






首先导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
from sklearn.manifold import TSNE
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics.cluster import fowlkes_mallows_score
1.读取该数据集seeds_dataset.txt,以\t+为分隔符
seeds = pd.read_csv('seeds_dataset.txt',header = None,sep="\t+",engine='python')
#print(seeds)
2.将数据的前7列作为待分析数据data,第7列target
seeds = pd.read_csv('seeds_dataset.txt',header = None,sep="\t+",engine='python')
#print(seeds)
3.对数据集进行离差标准化处理
seeds_data = seeds.values[1:210, 0:7]
seeds_target = seeds.values[1:, 7]
seeds_names = seeds.values[1, 0:7]
scale = MinMaxScaler().fit(seeds_data)
seeds_dataScale = scale.transform(seeds_data)
#print("执行标准差标准化后的数据:\t", seeds_dataScale)
4.利用Kmeans对数据进行聚类分析
要求聚为3类,k=2,3,4,设置三组不同的k值
k_values = [3]
#修改了k_values为4的时候,自定义初始化中心点记得要变成一个四行的矩阵,为5的时候要变成五行的矩阵
# 设置三组不同的初始中心点,我们定义了三个不同的k值(3、4、5)和三种不同的初始中心点策略(随机选择、k-means++和自定义初始中心点)
init_methods = ['random', 'k-means++', np.array([[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7],
[0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
[0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]])]
seeds = np.array(seeds)
for i in range(1, 210):
for j in range(0, 7):
seeds[i, j] = np.float64(seeds[i, j])
