







Abstract:
领域泛化(DG)本质上是一个分布外问题,旨在将从多个源领域学习到的知识泛化到一个未知的目标领域。主流是利用统计模型来建模数据和标签之间的依赖关系,旨在学习独立于域的表示。然而,统计模型是对现实的表面描述,因为它们只需要对依赖性而不是内在的因果机制进行建模。当相关性随目标分布而变化时,统计模型可能无法推广。在这方面,我们引入了一个一般的结构因果模型来形式化DG问题。具体来说,我们假设每个输入都是由因果因素(其与标签的关系在各个领域都是不变的)和非因果因素(类别独立的)的混合构成的,只有前者才能引起分类判断。我们的目标是从输入中提取因果因素,然后重建不变的因果机制。然而,理论上的想法是远离实际ofDG,因为所需的因果/非因果因素是不可观察的。我们强调,理想的因果因素应该满足三个基本属性:与非因果因素分离,共同独立,因果关系足以分类。在此基础上,我们提出了一种因果启发表示学习(CIRL)算法,该算法强制表示满足上述性质,然后使用它们来模拟因果因素,从而提高泛化能力。在几个广泛使用的数据集上的实验结果验证了该方法的有效性.
1.introduction
近年来,随着真实的世界中任务复杂性的不断提高,基于独立同分布的深度神经网络面临着严重的out-of-distribution (OOD)问题。假设[23,24,30]。将在源域上训练的模型直接应用于具有不同分布的看不见的目标域通常会遭受灾难性的性能下降[13,29,31,57]。为了解决领域迁移问题,领域泛化(DG)引起了越来越多的关注,其目的是将从多个源领域提取的知识推广到一个看不见的目标领域[2,20,22,35]。
为了提高泛化能力,已经提出了许多DG方法,这些方法可以大致分为不变表示学习[9,22,25,34],域增强[53,59,63,66],元学习[2,6,21]等。这些努力只是试图弥补OOD数据所造成的问题,并对数据和标签之间的统计依赖性进行建模,而没有解释潜在的因果机制。最近有人认为[43],这种做法可能是不够的,并普遍适用于i.i.d.之外。设定需要学习的不仅仅是变量之间的统计相关性,而是一个潜在的因果模型[3,39,42,43,49,54]。例如,在图像分类任务中,很可能所有的长颈鹿都在草地上,表现出和草地有高度的统计依赖性,当背景在目标域中变化时,这很容易误导模型做出错误的预测。毕竟长颈鹿的头部、颈部等特征,把背景换成长颈鹿。
在本文中,我们引入了结构因果模型(SCM)[48]来形式化DG问题,旨在挖掘数据和标签之间的内在因果机制,并实现更好的泛化能力。具体地说,我们假设数据中与类别相关的信息是因果因子,而且数据和标签的关系与域无关,例如,数字识别中的“形状”。而与类别无关的信息被假定为非因果因素,这通常是领域相关的信息,例如,数字识别中的“手写体风格”。(我的理解:用奶酪体和楷书去写数字,奶酪体和楷书是手写体风格,是和域有关系的非因果信息,数字的分类不会因为什么字体改变分类,这个是因果的。)
每个原始数据X都是由因果因素S和非因果因素U的混合构成的,只有前者对类别标签Y产生因果影响,如图1所示。我们的目标是从原始输入X中提取因果因子S,然后重建不变的因果机制,这可以在因果干预P(Y|do(U),S)的帮助下完成。do-operator do(do)[10]表示对变量的干预。不幸的是,我们不能直接将原始输入分解为X = f(S,U),因为因果/非因果因素通常是不可观察的,并且无法用公式表示,这使得因果推理特别具有挑战性[51,55]。
