






一、论文简介
https://github.com/microsoft/graphrag
该论文介绍了一种基于图的检索增强生成(Graph RAG)方法,用于针对私有文本语料库进行问题回答。这种方法结合了大语言模型(LLM)和图索引,通过创建一个实体知识图并生成社区摘要,以应对全局性问题。传统的RAG方法在面对整个文本语料库的全局性问题时表现不佳,而该方法通过图索引和社区检测来克服这一挑战。
二、方法
流程
论文提出的Graph RAG方法包含以下步骤:
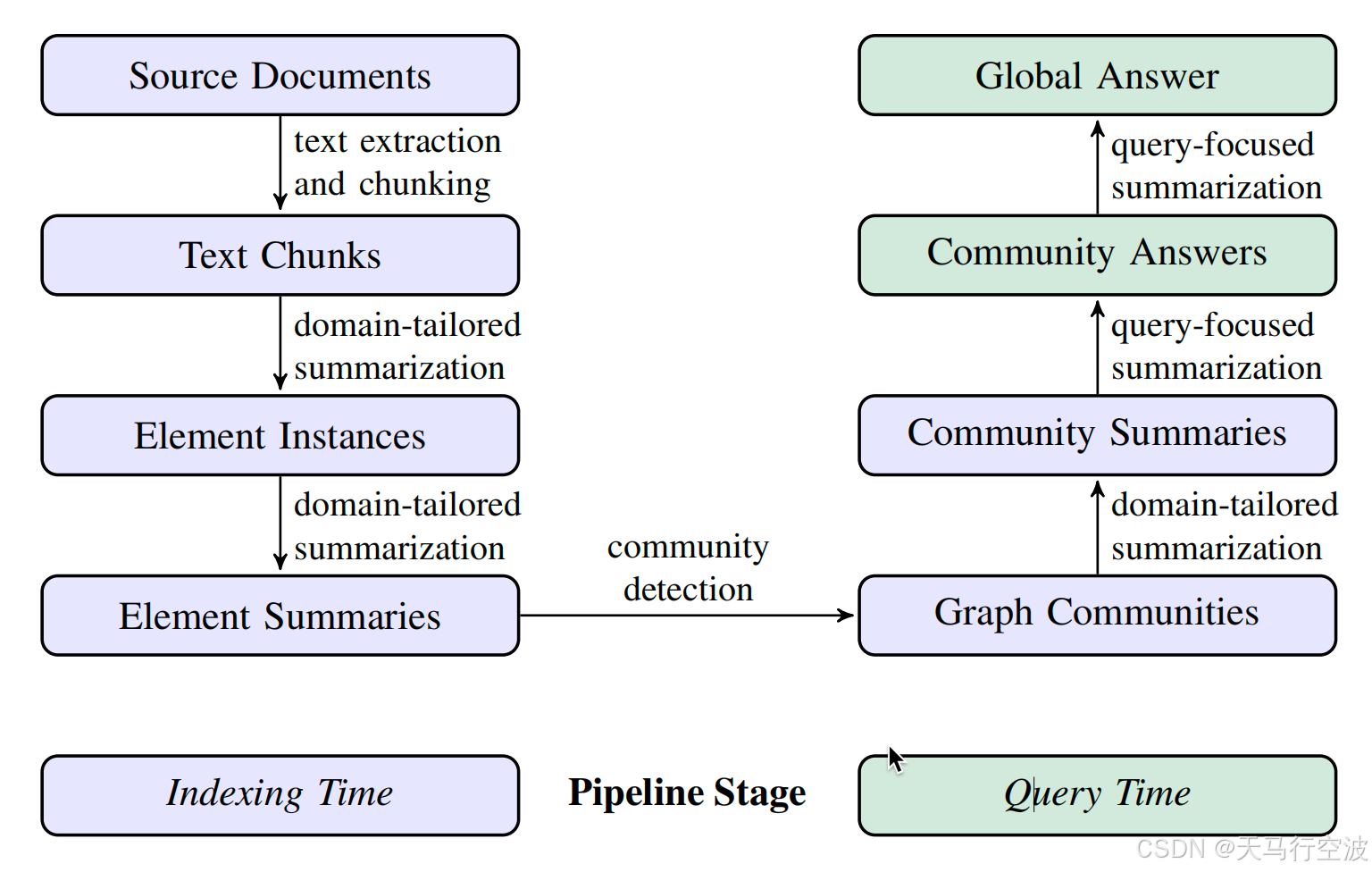
索引阶段
-
文本提取和分块:将源文档分割成较小的文本块。
-
元素实例化:使用LLM提取文本块中的实体及其关系,并生成描述。
-
元素摘要:将相同实体的描述汇总成单个摘要。
-
社区检测:使用Leiden算法将图分割成多个社区。
-
社区摘要:对每个社区生成报告式的摘要。
查询阶段
循环检测实体
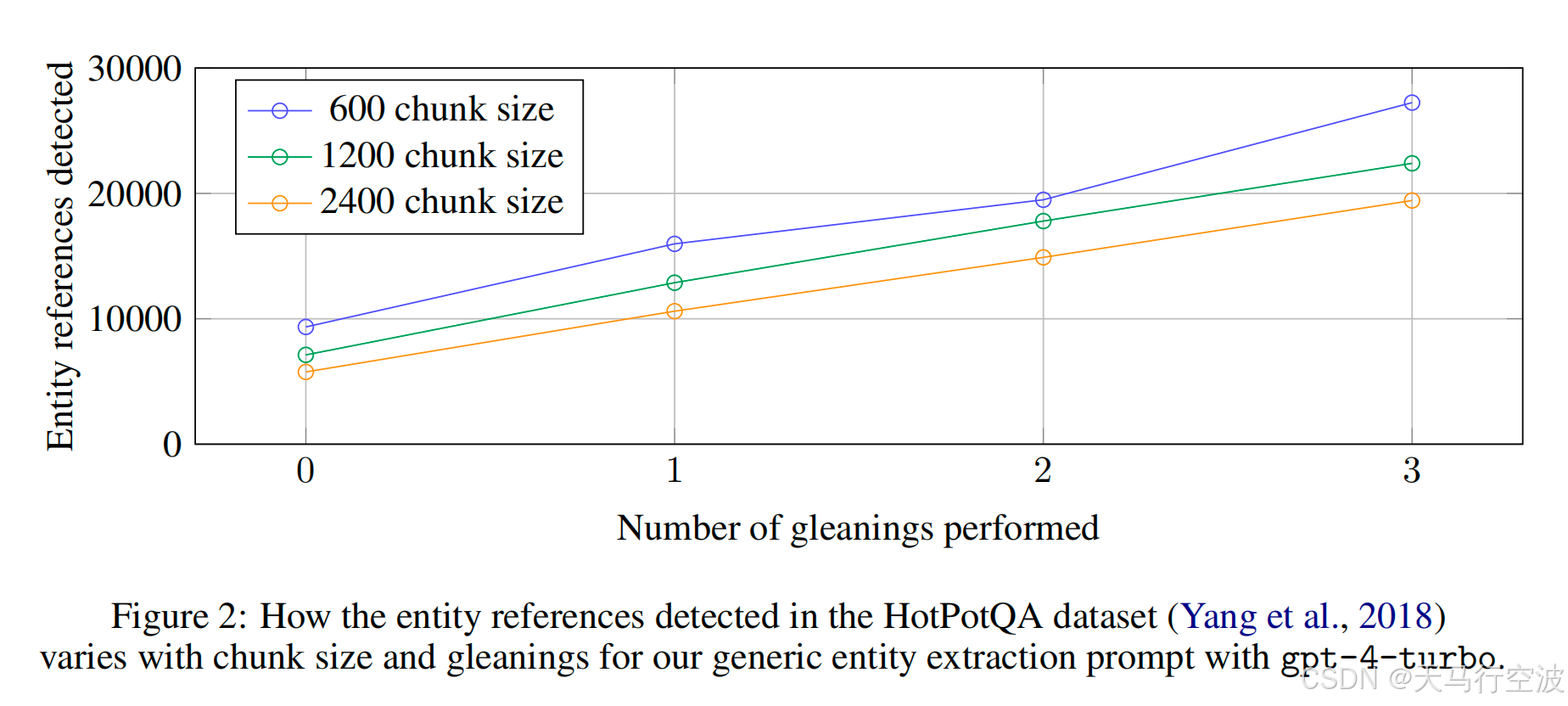
在相同的收集次数下,原始文档被切分 chunk size 越小,实体检测到的引用会越多。虽然一般来说引用越多越好,但任何提取过程都需要平衡任务的召回率和准确度。
Leiden算法
Leiden算法是一种聚类算法,可以将类似的数据点分组到一起形成簇。它基于模块化最大化原理,试图找到一个最优的分割,使得分割后的子图内部密度较大,子图之间联系较小。与传统的聚类算法相比,Leiden算法更适用于处理大规模高维数据。

三、代码实现
Graph RAG的实现是开源的,并且提供了Python版本。论文提供了详细的实现步骤和参数设置,接下来我们一步一步来看源码。中间有很多字段映射 ,数据组装,数据排序,数据筛选,数据聚合,数据压缩、解压缩的流程就不展开细讲,主要讲大的实现过程中的核心代码。由于代码长度过长,部分代码进行了缩减为一行,如需看源码可以直接点击对应步骤代码上方对应的源码链接查看。
https://aka.ms/graphrag
https://github.com/microsoft/graphrag
3.1 文本切分
根据 token 切分源文档
文本切分就是将一段长文本对象分割成多个较小的文本块,并确保这些文本块之间有一定的重叠,这个流程比较通用。当然tokens_per_chun、chunk_overlap的选择也会不同程度的影响效果。
def split_text_on_tokens(*, text: str, tokenizer: Tokenizer) -> list[str]:
"""Split incoming text and return chunks using tokenizer."""
