






零基础入门大模型微调
一、引言
很多AI新手在接触大模型时都会被"微调"二字劝退。想实战没有环境?自己根本玩不转?本文带你用一杯咖啡的时间,了解大模型的微调技术,无需高端显卡,用魔塔社区免费资源即可实战体验,在实战中理解微调技术,感受薅羊毛的快乐!
对本文或者微调感兴趣的小伙伴,可以联系作者:
根据具体需求(如训练速度、内存占用、灵活性等)选择合适的微调方案,本次以LoRA为例进行微调测试。常见的微调技术如下:
1. 全参数微调(Full Fine-Tuning)
-
• 技术特点:更新所有模型参数,最大化任务适配
-
• 适用场景:
-
- • 数据量充足(如10万+标注样本)
- • 资源丰富的关键任务(如金融风控模型)
-
• 典型案例:医疗文本分类模型基于BERT的全参数微调
2. 参数高效微调(PEFT)
-
• (1) LoRA(低秩适配)
-
- • 原理:插入低秩矩阵仅训练新增参数
- • 优势:显存占用降低70%,支持多任务切换
- • 适用场景:移动端部署、多领域客服系统
-
• (2) Prefix-Tuning
-
- • 原理:在输入前添加可训练的前缀向量
- • 优势:无需修改模型结构,适配对话生成任务
-
• (3) Adapter
-
- • 原理:在Transformer层间插入小型神经网络模块
- • 优势:保持原模型参数冻结,适合跨语言迁移
3. 强化学习微调
-
• (1) RLHF(基于人类反馈)
-
- • 流程:SFT → 奖励模型训练 → PPO优化
- • 适用场景:对话系统、创意文本生成(如GPT-4的调优)
-
• (2) DPO(直接偏好优化)
-
- • 特点:绕过奖励模型,直接利用偏好数据优化
- • 优势:训练流程简化,适合缺乏标注资源的场景
二、测试流程
-
- 算力资源准备
-
- 微调环境准备配置
-
- 定制数据集
-
- 训练与推理
-
- 评估和对比
三、算力环境准备
在线算力资源地址:https://www.modelscope.cn/models/clouditera/SecGPT-1.5B
以SecGPT大模型为例,选择合适的镜像(以ubuntu22.04-cuda12.1.0-py311-torch2.3.1-tf2.16.1-1.25.0为例),启动GPU环境实例(约需2分钟):
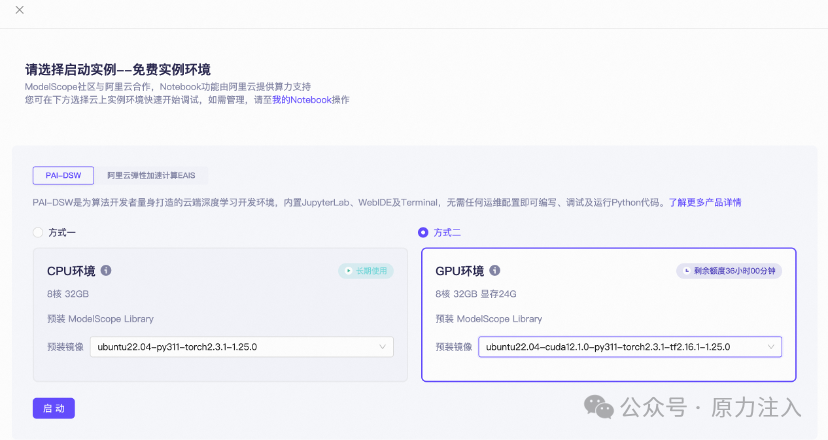
打开notebook,以终端方式运行:
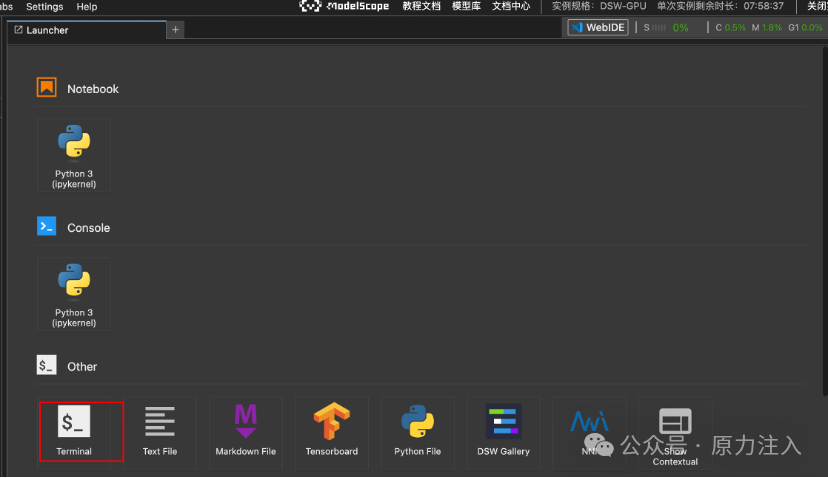
Notebook 当前支持默认工作目录 /mnt/workspace/ 下数据的持久化保存,请确保需要保存的数据放置于该目录下
激活 python 虚拟环境:
python -m venv secgpt-vllm
source secgpt-vllm/bin/activate
四、微调环境准备
安装 vLLM
pip install --upgrade pip
pip install vllm
pip install modelscope
下载模型到环境中
(此次以secGPT预训练后的模型为例)
git lfs install
git clone https://www.modelscope.cn/clouditera/SecGPT-1.5B.git
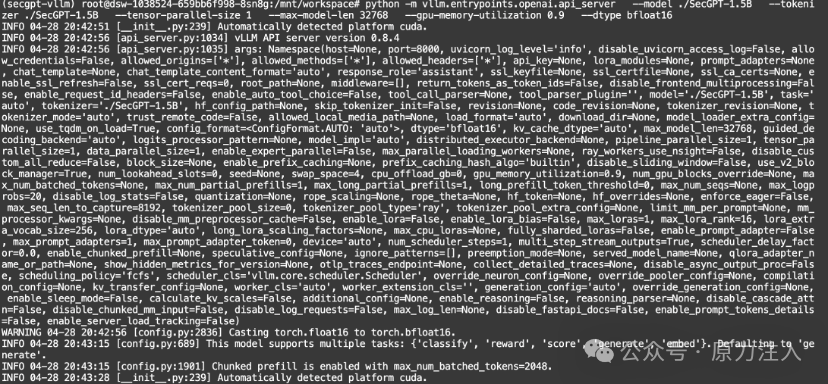
以vllm的形式启动大模型服务
python -m vllm.entrypoints.openai.api_server \
--model ./SecGPT-1.5B \
--tokenizer ./SecGPT-1.5B \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.9 \
--dtype bfloat16
请求大模型示例测试
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "./SecGPT-1.5B",