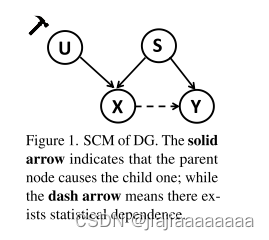
为了将理论思想付诸实践,我们强调因果因子S期望满足三个性质,基于[43,46,49]中的研究:1)与非因果因子U分离; 2)S的因子分解应该是联合独立的; 3)在包含所有因果信息的意义上,因果足以用于分类任务X −→ Y。如图2(a)所示,与U的混合导致S包含潜在的非因果信息,而联合依赖因子分解使S冗余,进一步导致错过一些潜在的因果信息。相反,图2(B)中的因果因素S是满足所有要求的理想因素。受此启发,我们提出了一种因果启发表示学习(CIRL)算法,强制学习的表示具有上述属性,然后利用表示的每个维度来模仿因果因子的因式分解,具有更强的泛化能力。
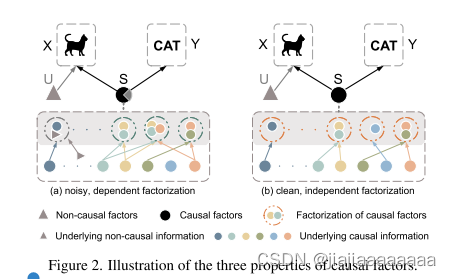
简单地说,对于每个输入,我们首先利用因果干预模块,通过生成具有扰动域相关信息的新数据,将因果因素S与非因果因素U分离。与原始数据相比,生成的数据具有不同的非因果因子U,但具有相同的因果因子S,因此表示被强制保持不变。此外,我们提出了一个因子分解模块,使每个维度的代表联合独立,然后可以用来近似的因果因素。此外,为了在因果关系上足以进行分类,我们设计了一个对抗掩码模块,该模块迭代地检测包含相对较少因果信息的维度,并通过掩码器和表示生成器之间的对抗学习迫使它们包含更多和新颖的因果信息。我们的工作贡献如下:
1)本文指出了仅仅建立统计依赖模型的不足,并引入了基于因果关系的观点来挖掘DG内在的因果机制。·
2)我们强调了理想的因果因子应该具备的三个属性,并提出了一个CIRL算法来学习因果表示,可以模仿因果因子,具有更好的泛化能力。
3)·在几个广泛使用的数据集上的大量实验和分析结果证明了我们方法的有效性和优越性。
2.related work
Domain Generalization (DG)领域泛化(DG)的目的是从多个源领域中提取知识,这些知识可以很好地泛化到未知的目标领域。一个有前途和普遍的解决方案是通过基于内核的优化[8,35],对抗学习[22,25,34],二阶相关[41]或使用变分贝叶斯[62]学习域不变表示来对齐域的分布。数据扩充也是通过丰富源多样性来赋予模型泛化能力的重要技术。在以前的工作中已经探索了几项研究:[53]根据域的变化引起的对抗梯度来扰动图像。[63,66]通过混合特征统计[66]或幅度谱[63]来混合跨域的训练实例的风格。[65]通过最大化发散度量来生成更多的训练合成数据。另一种流行的方法是元学习,它通过将元训练和元测试域从原始源域中划分出来来模拟域转移[2,6,21,26]。其他DG作品也探索了低秩分解[45],次要任务如解决拼图[4]和梯度引导的辍学[14]。与上述方法不同的是,我们从因果关系的角度来处理DG问题。我们的方法侧重于挖掘内在的因果机制,通过学习因果表示,这表现出更好的泛化能力。
Causal Mechanism因果机制[15,40,42]关注的事实是,统计依赖性(“看到人们服药表明他生病了”)不能可靠地预测反事实输入的结果(“停止服药并不能使他健康”)。一般来说,它可以被视为推理链的组成部分[19],为远离观察到的分布的情况提供预测。从这个意义上说,挖掘因果机制意味着获得超越观测数据分布支持的强大知识[50]。在过去的几年里,因果关系和泛化之间的联系越来越受到关注[33,43]。已经提出了许多基于因果关系的方法来获得不变的因果机制[12,56,61]或恢复因果特征[5,10,27,47],从而提高OOD的泛化能力。值得注意的是,它们通常依赖于因果图或结构方程上的限制性假设。