splits: list[str] = []
input_ids = tokenizer.encode(text)
start_idx = 0
cur_idx = min(start_idx + tokenizer.tokens_per_chunk, len(input_ids))
chunk_ids = input_ids[start_idx:cur_idx]
while start_idx < len(input_ids):
splits.append(tokenizer.decode(chunk_ids))
# tokens_per_chunk: 每个块的最大 token 数量
# chunk_overlap: 块之间的重叠 token 数量
# 考虑到块之间的重叠
start_idx += tokenizer.tokens_per_chunk - tokenizer.chunk_overlap
cur_idx = min(start_idx + tokenizer.tokens_per_chunk, len(input_ids))
chunk_ids = input_ids[start_idx:cur_idx]
return splits
3.2 实体和关系提取
每条 chunk 提取元素
元素实例化主要依靠 提取元素 prompt 模版 利用大模型来提取对应的实体以及实体间关系,再使用循环提取模板和判断是否继续模板 来确保能最大化收集对应数据。具体模板已经贴在下面
async def _process_document(
self, text: str, prompt_variables: dict[str, str]
) -> str:
# 提取元素
response = await self._llm(self._extraction_prompt, variables={**prompt_variables, self._input_text_key: text,},)
results = response.output or ""
# 重复收集
for i in range(self._max_gleanings):
glean_response = await self._llm(CONTINUE_PROMPT, name=f"extract-continuation-{i}", history=response.history or [],)
results += glean_response.output or ""
# 达到最大次数停止
if i >= self._max_gleanings - 1:
break
continuation = await self._llm(LOOP_PROMPT, name=f"extract-loopcheck-{i}", history=glean_response.history or [], model_parameters=self._loop_args,)
# 大模型认为没有遗漏,停止
if continuation.output != "YES":
break
return results
创建图
主要步骤:
- 初始化图。
- 遍历结果并分割记录,处理每条记录,分割记录属性。
- 根据属性更新或创建实体节点、关系。
- 返回构建的图。
async def _process_results(self, results: dict[int, str], tuple_delimiter: str, record_delimiter: str,) -> nx.Graph:
"""Parse the result string to create an undirected unipartite graph.
"""
graph = nx.Graph()
for source_doc_id, extracted_data in results.items():
records = [r.strip() for r in extracted_data.split(record_delimiter)]
for record in records:
# 遍历结果并分割记录
record = re.sub(r"^\(|\)$", "", record.strip())
record_attributes = record.split(tuple_delimiter)
if record_attributes[0] == '"entity"' and len(record_attributes) >= 4:
# 将此实体作为节点添加到图中
entity_name = clean_str(record_attributes[1].upper())
entity_type = clean_str(record_attributes[2].upper())
entity_description = clean_str(record_attributes[3])
if entity_name in graph.nodes():
# 实体节点存在 实体节点内容拼接
node = graph.nodes[entity_name]
if self._join_descriptions:
node["description"] = "\n".join(list({*_unpack_descriptions(node), entity_description,}))
else:
if len(entity_description) > len(node["description"]):
node["description"] = entity_description
node["source_id"] = ", ".join(list({*_unpack_source_ids(node), str(source_doc_id),}))
node["entity_type"] = (entity_type if entity_type != "" else node["entity_type"])
else: # 实体节点不存在 创建实体节点
graph.add_node(entity_name, type=entity_type, description=entity_description, source_id=str(source_doc_id),)
if (record_attributes[0] == '"relationship"' and len(record_attributes) >= 5):
# 将此关系作为边添加到图中
source = clean_str(record_attributes[1].upper())
target = clean_str(record_attributes[2].upper())
edge_description = clean_str(record_attributes[3])
edge_source_id = clean_str(str(source_doc_id))
weight = (float(record_attributes[-1]) if isinstance(record_attributes[-1], numbers.Number) else 1.0)
if source not in graph.nodes(): # 源实体节点不存在 创建实体节点
graph.add_node(source, type="", description="", source_id=edge_source_id,)
if target not in graph.nodes(): # 目标实体节点不存在 创建实体节点
graph.add_node(target, type="", description="", source_id=edge_source_id,)
if graph.has_edge(source, target): # 存在关系 添加关系权重和描述
edge_data = graph.get_edge_data(source, target)
if edge_data is not None:
weight += edge_data["weight"]
if self._join_descriptions:
edge_description = "\n".join(list({*_unpack_descriptions(edge_data), edge_description,}))
edge_source_id = ", ".join(list({*_unpack_source_ids(edge_data), str(source_doc_id),}))
# 不存在关系 添加关系边
graph.add_edge(source, target, weight=weight, description=edge_description, source_id=edge_source_id,)
return graph
3.3 元素摘要
汇总节点、边的描述
主要步骤:
- 加载图对象。
- 计算并初始化进度条。
- 为每个节点和边创建异步任务,汇总其描述。
- 并发运行异步任务,并等待完成。
- 更新图对象的节点和边的描述。
- 返回包含图描述总结的对象。
async def get_resolved_entities(row, semaphore: asyncio.Semaphore):
graph: nx.Graph = load_graph(cast(str | nx.Graph, getattr(row, column)))
# 计算进度条长度
ticker_length = len(graph.nodes) + len(graph.edges)
# 初始化进度条
ticker = progress_ticker(callbacks.progress, ticker_length)
# 创建异步任务汇总节点、边的描述
futures = [do_summarize_descriptions(node, sorted(set(graph.nodes[node].get("description", "").split("\n"))), ticker, semaphore,) for node in graph.nodes()]
futures += [do_summarize_descriptions(edge, sorted(set(graph.edges[edge].get("description", "").split("\n"))), ticker, semaphore,) for edge in graph.edges()]
results = await asyncio.gather(*futures)
# 更新图对象的描述
for result in results:
graph_item = result.items
if isinstance(graph_item, str) and graph_item in graph.nodes():
graph.nodes[graph_item]["description"] = result.description
elif isinstance(graph_item, tuple) and graph_item in graph.edges():
graph.edges[graph_item]["description"] = result.description
return DescriptionSummarizeRow(graph="\n".join(nx.generate_graphml(graph)))
汇总描述
主要步骤:
- 初始化变量,计算可用 token 数量。
- 迭代描述,计算每个描述的 token 数量,并收集描述。
- 如果可用的 token 数量不足或已处理完所有描述,调用 _summarize_descriptions_with_llm 方法进行汇总。
- 返回最终的汇总结果。
async def _summarize_descriptions(self, items: str | tuple[str, str], descriptions: list[str]) -> str:
"""Summarize descriptions into a single description."""
