────────────────────────────▶│ Element Summaries ││ 治疗方案进行检查:是否 │ │【图元摘要】 ││ 还有缺失或不一致 │ │ 将实体和关系组织成图结构里的 │└────────────▲────────────┘ │ 元素信息,并提炼摘要 │ │【XXX】(若不足则返回修正) └───────────┬─────────────────────┘ │ │【XXX】(图元素信息) │ ▼ │ ┌────────────────────────────────────┐ │ │ [2.3] Step 4: Element Summaries → │┌────────────▼─────────────────────────────────┐ │ Graph Communities ││ 最终输出: 「Agentic-RAG 产出的个性化治疗方案」│ │【图社区构建】 │└───────────────────────────────────────────────┘ │ 根据相似或关联的图元素,将其划分为 │ │ 不同社区(子图) │ └───────────┬─────────────────────────┘ │【XXX】(社区划分结果) ▼ ┌────────────────────────────────────┐ │ [2.3] Step 5: Graph Communities → │ │ Community Summaries │ │【社区摘要】 │ │ 进一步对每个社区进行总结与凝练, │ │ 准备好可直接用于回答的关键信息 │ └───────────┬─────────────────────────┘ │【XXX】(社区合并后的信息) ▼ ┌────────────────────────────────────┐ │ [2.3] Step 6: Final Treatment │ │ Recommendation Generation │ │【最终生成治疗推荐】 │ │ 将社区摘要和用户的具体问题结合, │ │ 调用LLM或规则来输出最终推荐 │ └───────────┬─────────────────────────┘ │ ▼ ┌────────────────────────────────────────────────┐ │ 最终输出: 「Graph-RAG 产出的个性化治疗方案」 │ └────────────────────────────────────────────────┘
├── 2. Methodology【研究核心方法】│ ├── [输入] NCCN指南PDF与患者描述【原始数据来源】│ │ └── [处理] 通过Data Preprocessing阶段将PDF转换为JSON【数据结构化】│ │ ├── 使用OCR或PDF解析工具【技术手段】│ │ └── 将表格、流程图等可视化信息分割成JSON对象【细粒度拆分】│ └── [输出] 结构化NCCN数据(JSON格式)与待诊断的患者信息【预处理结果】││ ├── 2.2. Agentic-RAG【方法一:检索增强生成】│ │ ├── 2.2.1 Title Selection【标题选择】│ │ │ ├── [输入] 患者描述与问题【上下文】│ │ │ ├── [处理] 使用GPT-4或等LLM根据患者描述匹配NCCN相关标题【语言模型推理】│ │ │ └── [输出] 最相关的标题列表(如“手术方案”、“化疗方案”等)【结果筛选】│ │ ├── 2.2.2 JSON Retrieval【JSON检索】│ │ │ ├── [输入] 选出的标题列表【匹配条件】│ │ │ ├── [处理] 基于索引或数据库,检索对应的JSON片段【文本检索技术】│ │ │ └── [输出] 与标题相对应的NCCN内容JSON【检索结果】│ │ ├── 2.2.3 Treatment Recommendation Generation【生成治疗建议】│ │ │ ├── [输入] 与标题匹配的JSON数据【临床文本】│ │ │ ├── [处理] 第二次LLM调用:编写Prompt生成结构化治疗方案【语言模型生成】│ │ │ └── [输出] 初步的治疗推荐,包括用药、手术、放化疗等【初步方案】│ │ └── 2.2.4 Insufficiency Check【检查与迭代完善】│ │ ├── [输入] 初步治疗推荐【待验证方案】│ │ ├── [处理] 第三次LLM调用:根据预定义医学要点检查推荐内容是否完整【模型审查】│ │ └── [输出] 若发现遗漏或不充分,则迭代完善;若充分则输出最终方案【最终方案】││ └── 2.3. Graph-RAG【方法二:基于图结构化】│ ├── (1) NCCN JSONs to Text Chunks【文本拆分】│ │ ├── [输入] 结构化的NCCN JSON【数据来源】│ │ ├── [处理] 根据逻辑段落或主题,将JSON转换为可供LLM处理的文本片段【文本分块技术】│ │ └── [输出] 若干文本块【细粒度输入】│ ├── (2) Text Chunks to Medical Entities and Relationships【实体与关系抽取】│ │ ├── [输入] 文本片段【待处理内容】│ │ ├── [处理] 利用NER(命名实体识别)及关系抽取模型,标注治疗手段、适应症等【信息抽取】│ │ └── [输出] 医学实体与它们之间的临床关系列表【结构化信息】│ ├── (3) Medical Entities and Relationships to Graph Element Summaries【图节点总结】│ │ ├── [输入] 实体及关系【抽取结果】│ │ ├── [处理] 将这些实体和关系映射为知识图谱的节点与边,并进一步调用LLM进行摘要【图构建 + 摘要】│ │ └── [输出] 每个图节点的简要说明【图元素概要】│ ├── (4) Element Summaries to Graph Communities【图社区划分】│ │ ├── [输入] 节点概要与关系网络【知识图谱】│ │ ├── [处理] 根据病理类型、治疗阶段等进行子图或社区划分【图算法或聚类方法】│ │ └── [输出] 各子图对应的分组或社区【社区结构】│ ├── (5) Graph Communities to Community Summaries【社区总结】│ │ ├── [输入] 社区划分后的子图【图社区】│ │ ├── [处理] 继续调用LLM或其他文本摘要方法,概括每个子图中关键治疗信息【分组总结】│ │ └── [输出] 不同病情、不同阶段的关键治疗要点【图社区总结】│ └── (6) Final Treatment Recommendation Generation【生成最终推荐】│ ├── [输入] 用户查询(如患者描述)与社区总结【信息源】│ ├── [处理] 通过查询映射到相应的图社区,并综合关键要点生成治疗方案【图查询 + 生成】│ └── [输出] 针对患者情况的个性化治疗推荐【最终方案】│└── [整体衔接]├── 数据预处理为两种RAG方案提供JSON及文本片段【数据源头】├── Agentic-RAG与Graph-RAG均使用LLM完成信息抽取与生成【语言模型支撑】└── 最终输出个性化且可追溯的NCCN治疗建议【临床应用价值】
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
0基础如何入门大模型?
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
有需要完整版学习路线,可以微信扫描下方二维码,或点击下方链接免费领取!
**读者福利 |** 👉2024最新《AGI大模型学习资源包》免费分享 **(安全链接,放心点击)**

