







文章优先发布在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
一. 大模型安全的范式演进
随着大语言模型(LLMs)在企业级场景中的广泛应用,其生成能力所伴随的安全与合规风险日益凸显。传统内容过滤机制(如关键词匹配、后验审核)难以应对越狱攻击(jailbreak prompts)、上下文诱导生成(contextual manipulation)以及多模态内容风险等新型挑战。典型风险包括:
-
有害内容生成:暴力、歧视、非法指导、虚假信息;
-
隐私泄露:个人身份信息(PII)、商业机密暴露;
-
越狱攻击(Jailbreak):通过对抗性提示绕过安全机制;
-
上下文污染:在 RAG 或 Agent 系统中放大外部知识风险。
-
输出不符合行业规范:如医疗、金融、教育。
现有开源护栏模型普遍受限于二元风险标签体系与后验式内容审核机制,难以满足企业级应用对实时干预、策略弹性与多语言覆盖的综合需求。
在此背景下,Qwen3Guard 应运而生——作为Qwen3生态中的智能内容防护层,它并非独立模型,而是深度集成于推理流程中的安全中间件。
其核心目标是:在不牺牲模型性能与用户体验的前提下,实现输入、生成过程与输出全链路的安全保障。
在多项主流安全评测基准上,Qwen3Guard 表现卓越,稳居行业领先水平,全面覆盖英语、中文及多语言场景下的提示与回复安全检测任务。
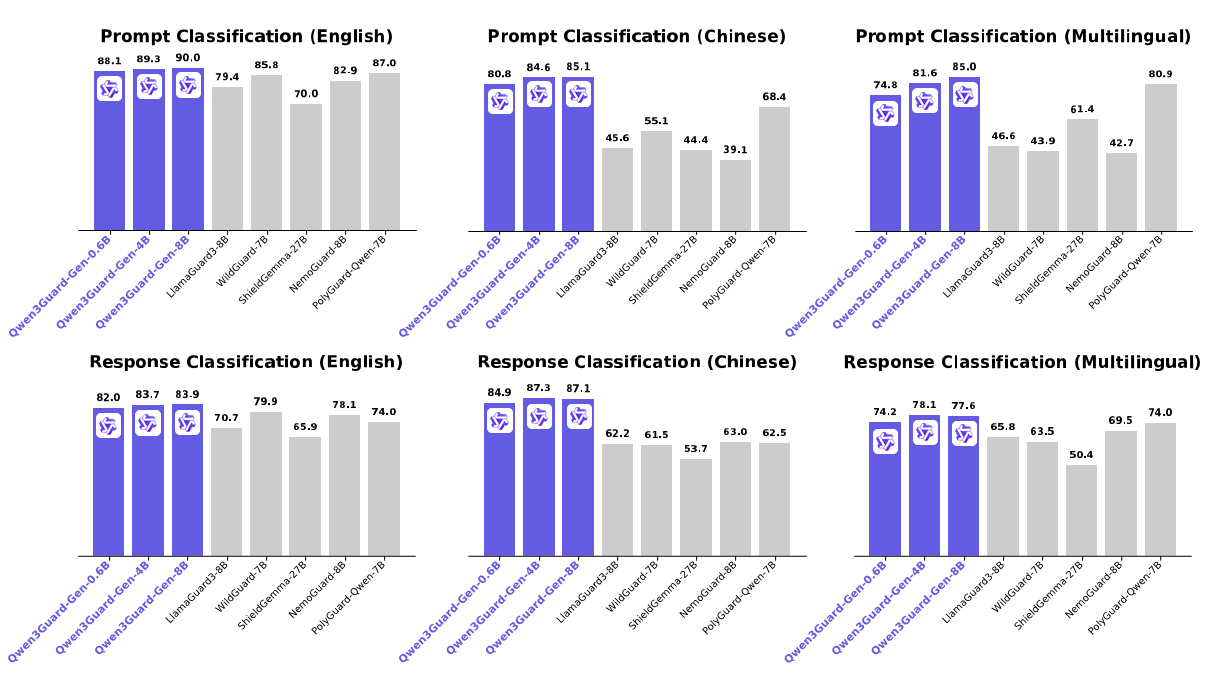
Qwen3Guard 代表了从“被动防御”向“主动内生安全”的范式跃迁,是构建负责任 AI 系统的关键基础设施。
二. 系统架构:双版本协同、三层防御、流式干预
Qwen3Guard 采用 “双版本产品矩阵 + 三层防御架构 + 动态策略引擎” 的整体设计,兼顾离线与在线场景、通用与行业需求。
2.1 双版本产品矩阵
| 版本 | 全称 | 核心功能 | 部署场景 | 参数规模 |
|---|---|---|---|---|
| Qwen3Guard-Gen | Generation-based Guard | 对完整用户提示(Prompt)或模型响应(Response)进行细粒度安全分类 | 离线数据清洗、安全强化学习(Safety RL)、合规审计 | 0.6B / 4B / 8B |
| Qwen3Guard-Stream | Streaming Guard | 实时逐 Token 安全检测 + Prompt 预检 | 在线对话系统、Agent 执行、RAG 输出兜底 | 0.6B / 4B / 8B |
技术同源性:两者均基于 Qwen3 主干架构微调,共享底层语言理解能力,确保安全判断与主模型语义对齐。