sorted_items = sorted(items) if isinstance(items, list) else items
# 对描述进行迭代,添加所有描述,直到达到 _max_input_tokens 为止
usable_tokens = self._max_input_tokens - num_tokens_from_string(self._summarization_prompt)
descriptions_collected = []
result = ""
for i, description in enumerate(descriptions):
usable_tokens -= num_tokens_from_string(description)
descriptions_collected.append(description)
# 如果缓冲区已满,或已添加所有说明,则进行汇总
if (usable_tokens < 0 and len(descriptions_collected) > 1) or (i == len(descriptions) - 1):
# 使用大模型进行汇总
result = await self._summarize_descriptions_with_llm(sorted_items, descriptions_collected)
# 下一轮循环 重置参数 descriptions_collected、usable_tokens
if i != len(descriptions) - 1:
descriptions_collected = [result]
usable_tokens = (self._max_input_tokens - num_tokens_from_string(self._summarization_prompt) - num_tokens_from_string(result))
return result
async def _summarize_descriptions_with_llm(self, items: str | tuple[str, str] | list[str], descriptions: list[str]):
"""Summarize descriptions using the LLM."""
response = await self._llm(
self._summarization_prompt,
name="summarize",
variables={
self._entity_name_key: json.dumps(items),
self._input_descriptions_key: json.dumps(sorted(descriptions)),
},
model_parameters={"max_tokens": self._max_summary_length},
)
# Calculate result
return str(response.output)
3.4 社区检测
分层聚类
对图进行分层聚类,并输出相应的聚类结果。
def cluster_graph(input: VerbInput, callbacks: VerbCallbacks, strategy: dict[str, Any], column: str, to: str, level_to: str | None = None, **_kwargs,) -> TableContainer:
"""
Apply a hierarchical clustering algorithm to a graph. The graph is expected to be in graphml format. The verb outputs a new column containing the clustered graph, and a new column containing the level of the graph.
"""
output_df = cast(pd.DataFrame, input.get_input())
# 应用分层聚类算法 返回 (level, cluster_id, nodes) 的 list
results = output_df[column].apply(lambda graph: run_layout(strategy, graph))
community_map_to = "communities"
output_df[community_map_to] = results
# 提取聚类层次
level_to = level_to or f"{to}_level"
output_df[level_to] = output_df.apply(lambda x: list({level for level, _, _ in x[community_map_to]}), axis=1)
output_df[to] = [None] * len(output_df)
num_total = len(output_df)
# 生成新的图数据 并将其存储在 graph_level_pairs_column 列表中
graph_level_pairs_column: list[list[tuple[int, str]]] = []
for _, row in progress_iterable(output_df.iterrows(), callbacks.progress, num_total):
levels = row[level_to]
graph_level_pairs: list[tuple[int, str]] = []
# 获取每个 level 的图表,并将其添加到列表中
for level in levels:
graph = "\n".join(nx.generate_graphml(apply_clustering(cast(str, row[column]), cast(Communities, row[community_map_to]), level,)))
graph_level_pairs.append((level, graph))
graph_level_pairs_column.append(graph_level_pairs)
output_df[to] = graph_level_pairs_column
# 将 (level, graph) 列表分解成不同的行
output_df = output_df.explode(to, ignore_index=True)
# 将 (level, graph) 列表分解成不同的列
output_df[[level_to, to]] = pd.DataFrame(output_df[to].tolist(), index=output_df.index)
# 清理 community_map_to
output_df.drop(columns=[community_map_to], inplace=True)
return TableContainer(table=output_df)
上面 run_layout 的实际执行代码
def run(graph: nx.Graph, args: dict[str, Any]) -> dict[int, dict[str, list[str]]]:
"""Run method definition."""
max_cluster_size = args.get("max_cluster_size", 10)
use_lcc = args.get("use_lcc", True)
if args.get("verbose", False):
log.info("Running leiden with max_cluster_size=%s, lcc=%s", max_cluster_size, use_lcc)
node_id_to_community_map = _compute_leiden_communities(graph=graph, max_cluster_size=max_cluster_size, use_lcc=use_lcc, seed=args.get("seed", 0xDEADBEEF),)
levels = args.get("levels")
# 如果不传 levels,则全部使用
if levels is None:
levels = sorted(node_id_to_community_map.keys())
# 将对应 level 的社区 映射到一个 list 里
results_by_level: dict[int, dict[str, list[str]]] = {}
for level in levels:
result = {}
results_by_level[level] = result
for node_id, raw_community_id in node_id_to_community_map[level].items():
community_id = str(raw_community_id)
if community_id not in result:
result[community_id] = []
result[community_id].append(node_id)
return results_by_level
执行实际的 Leiden 聚类算法
def _compute_leiden_communities(graph: nx.Graph | nx.DiGraph, max_cluster_size: int, use_lcc: bool, seed=0xDEADBEEF,) -> dict[int, dict[str, int]]:
"""Return Leiden root communities."""
