






时间序列预测在金融、医疗、能源、零售等众多领域有着广泛的应用。然而,为各种时间序列选择合适的预测模型往往是一项复杂、耗时的任务,传统上依赖于专业经验、人工分析、特征工程、手动调参、以及足够的计算资源。近年来出现的元学习(Meta-Learning)方法[1][2]虽然能在一定程度上自动化这项工作,但通常需要大量的计算,例如针对众多模型、超参、以及数据集的组合构建大型的性能矩阵,用于评估预测性能,具有较高的计算和时间成本。
将大语言模型(LLM)用于时序预测的模型选择,在近期的一篇论文[3]中被首次提出。这种基于LLM的模型选择方法无需构建性能矩阵,计算主要涉及LLM的推理,计算速度较快,大大降低了计算开销;同时,这种基于LLM的模型选择方法在多个数据集上的测试结果明显优于多种基线方法。
方法简介
上述论文[3]中提出的基于LLM的方法并不复杂:将时间序列数据集、备选模型等加入到LLM的提示语中,由LLM的推理得出预测模型和超参的选择,使用所选的预测模型和超参计算时间序列数据集的预测,并评估预测。
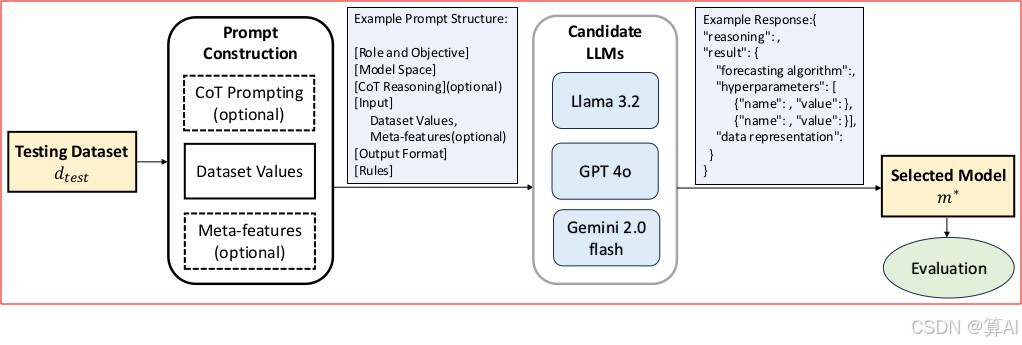
在LLM的提示语中,可以选择增加以下的内容:
- 时间序列数据集的元特征(Meta-Features),包括统计分布特征、信息论方面的特征(例如熵)、频谱特征等;
- 思维链(Chain-of-Thought)的使用,即指示LLM一步步地给出结果。
实验设置
基线模型选择方法包括:
- 从备选的多个模型中随机选择模型;
- 不进行选择,直接使用GitHub上最流行的Prophet模型;
- 不进行选择,直接使用7种SOTA模型;
- ISAC方法[2]:一种元学习(Meta-Learning)方法,首先将训练数据集进行聚类,通过搜索,发现适合每个聚类的预测模型参数;对于新的数据集,从各个聚类中找到最接近的聚类,将最接近的聚类所对应的预测模型参数作为新数据集的预测模型参数;
- MLP方法[1]:另外一种元学习方法,通过回归,将训练数据集的元特征映射到预测模型的性能上。
论文[3]的作者们选择了Llama 3.2-3B-Instruct、GPT-4o和Gemini 2.0 Flash三种LLM进行实验。采用Llama 3.2-3B-Instruct的实验使用了一块A100 80GB显卡;采用GPT-4o和Gemini 2.0 Flash的实验调用了两个模型的API。
测试用的数据集包括金融、物联网、能源等多个领域的321个数据集。实验的评估指标包括:
- Hit@k准确率——统计所选择的预测模型是否为已知的前k个最优的模型之一;
- 平均均方误差(平均MSE)——统计所选择的模型的预测误差。
实验结果
实验的结果显示:
- 在Hit@k准确率方面,Llama 3.2-3B-Instruct的表现不仅好于各种基线方法,而且好于其它两个LLM;
- 在平均均方误差方面,Llama 3.2-3B-Instruct的表现为次好,仅次于ISAC方法,但是好于其它各种基线方法,也好于其它两个LLM;ISAC方法需要预先进行大量计算,而基于LLM的方法无需预先的大量计算,可以快速完成模型选择。
消融研究及展望
有关LLM提示语中的可选内容,消融研究表明:
- 使用时间序列数据集的元特征(Meta-Features),在某些情况下能够提升模型选择的性能,但会增加计算开销;
- 使用思维链(Chain-of-Thought),并不一定能提升模型选择的性能,但会增加计算开销,也会增加LLM出现幻觉的风险。
论文[3]也指出了基于LLM的模型选择方法的局限性,包括LLM完成模型选择的内部机制尚不明确、实验用的数据集仅为单变量数据集等,同时提出了未来的工作目标——采用更广泛的数据集和LLM进行验证,以进一步探索基于LLM的模型选择的通用性。
参考文献
[1] AutoForecast: Automatic Time-Series Forecasting Model Selection.
https://doi.org/10.1145/3511808.3557241
[2] ISAC – Instance-Specific Algorithm Configuration.
https://www.researchgate.net/publication/220837402_ISAC_-_Instance-Specific_Algorithm_Configuration
[3] Efficient Model Selection for Time Series Forecasting via LLMs.
https://arxiv.org/abs/2504.02119
封面图:RDNE Stock Project、pexels.com


















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