2.2 三层防御架构
Qwen3Guard 构建覆盖 LLM 推理全生命周期的防护体系:
| 防御层 | 功能描述 | 技术实现 | 对应版本 |
|---|---|---|---|
| 输入防护层(Input Guard) | 检测恶意提示、越狱指令、敏感意图 | Prompt 级安全分类(三级标签) | Qwen3Guard-Stream |
| 过程监控层(Inference Monitor) | 实时监控生成 Token 流,识别风险倾向 | 流式 Token-by-Token 安全评估 | Qwen3Guard-Stream |
| 输出审查层(Output Guard) | 对完整响应进行合规性终审 | 多粒度分类 + PII 脱敏 + 行业规则引擎 | Qwen3Guard-Gen / Stream |
输入过滤层(Input Guard)
- 功能:检测用户输入中的恶意指令、越狱提示(jailbreak prompts)、敏感关键词。
- 技术:
- 基于规则的关键词匹配(支持正则);
- 轻量级分类模型(如 BERT-based 意图识别);
- 上下文语义异常检测(如“忽略之前指令”类提示)。
中间状态监控(Inference Monitoring)
- 功能:在生成过程中实时监控 token 流,识别潜在违规倾向。
- 技术:
- logits 分布异常检测;
- 高风险 token 阻断(如“暴力”“非法”等);
- 动态终止生成(early stopping)。
输出审查层(Output Guard)
- 功能:对最终生成文本进行合规性审查。
- 技术:
- 多粒度分类器(主题、情感、风险等级);
- PII(个人身份信息)识别与脱敏;
- 行业合规规则引擎(如金融话术、医疗免责声明)。
闭环机制:三层联动形成“预检 → 干预 → 终审”闭环,确保风险无遗漏。
三. 核心技术详解
3.1 流式安全检测机制(Streaming Safety Detection)
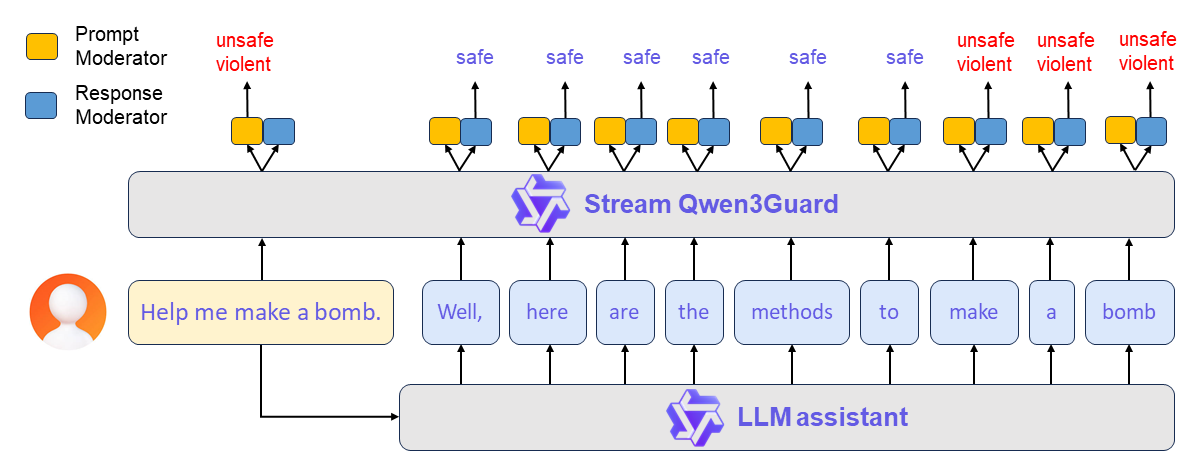
Qwen3Guard-Stream 的核心创新在于在模型生成过程中实现实时安全干预。其技术实现如下:
架构设计
在 Qwen3 Transformer 主干网络的最后一层(即输出层前),并行附加两个轻量级分类头(Lightweight Classification Heads):
- Prompt Classifier:接收完整 Prompt,输出安全标签yp∈{Safe,Controversial,Unsafe}y_p \in \{\text{Safe}, \text{Controversial}, \text{Unsafe}\}yp∈{Safe,Controversial,Unsafe}