if use_lcc: # 提取图的最大连通子图
graph = stable_largest_connected_component(graph)
# 使用 hierarchical_leiden 进行聚类
community_mapping = hierarchical_leiden(graph, max_cluster_size=max_cluster_size, random_seed=seed)
results: dict[int, dict[str, int]] = {}
# 生成节点到社区的映射 node_id_to_community_map
for partition in community_mapping:
results[partition.level] = results.get(partition.level, {})
results[partition.level][partition.node] = partition.cluster
return results
3.5 embedding
text_embedding
将多个文本块(chunks)通过大模型(llm)embedding 为向量,并返回所有结果的列表
async def _execute(llm: EmbeddingLLM, chunks: list[list[str]], tick: ProgressTicker, semaphore: asyncio.Semaphore,) -> list[list[float]]:
async def embed(chunk: list[str]):
async with semaphore:
# 调用大模型 embedding 文本转向量
chunk_embeddings = await llm(chunk)
result = np.array(chunk_embeddings.output)
tick(1)
return result
# 每个 chunk 都执行 embedding
futures = [embed(chunk) for chunk in chunks]
results = await asyncio.gather(*futures)
# 将结果合并为单个列表(减少收集维度)
return [item for sublist in results for item in sublist]
embed_graph
将 graphml 格式的图数据 embedding 到向量空间中,并将这些向量存储在 output_df 的新列中
async def embed_graph(input: VerbInput, callbacks: VerbCallbacks, strategy: dict[str, Any], column: str, to: str, **kwargs,) -> TableContainer:
"""
Embed a graph into a vector space. The graph is expected to be in graphml format. The verb outputs a new column containing a mapping between node_id and vector.
"""
output_df = cast(pd.DataFrame, input.get_input())
strategy_type = strategy.get("type", EmbedGraphStrategyType.node2vec)
strategy_args = {**strategy}
async def run_strategy(row):
return run_embeddings(strategy_type, cast(Any, row[column]), strategy_args)
results = await derive_from_rows(output_df, run_strategy, callbacks=callbacks, num_threads=kwargs.get("num_threads", None),)
output_df[to] = list(results)
return TableContainer(table=output_df)
3.6 社区报告
CommunityReportsExtractor
通过调用大模型提取每个社区对应的报告
async def __call__(self, inputs: dict[str, Any]):
output = None
try:
response = (
await self._llm(
self._extraction_prompt,
json=True,
name="create_community_report",
variables={self._input_text_key: inputs[self._input_text_key]},
is_response_valid=lambda x: dict_has_keys_with_types(x, [("title", str), ("summary", str), ("findings", list), ("rating", float), ("rating_explanation", str),],),
model_parameters={"max_tokens": self._max_report_length},
)
or {}
)
output = response.json or {}
except Exception as e:
log.exception("error generating community report")
self._on_error(e, traceback.format_exc(), None)
output = {}
text_output = self._get_text_output(output)
return CommunityReportsResult(structured_output=output, output=text_output)
3.7 检索
global search
整体代码
为每批社区简短摘要生成答案,合并中间答案,生成最终答案
async def asearch(self, query: str, conversation_history: ConversationHistory | None = None, **kwargs: Any,) -> GlobalSearchResult:
"""
Perform a global search.
"""
# Step 1: 为每批社区简短摘要生成答案
start_time = time.time()
context_chunks, context_records = self.context_builder.build_context(conversation_history=conversation_history, **self.context_builder_params)
if self.callbacks:
for callback in self.callbacks:
callback.on_map_response_start(context_chunks)
map_responses = await asyncio.gather(*[
self._map_response_single_batch(context_data=data, query=query, **self.map_llm_params)
for data in context_chunks
])
if self.callbacks:
for callback in self.callbacks:
callback.on_map_response_end(map_responses)
map_llm_calls = sum(response.llm_calls for response in map_responses)
map_prompt_tokens = sum(response.prompt_tokens for response in map_responses)
# Step 2: 合并中间答案,生成最终答案
reduce_response = await self._reduce_response(
map_responses=map_responses,
query=query,
**self.reduce_llm_params,
)
return GlobalSearchResult(response=reduce_response.response, context_data=context_records, context_text=context_chunks, map_responses=map_responses, reduce_context_data=reduce_response.context_data, reduce_context_text=reduce_response.context_text, completion_time=time.time() - start_time, llm_calls=map_llm_calls + reduce_response.llm_calls, prompt_tokens=map_prompt_tokens + reduce_response.prompt_tokens)
对每个过滤后的社区进行大模型调用生成答案
async def _map_response_single_batch(self, context_data: str, query: str, **llm_kwargs,) -> SearchResult:
"""Generate answer for a single chunk of community reports."""
start_time = time.time()
search_prompt = ""
try:
search_prompt = self.map_system_prompt.format(context_data=context_data)
search_messages = [{"role": "system", "content": search_prompt}, {"role": "user", "content": query}]
async with self.semaphore:
search_response = await self.llm.agenerate(messages=search_messages, streaming=False, **llm_kwargs)
log.info("Map response: %s", search_response)
try:
processed_response = self.parse_search_response(search_response)
except ValueError:
processed_response = []
return SearchResult(response=processed_response, context_data=context_data, context_text=context_data, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
except Exception:
log.exception("Exception in _map_response_single_batch")
return SearchResult(response=[{"answer": "", "score": 0}], context_data=context_data, context_text=context_data, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
将多个批次中获得的中间响应汇总成一个最终的回答,并返回一个包含该回答和相关元数据的 SearchResult 对象
async def _reduce_response(self, map_responses: list[SearchResult], query: str, **llm_kwargs,) -> SearchResult:
"""Combine all intermediate responses from single batches into a final answer to the user query."""