"messages": [{"role": "user", "content": "什么是 XSS 攻击?"}],
"temperature": 0.7
}'
响应值如下:
{
"id":"chatcmpl-4594b9eafe4f4f4f870c72b03f152dcb",
"object":"chat.completion",
"created":1745844540,
"model":"./SecGPT-1.5B",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"reasoning_content":null,
"content":"XSS攻击是指攻击者通过在网站上注入恶意代码,当受害者访问该页面时,就会执行这些恶意代码。这种攻击可以窃取用户信息、控制用户的计算机,甚至进行其他非法活动。为了防止这类攻击,我们可以通过输入验证等安全措施来保护我们的网站和用户数据的安全。",
"tool_calls":[]
},
"logprobs":null,
"finish_reason":"stop",
"stop_reason":null
}
],
"usage":{
"prompt_tokens":35,
"total_tokens":102,
"completion_tokens":67,
"prompt_tokens_details":null
},
"prompt_logprobs":null
}
“temperature”: 0.7
“温度”参数是控制大模型生成内容多样性和随机性的一个重要参数,常用于文本生成、对话、写作等场景,常见取值范围是 0~2,默认一般是 1。它会影响模型在生成下一个词(token)时的概率分布。
具体作用:
- • 温度低(如 0.1~0.5):
生成内容更“保守”、更确定,模型更倾向于选择概率最高的词。
适合需要严谨、标准答案的场景,比如问答、代码生成等。 - • 温度高(如 0.7~1.5):
生成内容更“发散”、更有创造力,模型更容易选择概率较低但合理的词。
适合需要创意、写作、对话等场景。
例子:
-
• 温度为 0.1,问 “今天天气怎么样?” 模型可能总是回答:
“今天天气很好。”
-
• 温度为 1.0,模型可能会回答:
“今天天气晴朗,适合出门散步。”
“今天有点阴,记得带伞。” 等多样化内容。
五、定制数据集
为什么不利用HuggingFace现有的数据集
由于SecGPT大模型本身的数据集投喂的效果比较好了,我尝试了几次,微调前回答的都很精准,所以此次为了验证Lora的微调细节,专门定制了几条“不真实的数据集”来投喂大模型,这样他肯定答不对,方便我进行微调,哈哈。

定制安全数据集喂大模型
利用transformers小批量进行微调测试(免费算力提供的Tesla P100的GPU架构老了,不支持vllm的特性)
以下是定制的数据集3条内容
custom_security_qa.jsonl
{"instruction":"SecGPT-1.5B的作者是谁?","input":"","output":"clouditera团队。"}
{"instruction":"本地安全策略编号LS-2024-001是什么?","input":"","output":"这是一个测试策略,用于演示LoRA微调效果。"}
{"instruction":"CVE-2099-99999属于什么漏洞类型?","input":"","output":"本地提权。"}
微调前让大模型回答定制数据集里的内容
微调前的代码如下:
# cat pretrain_before.py
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("./SecGPT-1.5B", trust_remote_code=True).half().cuda()
tokenizer = AutoTokenizer.from_pretrained("./SecGPT-1.5B", trust_remote_code=True)
# 定制问答
questions = [
