




大语言模型的词语生成机制:Logits、Softmax 与Sampling详解
大型语言模型(LLM)即使面对相同的提示,也能产生多样、富有创意且有时令人惊讶的输出。这种随机性不是bug,而是模型从概率分布中采样下一个标记的核心特性。本文将解析关键采样策略,并展示温度、top-k 和 top-p 等参数如何影响一致性与创造力之间的平衡。

在本教程中,我们将采用实践方式来理解:
- 对数如何变成概率
- 温度、top-k 和 top-p 抽样的工作原理
- 不同采样策略如何影响模型的下一个token分布
到最后,你会理解LLM推理背后的机制,并能够调整输出的创造力或确定性。
我们开始吧。
概述
本文分为四个部分;它们是:
- Logits如何转换为概率
- Temperature温度
- Top-k 抽样
- Top-p 抽样
对数如何成为概率
当你向LLM提问时,它会输出一个logit向量。Logit是模型为词汇中每个可能的下一个词组分配的原始分数。
如果模型的词汇表为𝑉它会输出一个向量𝑉每个下一个词的位置。logit是一个真实的数字。它通过softmax函数转换为概率:
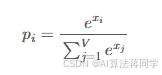
其中𝑥我是令牌的logit我以及𝑝我是对应的概率。Softmax将这些原始分数转换为概率分布。全部𝑝我为正数,且它们的和为1。
假设我们给模型这个提示:
今天的天气真___
模型将词汇中的每个词都视为可能的下一个词。为了简化,假设词汇中只有6个标记:
wonderful cloudy nice hot gloomy delicious
模型为每个令牌生成一个logit。以下是模型可能输出的对数示例集以及基于softmax函数的相应概率:
| Token | Logit | Probability |
|---|---|---|
| wonderful | 1.2 | 0.0457 |
| cloudy | 2.0 | 0.1017 |
| nice | 3.5 | 0.4556 |
| hot | 3.0 | 0.2764 |
| gloomy | 1.8 | 0.0832 |
| delicious | 1.0 | 0.0374 |
你可以用PyTorch的softmax函数来确认:
import torch
import torch.nn.functional as F
vocab = ["wonderful", "cloudy", "nice", "hot", "gloomy", "delicious"]
logits = torch.tensor([1.2, 2.0, 3.5, 3.0, 1.8, 1.0])
probs = F.softmax(logits, dim=-1)
print(probs)
# Output:
# tensor([0.0457, 0.1017, 0.4556, 0.2764, 0.0832, 0.0374])
基于此结果,概率最高的代币为“好”。大型语言模型并不总是选择概率最高的令牌;相反,它们从概率分布中抽样,每次都产生不同的输出。在这种情况下,看到“漂亮”的概率是46%。
如果你想让模型给出更有创意的答案,如何改变概率分布,使得“阴云”、“高温”等答案也更频繁地出现?
温度
温度(𝑇)是一个模型推理参数。它不是一个模型参数;它是生成输出的算法中的一个参数。它在应用 softmax 前先对 logit 进行扩展:
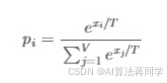
你可以预期概率分布会更具确定性,如果𝑇 <1,因为 各值之间的差值𝑥我会被夸大。另一方面,如果𝑇 >1,作为每个值的差值𝑥我将被降低。
现在,让我们可视化温度对概率分布的影响:
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
vocab = ["wonderful", "cloudy", "nice", "hot", "gloomy", "delicious"]
logits = torch.tensor([1.2, 2.0, 3.5, 3.0, 1.8, 1.0]) # (vocab_size,)
scores = logits.unsqueeze(0) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