text_data = ""
search_prompt = ""
start_time = time.time()
try:
# 将所有关键点收集到一个列表中,为排序做准备
key_points = []
for index, response in enumerate(map_responses):
if not isinstance(response.response, list):
continue
for element in response.response:
if not isinstance(element, dict):
continue
if "answer" not in element or "score" not in element:
continue
key_points.append({"analyst": index, "answer": element["answer"], "score": element["score"]})
# 去掉得分为 0 的回复
filtered_key_points = [point for point in key_points if point["score"] > 0]
if len(filtered_key_points) == 0 and not self.allow_general_knowledge:
# 如果没有找到关键点,就不返回数据答案
return SearchResult(response=NO_DATA_ANSWER, context_data="", context_text="", completion_time=time.time() - start_time, llm_calls=0, prompt_tokens=0)
# 得分从高到低排序
filtered_key_points = sorted(filtered_key_points, key=lambda x: x["score"], reverse=True)
data = []
total_tokens = 0
for point in filtered_key_points:
# 格式化响应数据
formatted_response_data = []
formatted_response_data.append(f'----Analyst {point["analyst"] + 1}----')
formatted_response_data.append(f'Importance Score: {point["score"]}')
formatted_response_data.append(point["answer"])
formatted_response_text = "\n".join(formatted_response_data)
if (total_tokens + num_tokens(formatted_response_text, self.token_encoder) > self.max_data_tokens):
break
data.append(formatted_response_text)
total_tokens += num_tokens(formatted_response_text, self.token_encoder)
text_data = "\n\n".join(data)
# 生成 search_prompt 并调用 LLM
search_prompt = self.reduce_system_prompt.format(report_data=text_data, response_type=self.response_type)
if self.allow_general_knowledge:
search_prompt += "\n" + self.general_knowledge_inclusion_prompt
search_messages = [{"role": "system", "content": search_prompt}, {"role": "user", "content": query}]
search_response = await self.llm.agenerate(search_messages, streaming=True, callbacks=self.callbacks, **llm_kwargs)
return SearchResult(response=search_response, context_data=text_data, context_text=text_data, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
except Exception:
log.exception("Exception in reduce_response")
return SearchResult(response="", context_data=text_data, context_text=text_data, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
local search
整体代码
根据 query embedding 查询相似实体,构建上下文,生成提示,调用语言模型生成响应
def search(self, query: str, conversation_history: ConversationHistory | None = None, **kwargs,) -> SearchResult:
"""Build local search context that fits a single context window and generate answer for the user question."""
start_time = time.time()
search_prompt = ""
context_text, context_records = self.context_builder.build_context(query=query, conversation_history=conversation_history, **kwargs, **self.context_builder_params)
log.info("GENERATE ANSWER: %d. QUERY: %s", start_time, query)
try:
search_prompt = self.system_prompt.format(context_data=context_text, response_type=self.response_type)
search_messages = [{"role": "system", "content": search_prompt}, {"role": "user", "content": query}]