最近,MatchDG [32]通过对比学习强制跨域输入具有相同的表示,如果它们来自同一对象,则将因果关系引入DG文献。(这里读起来怎么这么拗口,我的理解是:通过对比不同领域的输入数据,强制使它们具有相同的表示。这种方法旨在通过对比学习来学习领域间的不变表示。)我们的CIRL与MatchDG在学习因果表示方面的努力有关。然而,CIRL的不同之处在于,它是明确地利用维度表示来模仿基于理论公式的因果因素,并且只依赖于更一般的因果结构模型而没有限制性假设。本质上,CIRL可以被视为具有干预的因果因子分解,这与对象条件MatchDG明显不同。
3.method
在本节中,我们从因果关系的角度考虑DG,并使用图1所示的一般结构因果模型。我们证明了,内在的因果机制(形式化为条件分布)可以是可行的,如果因果因素是给定的。然而,正如[1]中所讨论的,很难准确地恢复因果因素,因为它们是不可观测的。因此,我们建议学习因果表示的基础上的因果因素的性质作为一个模仿,同时继承的上级泛化能力。
全是公式,看原文
3.1. DG from the Causal View从因果的角度看DG
DG的主流侧重于对观测输入和相应标签之间的统计依赖性进行建模,即,P(X,Y),假设跨域变量。为了获得不变的依赖性,它们通常强制分布在边缘或有条件地是域不变的,即,最小化P(X)或P(X |Y)中跨域的差距。然而,由于统计依赖性不能解释输入和标签之间的内在因果机制,它往往会随领域而变化。因此,源域之间的学习不变依赖可能仍然会在看不见的目标域上失败。同时,因果机制通常在不同领域保持稳定[43]。正如赖兴巴赫[46]在Principle 1中所主张的那样,我们首先阐明了因果关系和统计依赖性之间的联系。
Principle 1([46])。Common Cause Principle共同原因原则:如果两个可观测量X和Y在统计上是相关的,那么存在一个变量S,它因果地影响这两个变量,并在以S为条件时使它们独立的意义上解释了所有的相关性。
Principle 2:独立因果机制(ICM)原则:每个变量在给定其原因的情况下的条件分布(即,它的机制)并不通知或影响其他机制。
(全是公式推导,自己想看就去看原文吧)
3.2.Causality Inspired Representation Learning因果关系启发的表示学习
在本节中,我们将展示我们提出的表示学习算法,该算法受到上述因果关系的启发,由三个模块组成:因果干预模块,因果因子分解模块和对抗掩码模块。整个框架如图3所示。
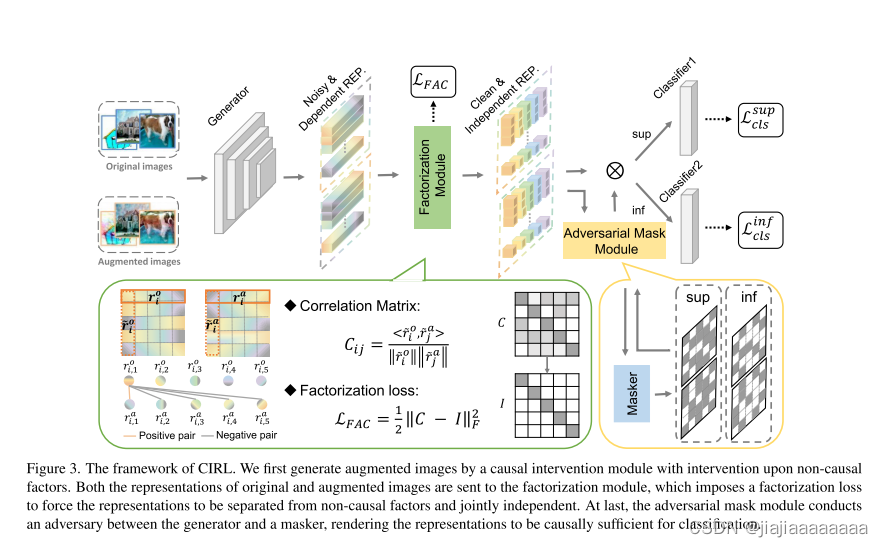
3.2.1 Causal Intervention Module因果干预模块
我们的目标首先是通过因果干预将因果因素S从非因果因素U的混合物中分离出来。具体地,尽管等式100中的因果因子提取器g(f)的显式形式是(2)是未知的,我们有先验知识,因果因素S应该保持不变的干预U,即,P(S|do(U))。而在DG文献中,我们确实知道一些领域相关信息不能确定输入的类别,这些信息可以被视为非因果因素并通过一些技术捕获[63,65,66]。例如,傅立叶变换具有众所周知的特性:傅立叶频谱的相位分量保留原始信号的高级语义,而幅度分量包含低级统计数据[38,44]。(傅立叶变换的相位部分包含的是高层次的语义信息,而振幅部分包含的是低层次的统计信息)因此,我们通过干扰幅度信息同时保持相位信息不变来对U进行干预,如[63]所做的那样。形式上,给定原始输入图像x0,其傅立叶变换可以公式化为:


(通过扰动数据的傅立叶变换的振幅部分,来实现对非因果变量的干预,并使干预前后的图像的表征ro和ra保持一致。)
3.2.2 Causal Factorization Module因果分解模块
正如我们在SEC3.1中提出的因果因子s1,s2的分解..,sN应该是共同独立的,在这个意义上,他们都不需要其他的信息。因此,我们打算使表示的任何两个维度彼此独立:
公式8
注意,为了节省计算成本,我们省略了Ro或Ra内的约束。为了统一Eq.(7)和等式(8),我们建立相关矩阵C:
公式9
其中,<n>表示内积运算。因此,Ro和Ra的相同维度可以被视为需要最大化相关性的正对,而不同维度可以被视为需要最小化相关性的负对。在此基础上,我们设计了一个因子分解损失LFac,其公式如下:
公式10

remark1 :
Eq中的目标。(10)可以使相关矩阵C的对角元素近似为1,这意味着对非因果因素干预前后的表示是不变的。这表明,我们可以有效地分离的因果因素的混合物的非因果因素。此外,它还使C的非对角元素接近于0,即,强制表示的维度共同独立。因此,通过最小化LFac,我们可以使噪声和相关表示成为干净和独立的表示,满足理想因果因子的前两个属性。
3.2.3 Adversarial Mask Module对抗掩码模块
为了成功完成分类任务X −→ Y,表征应该是因果充分的,包含了所有的支持信息。最直接的方法是在多个源域中使用监督标签y:

其中,kh是分类器。然而,这种直接的方式不能保证我们学习的表征的每个维度都是重要的,即,包含足够的潜在因果信息进行分类。具体而言,可能存在携带相对较少因果信息的次维度,然后对分类做出较小贡献。因此,我们建议检测这些维度并强制它们做出更多贡献。由于维度也需要在我们的因子分解模块的帮助下联合独立,因此检测到的次维度被渲染为包含其他维度不包含的更多和新颖的因果信息,这使得整个表示更加充分。
因此,为了检测下维,我们设计了一个对抗掩码模块。我们建立了一个基于神经网络的掩蔽器,用masker w表示,以学习每个维度的贡献,并且对应于最大κ ∈(0,1)比率的维度被视为上级维度,而其余维度被视为下级维度:
公式12
其中,我们采用常用的可导出GumbelSoftmax技巧[16]来对κN值接近1的掩码进行采样。这个戏法的细节留待补充材料来解释.通过将学习的表示乘以获得的masks m和 1−m,我们可以分别获得表示的上级和低级维度。然后,我们将它们馈送到两个不同的分类器h 1,h 2。式子(11)可以重写如下:

我们通过最小化L_sup_cls和最大化L_inf_cls来优化掩蔽器,同时通过最小化两个监督损失来优化生成器blog和分类器h_blog 1,h_blog 2。
remark2.所提出的对抗掩码模块可以精确地检测低维,因为1)对于基于现有掩码维度来最小化L inf cls的优化的掩码h2,学习选择用于最大化L inf cls的维度可以找到具有较少贡献的低维,以及2)上级和下级维度集彼此互补,使得如果一个维度不被视为上级,则它将被视为下级。因此,对上级的选择将有助于对低级的选择。此外,与优化Eq.(11)只有与我们的因果因子分解模块相结合的对抗掩码模块才能帮助生成因果关系更充分的表示,因为通过优化blog以最小化L inf cls和LFac,下级维度被迫携带更多的因果信息,并且与现有的上级维度无关。最后,通过迭代地“替换”低级表示为新的上级表示,学习到的表示将接近因果充分。
优化目标如下:

其中τ是权衡参数。请注意,在推理期间使用整个表示r和分类器rnh1。
remark3.请注意,特征尺寸的数量的影响可以忽略不计。通过这三个模块的协同优化,包含在整个表示中的因果信息的总量将增加,直到学习的表示可以解释输入和标签之间的所有统计依赖性,而不管特征维度如何。补充材料中提供了实验分析,以验证我们的论证。
4.Experiment
4.1 数据集
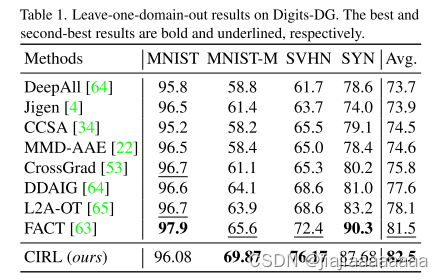
遵循常用的leave-one-domain-out协议[20],我们将一个域指定为用于评估的看不见的目标域,并使用其余域进行训练。

















 2654
2654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