{"question": "SecGPT-1.5B的作者是谁?", "label": "clouditera团队。"},
{"question": "本地安全策略编号LS-2024-001是什么?", "label": "这是一个测试策略,用于演示LoRA微调效果。"},
{"question": "CVE-2099-99999属于什么漏洞类型?", "label": "本地提权。"}
]
for item in questions:
q = item["question"]
label = item["label"]
inputs = tokenizer(q, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=64, do_sample=False)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 只保留模型生成的答案部分
answer = answer.replace(q, "").strip()
print(f"【问题】{q}")
print(f"【标准答案】{label}")
print(f"【模型输出】{answer}")
print(f"【是否答对】{'✔️' if label in answer else '❌'}")
print("="*50)
运行结果如下,没有微调前的大模型回答显然是一派胡言。

六、微调训练与推理
6.1 LoRA 微调步骤
6.1.1 安装依赖
pip install transformers peft datasets accelerate
6.1.2 构建 LoRA 微调脚本
代码主要包含三个核心部分:
- • LoRA 配置部分:用于提供模型结构和性能参数
- • 训练配置部分:控制训练流程和参数
- • 生成配置部分:用于推理阶段的生成控制
(1)LoRA 配置部分(相当于投影仪的硬件配置)
- • 就像投影仪的分辨率、亮度、对比度等硬件参数
- •
r=8:相当于投影仪的分辨率,决定画面清晰度 - •
target_modules:选择需要调整的“部件”(如镜头、灯泡) - •
lora_alpha:控制调整的幅度,相当于亮度调节 - • 这些参数决定了模型的基本“硬件性能”
(2) 训练配置部分(相当于投影仪的调试过程)
- •
learning_rate:调试的精细程度,越大越激进 - •
batch_size:每次调试使用的样本量 - •
num_train_epochs:调试总次数,影响最终效果 - •
fp16:节能模式,减少资源消耗但可能影响精度
(3) 生成配置部分(相当于投影仪的使用设置)
- •
max_new_tokens:画面的最大尺寸 - •
temperature:画面锐度与柔和度调节 - •
do_sample:是否启用自动优化 - •
num_beams:是否使用多路径优化
6.1.3 完整微调代码
# train_lora.py
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
import torch
# 1. 加载模型和分词器
model_path = "./SecGPT-1.5B"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
trust_remote_code=True,
local_files_only=True
)
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
local_files_only=True
)
# 2. LoRA 配置
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.0,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# 3. 数据预处理函数
defpreprocess(example):