# kmeans = KMeans(n_clusters=3, random_state=123).fit(seeds_dataScale)
for k in k_values:
for init_method in init_methods:
# 运行K均值聚类算法
kmeans = KMeans(n_clusters=k, init=init_method, random_state=123).fit(seeds_dataScale)
# 输出聚类结果和评价指标,init_method三种初始化中心点策略
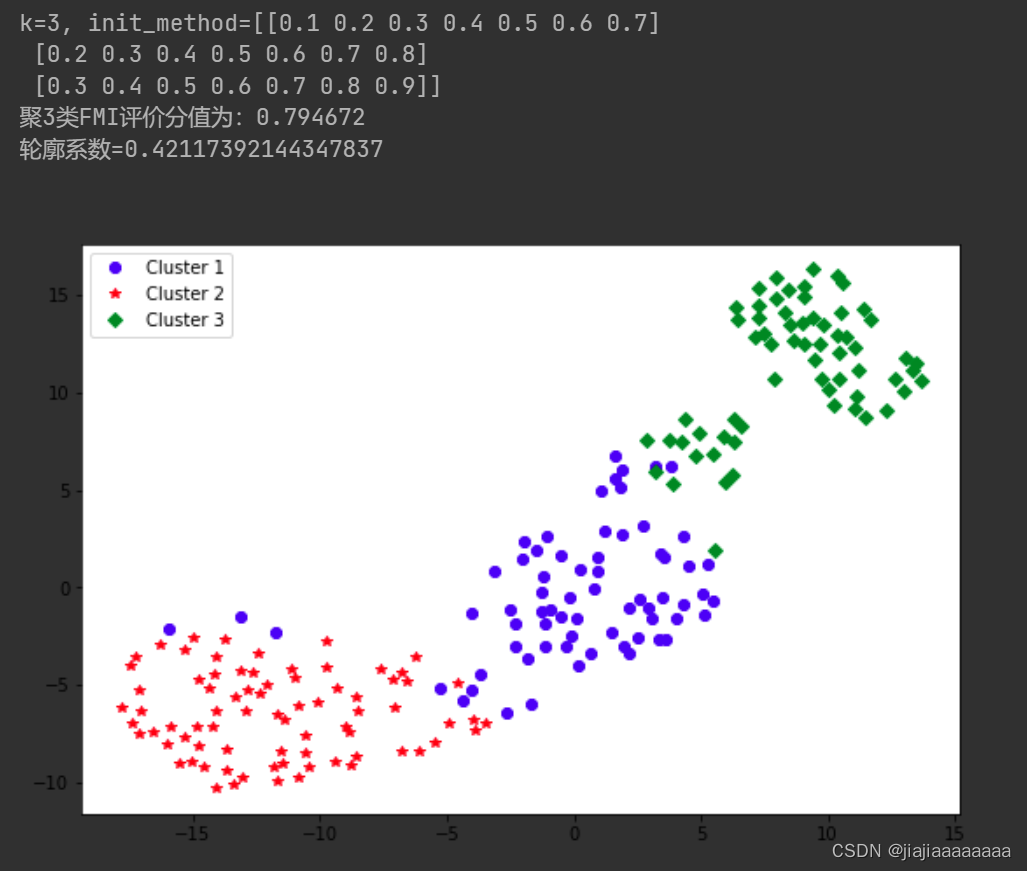
print(f"k={k}, init_method={init_method}")
score = fowlkes_mallows_score(seeds_target, kmeans.labels_)
print('聚%d类FMI评价分值为:%f' % (k, score))
print("轮廓系数={}".format(metrics.silhouette_score(seeds_dataScale, kmeans.labels_, metric='euclidean')))
# 使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2, init='random', random_state=123).fit(seeds_data)
df = pd.DataFrame(tsne.embedding_) # 将原始数据转换为DataFrame
df['labels'] = kmeans.labels_ # 将聚类结果存储进df数据表
# 提取不同标签的数据
#修改了k_values为4的时候,要定义到df4,同理为5的时候要定义到df5
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
# 绘制图形
fig = plt.figure(figsize=(9, 6)) # 设定空白画布,并制定大小
# 用不同的颜色表示不同数据
#修改了k_values为4的时候,记得多加一个图形
plt.plot(df1[0], df1[1], 'bo', label='Cluster 1')
plt.plot(df2[0], df2[1], 'r*', label='Cluster 2')
plt.plot(df3[0], df3[1], 'gD', label='Cluster 3')
plt.legend()
plt.show() # 显示图片
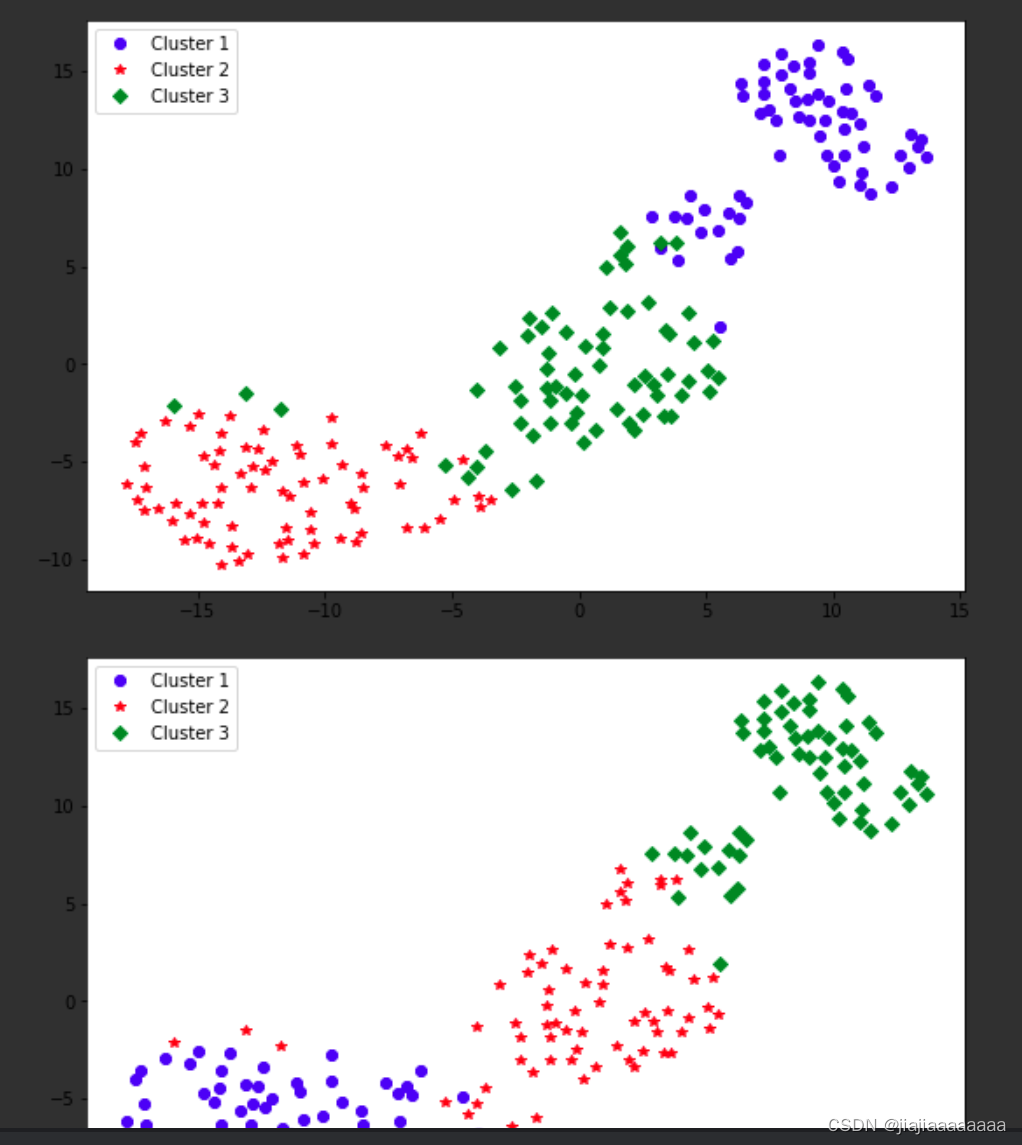
结果展示,只展示了k=3的结果

















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