response = self.llm.generate(messages=search_messages, streaming=True, callbacks=self.callbacks, **self.llm_params)
return SearchResult(response=response, context_data=context_records, context_text=context_text, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
except Exception:
log.exception("Exception in _map_response_single_batch")
return SearchResult(response="", context_data=context_records, context_text=context_text, completion_time=time.time() - start_time, llm_calls=1, prompt_tokens=num_tokens(search_prompt, self.token_encoder))
根据查询文本的语义相似性搜索实体。如果未提供查询文本,则默认返回排名前的实体。然后,它排除指定需要排除的实体,并确保结果中包含指定需要包含的实体。
def map_query_to_entities(query: str, text_embedding_vectorstore: BaseVectorStore, text_embedder: BaseTextEmbedding, all_entities: list[Entity], embedding_vectorstore_key: str = EntityVectorStoreKey.ID, include_entity_names: list[str] | None = None, exclude_entity_names: list[str] | None = None, k: int = 10, oversample_scaler: int = 2,) -> list[Entity]:
"""利用查询和实体描述的文本 embedding 的语义相似性,提取与给定查询相匹配的实体。"""
if include_entity_names is None:
include_entity_names = []
if exclude_entity_names is None:
exclude_entity_names = []
matched_entities = []
if query != "":
# 获取与查询语义相似度最高的实体,对排除在外的实体进行超量抽样
search_results = text_embedding_vectorstore.similarity_search_by_text(text=query, text_embedder=lambda t: text_embedder.embed(t), k=k * oversample_scaler,)
for result in search_results:
matched = get_entity_by_key(entities=all_entities, key=embedding_vectorstore_key, value=result.document.id,)
if matched:
matched_entities.append(matched)
else: # 默认返回排名前的实体
all_entities.sort(key=lambda x: x.rank if x.rank else 0, reverse=True)
matched_entities = all_entities[:k]
# 过滤掉排除在外的实体
if exclude_entity_names:
matched_entities = [entity for entity in matched_entities if entity.title not in exclude_entity_names]
# 在 include_entity 列表中添加实体
included_entities = []
for entity_name in include_entity_names:
included_entities.extend(get_entity_by_name(all_entities, entity_name))
return included_entities + matched_entities
def build_context(self, query: str, conversation_history: ConversationHistory | None = None, include_entity_names: list[str] | None = None, exclude_entity_names: list[str] | None = None, conversation_history_max_turns: int | None = 5, conversation_history_user_turns_only: bool = True, max_tokens: int = 8000, text_unit_prop: float = 0.5, community_prop: float = 0.25, top_k_mapped_entities: int = 10, top_k_relationships: int = 10, include_community_rank: bool = False, include_entity_rank: bool = False, rank_description: str = "number of relationships", include_relationship_weight: bool = False, relationship_ranking_attribute: str = "rank", return_candidate_context: bool = False, use_community_summary: bool = False, min_community_rank: int = 0, community_context_name: str = "Reports", column_delimiter: str = "|", **kwargs: dict[str, Any],) -> tuple[str | list[str], dict[str, pd.DataFrame]]:
"""
为本地搜索提示建立数据上下文。
"""
# map user query to entities
if conversation_history:
pre_user_questions = "\n".join(conversation_history.get_user_turns(conversation_history_max_turns))
query = f"{query}\n{pre_user_questions}"
selected_entities = map_query_to_entities(query=query, text_embedding_vectorstore=self.entity_text_embeddings, text_embedder=self.text_embedder, all_entities=list(self.entities.values()), embedding_vectorstore_key=self.embedding_vectorstore_key, include_entity_names=include_entity_names, exclude_entity_names=exclude_entity_names, k=top_k_mapped_entities, oversample_scaler=2,)
final_context = list[str]()
final_context_data = dict[str, pd.DataFrame]()
# 构建社区上下文
community_tokens = max(int(max_tokens * community_prop), 0)
community_context, community_context_data = self._build_community_context(selected_entities=selected_entities, max_tokens=community_tokens, use_community_summary=use_community_summary, column_delimiter=column_delimiter, include_community_rank=include_community_rank, min_community_rank=min_community_rank, return_candidate_context=return_candidate_context, context_name=community_context_name,)
if community_context.strip() != "":
final_context.append(community_context)
final_context_data = {**final_context_data, **community_context_data}
# 构建本地上下文
local_prop = 1 - community_prop - text_unit_prop
local_tokens = max(int(max_tokens * local_prop), 0)
local_context, local_context_data = self._build_local_context(selected_entities=selected_entities, max_tokens=local_tokens, include_entity_rank=include_entity_rank, rank_description=rank_description, include_relationship_weight=include_relationship_weight, top_k_relationships=top_k_relationships, relationship_ranking_attribute=relationship_ranking_attribute, return_candidate_context=return_candidate_context, column_delimiter=column_delimiter,)
if local_context.strip() != "":
final_context.append(str(local_context))
final_context_data = {**final_context_data, **local_context_data}
# 构建文本单元上下文
text_unit_tokens = max(int(max_tokens * text_unit_prop), 0)
text_unit_context, text_unit_context_data = self._build_text_unit_context(selected_entities=selected_entities, max_tokens=text_unit_tokens, return_candidate_context=return_candidate_context,)
if text_unit_context.strip() != "":
final_context.append(text_unit_context)
final_context_data = {**final_context_data, **text_unit_context_data}
return ("\n\n".join(final_context), final_context_data)
四、成果和结果
通过对两个真实世界数据集(播客转录和新闻文章)的测试,Graph RAG方法在全面性和多样性方面相较于传统的RAG方法有显著提升。具体成果包括:
全面性和多样性
Graph RAG在提供答案的全面性和多样性方面优于传统RAG方法,尤其是在处理包含百万级别词汇的数据集。
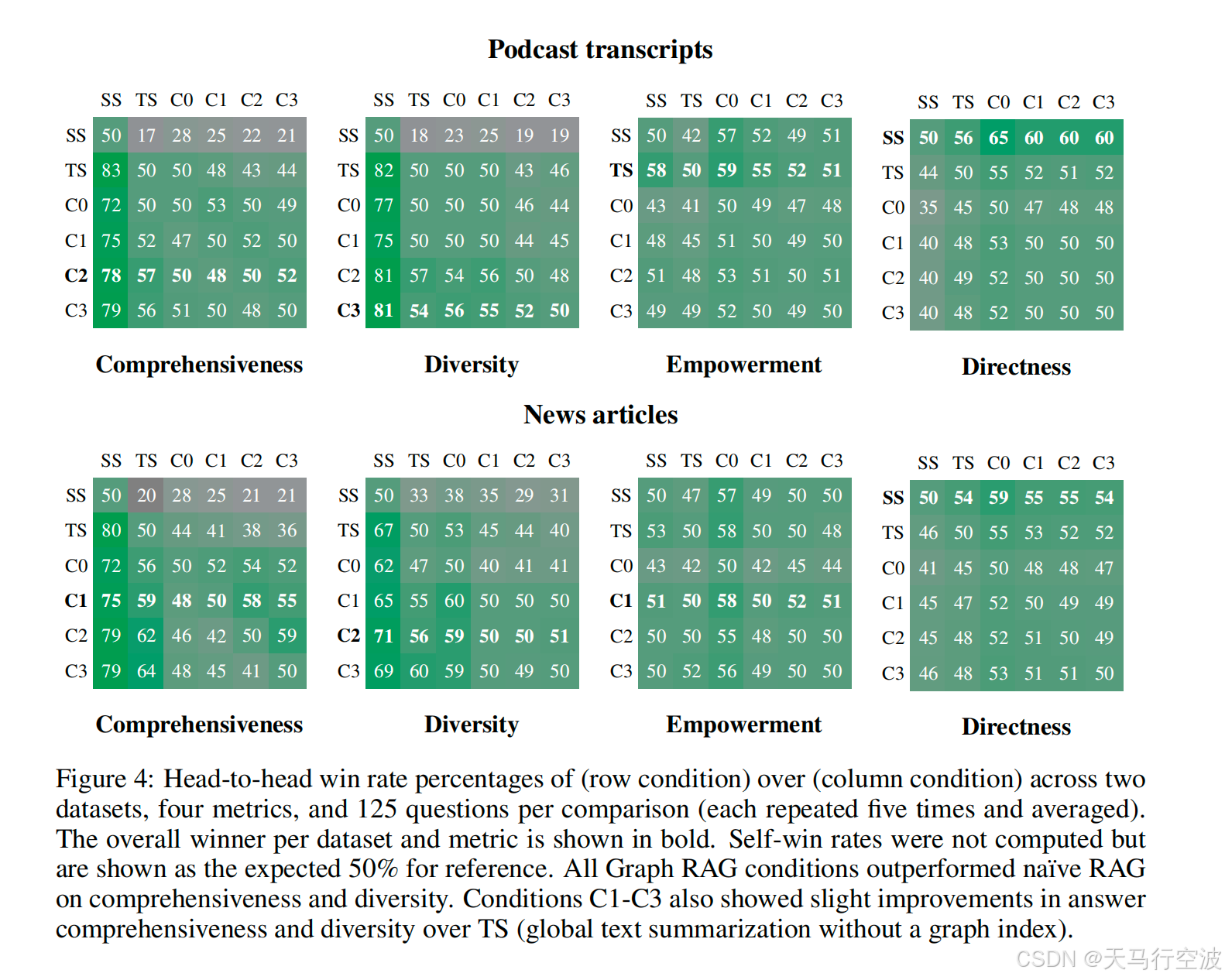
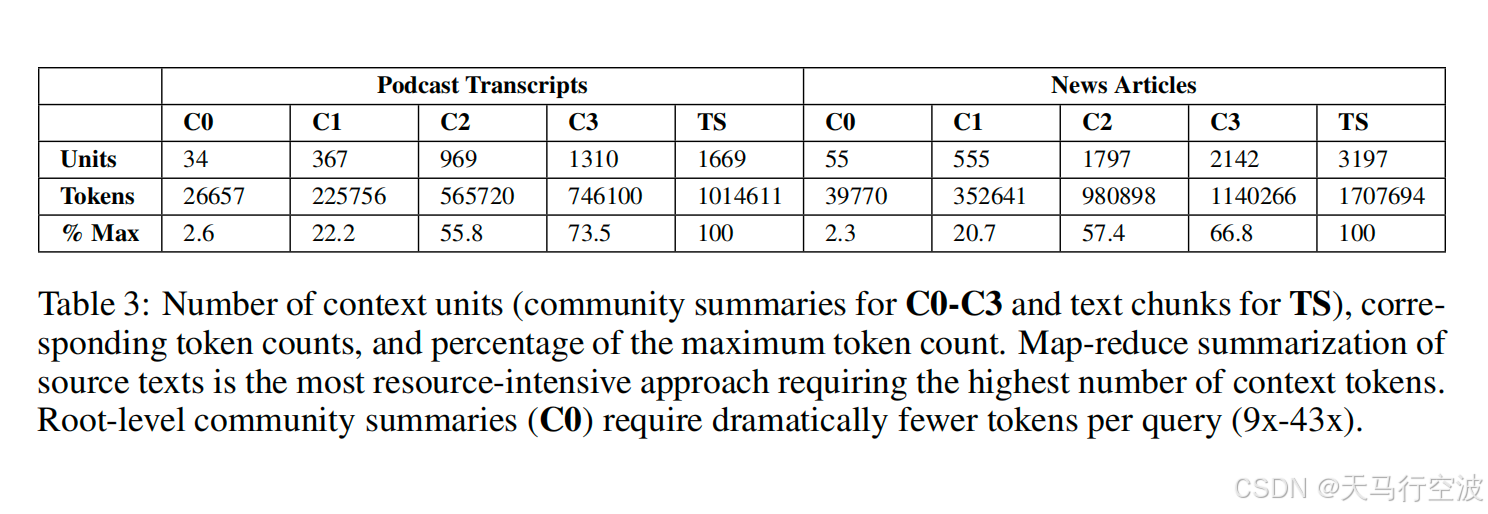
成本效益
与直接的文本摘要方法相比,Graph RAG在相同指标下的token消耗更低。
实验通过生成多种问题来评估Graph RAG的性能,涉及理解技术领导者对政策和法规的看法、新闻文章中健康和保健的主题等。结果表明,Graph RAG在处理广泛问题方面具有显著优势,尤其是在复杂和多样化的数据集上。
五、应用场景
- 社交媒体网络分析,如识别兴趣小组或朋友圈;
- 网络生物学研究,如在蛋白质相互作用网络中寻找功能模块;
- 信息检索,用于在文档网络中找到主题聚类;
- 甚至在网络路由优化、城市规划等领域也有潜在应用。
六、结论
这篇论文提出的Graph RAG方法通过结合图索引和LLM,提供了一种有效的方式来处理全局性问题,总结文本语料库。这种方法在全面性、多样性和成本效益方面展示了显著优势,为未来的大规模数据处理和信息提取提供了新思路。



















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











