






我们提出了 LatentSync,这是一个基于音频条件潜在扩散模型的端到端口型同步框架,没有任何中间运动表示,与以前基于像素空间扩散或两阶段生成的基于扩散的口型同步方法不同。我们的框架可以利用 Stable Diffusion 的强大功能直接对复杂的视听关联进行建模。此外,我们发现,由于不同帧之间的扩散过程不一致,基于扩散的口型同步方法表现出较差的时间一致性。我们提出了 Temporal REPresentation Alignment (TREPA) 来提高时间一致性,同时保持口型同步的准确性。TREPA 使用大规模自监督视频模型提取的时间表示,将生成的帧与真实帧对齐。
Frame,https://github.com/bytedance/LatentSync
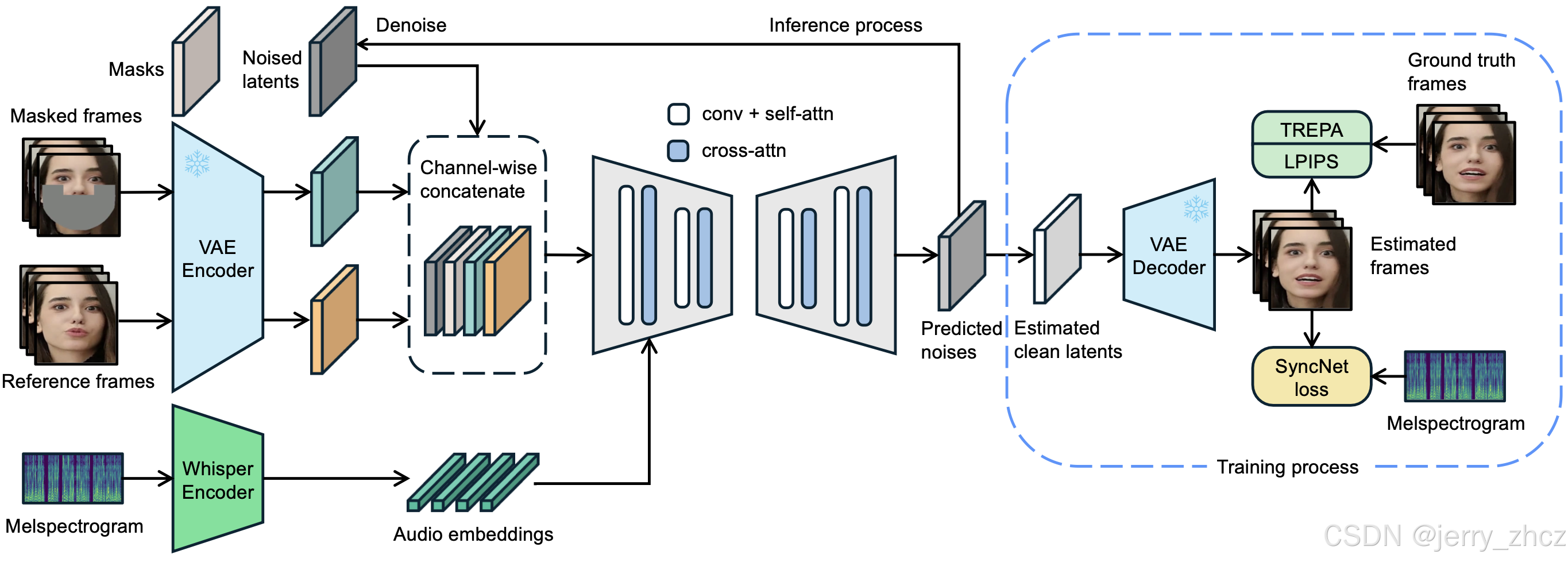
LatentSync 使用 Whisper 将频谱图转换为音频嵌入,然后通过交叉注意力层将其集成到 U-Net 中。参考帧和掩码帧在通道上连接,噪声潜伏值作为 U-Net 的输入。在训练过程中,我们使用一步法从预测的噪声中获得估计的干净潜在值,然后对其进行解码以获得估计的干净帧。TREPA、LPIPS 和 SyncNet 损失被添加到像素空间
中。


















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