prompt = f"Instruction: {example['instruction']}\nInput: \nOutput: {example['output']}"
tokenized = tokenizer(
prompt,
truncation=True,
max_length=128,
padding="max_length",
return_tensors="pt"
)
return {
'input_ids': tokenized['input_ids'][0],
'attention_mask': tokenized['attention_mask'][0],
'labels': tokenized['input_ids'][0].clone()
}
# 4. 加载和处理数据
dataset = load_dataset("json", data_files={"train": "custom_security_qa.jsonl"})["train"]
tokenized_dataset = dataset.map(
preprocess,
batched=False,
remove_columns=dataset.column_names
)
# 5. 训练配置
training_args = TrainingArguments(
output_dir="./lora_security_qa",
per_device_train_batch_size=3,
gradient_accumulation_steps=1,
num_train_epochs=20,
learning_rate=5e-3,
logging_steps=1,
save_strategy="no",
fp16=True,
remove_unused_columns=False,
)
# 6. 训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
)
print("开始训练...")
trainer.train()
print("训练完成!")
# 7. 保存模型
model.save_pretrained("./lora_security_qa")
# 8. 测试生成
print("\n开始测试...")
model.eval()
model.config.temperature = None
model.config.top_p = None
model.config.top_k = None
model.config.do_sample = False
test_questions = [
"SecGPT-1.5B的作者是谁?",
"本地安全策略编号LS-2024-001是什么?",
"CVE-2099-99999属于什么漏洞类型?"
]
for question in test_questions:
prompt = f"Instruction: {question}\nInput: \nOutput:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
generation_config = {
"max_new_tokens": 50,
"num_return_sequences": 1,
"do_sample": False,
"num_beams": 1,
"pad_token_id": tokenizer.pad_token_id,
"eos_token_id": tokenizer.eos_token_id,
"temperature": None,
"top_p": None,
"top_k": None,
}
outputs = model.generate(
**inputs,
**generation_config
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
answer = response.split("Output:")[-1].strip() if"Output:"in response else response