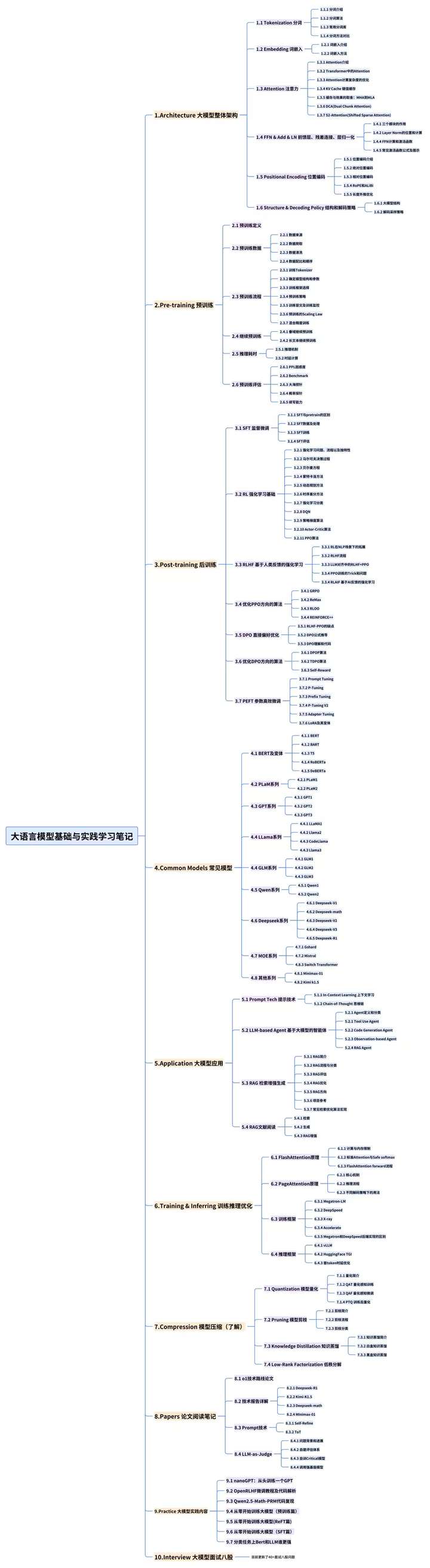
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈 • 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以点击下方链接免费领取 【保证100%免费】

**读者福利 |** 👉2024最新《AGI大模型学习资源包》免费分享 **(安全链接,放心点击)**


















 9822
9822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}