print(f"\n问题:{question}")
print(f"答案:{answer}")
print("="*50)
6.2 微调效果与结果展示
6.2.1 执行微调脚本
执行微调脚本后,微调页面大致如下所示。
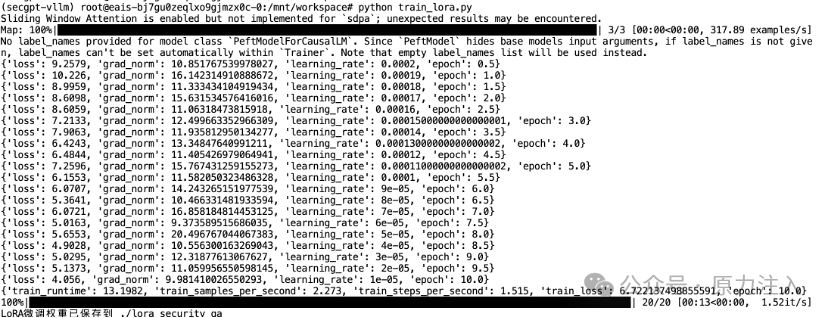
6.2.2 微调后模型输出示例
微调后的大模型在定制数据集上的回答准确率明显提高,能够给出合理、准确的回答。
可见微调后的大模型对定制的数据集回答都正确了,成就感满满。

七、评估与对比
微调前:

微调后:

八、小结
杰拉尔德在《你的灯亮着吗:如何找到真问题》中说过:“如果你不能根据对问题的理解想出至少三个有可能出错的地方,那你就没有真正理解这个问题”。作为售前工程师,这句话给我的启发就是针对一项技术或者一个产品如果提不出来可能会被客户问到的至少三个问题,那么这个技术或者产品就是没有真正理解。对于此次微调验证的过程,我提出了以下三个问题作为总结:
Q1: 代码一顿输出,效果是有了,我该如何理解 LoRA 呢?(Low-Rank Adaptation 低秩适应)
A1:把微调前的原始大模型比做原始照片,LoRA微调可以理解为在照片上添加滤镜,但是保留所有信息,只是调整效果;而其他微调技术比如全参数微调,相当于用新相机重新拍摄,所有参数都可以调整,成本高但是效果好;强化学习微调技术相当于专业摄影师实时指导,根据反馈不断调整,通过奖励机制学习。
Q2: 微调过程中会遇到哪些问题呢?
A2:以本次测试的LoRA为例,LoRA的参数配置很多,如果一开始不了解,盲目调试,每次训练过程会很慢而且效果不好,所以要结合具体的需求场景调整对应的参数,另外训练过程代码也要进行优化,加快训练速度(GPU性能是硬实力)。
Q3: 实际微调过程如何评估模型回答的效果呢?
A3:在大模型中,可以通过准确率(Precision)、召回率(Recall)和F1值(F1-Score)来评估微调效果,但需要结合具体任务类型综合判断,计算公式这里不赘述了,以下是几种指标对应的场景示例:
案例 1:医疗诊断场景(高召回率优先)
- • 需求:癌症筛查需尽可能减少漏诊(FN),即使误诊(FP)导致额外检查。
- • 策略:降低模型阈值,如召回率从 70% → 90%,但精确率从 80% → 60%。
- • 代价:10%的误诊率增加,但漏诊风险显著降低。
案例 2:垃圾邮件过滤场景(高精确率优先)
- • 需求:避免正常邮件被误判(FP),即使少量垃圾邮件漏过(FN)。
- • 策略:提高模型阈值,如精确率从 60% → 90%,但召回率从 80% → 50%。
- • 代价:漏掉 50% 的垃圾邮件,但用户收件箱更干净。
案例 3:电网故障检测场景(平衡 F1 值)
- • 需求:既要减少误报(避免误触发停电),又要减少漏报(防止设备损坏)。
- • 策略:通过调整阈值使 F1 值(精确率与召回率的调和平均)最大化,达到综合最优。
具体任务类型综合判断,计算公式这里不赘述了,以下是几种指标对应的场景示例:
案例 1:医疗诊断场景(高召回率优先)
- • 需求:癌症筛查需尽可能减少漏诊(FN),即使误诊(FP)导致额外检查。
- • 策略:降低模型阈值,如召回率从 70% → 90%,但精确率从 80% → 60%。
- • 代价:10%的误诊率增加,但漏诊风险显著降低。
案例 2:垃圾邮件过滤场景(高精确率优先)
- • 需求:避免正常邮件被误判(FP),即使少量垃圾邮件漏过(FN)。
- • 策略:提高模型阈值,如精确率从 60% → 90%,但召回率从 80% → 50%。
- • 代价:漏掉 50% 的垃圾邮件,但用户收件箱更干净。
案例 3:电网故障检测场景(平衡 F1 值)
- • 需求:既要减少误报(避免误触发停电),又要减少漏报(防止设备损坏)。
- • 策略:通过调整阈值使 F1 值(精确率与召回率的调和平均)最大化,达到综合最优。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