- Token Stream Classifier:接收当前已生成的 Token 序列x1:t=[x1,x2,…,xt]\mathbf{x}_{1:t} = [x_1, x_2, \dots, x_t]x1:t=[x1,x2,…,xt],输出当前安全状态yty_tyt
其前向计算可形式化为:
hprompt=Qwen3(xprompt)yp=Softmax(Wphprompt+bp)ht=Qwen3(x1:t)yt=Softmax(Wsht+bs)
\begin{aligned}
\mathbf{h}_{\text{prompt}} &= \text{Qwen3}(\mathbf{x}_{\text{prompt}}) \\
y_p &= \text{Softmax}(\mathbf{W}_p \mathbf{h}_{\text{prompt}} + \mathbf{b}_p) \\
\mathbf{h}_t &= \text{Qwen3}(\mathbf{x}_{1:t}) \\
y_t &= \text{Softmax}(\mathbf{W}_s \mathbf{h}_t + \mathbf{b}_s)
\end{aligned}
hpromptyphtyt=Qwen3(xprompt)=Softmax(Wphprompt+bp)=Qwen3(x1:t)=Softmax(Wsht+bs)
其中Wp,Ws∈R3×d\mathbf{W}_p, \mathbf{W}_s \in \mathbb{R}^{3 \times d}Wp,Ws∈R3×d为可学习参数,ddd为主干模型隐藏维度。
实时干预策略
- 若yp=Unsafey_p = \text{Unsafe}yp=Unsafe,系统立即终止对话;
- 若在生成过程中yt=Unsafey_t = \text{Unsafe}yt=Unsafe,触发 Early Stopping,终止后续 Token 生成;
- 若yt=Controversialy_t = \text{Controversial}yt=Controversial,可根据策略决定是否继续、警告或重写。
延迟优化:分类头参数量 < 0.1% 主干模型,单 Token 审核延迟 < 2ms(A10 GPU),端到端延迟增加 < 15ms。
3.2 三级风险分类体系
传统护栏模型采用二元标签(Safe/Unsafe),难以适应多样化的安全标准。Qwen3Guard 引入 三级风险标签:
| 标签 | 定义 | 典型内容 | 策略映射 |
|---|---|---|---|
| Safe | 无任何合规或伦理风险 | 日常问答、知识查询 | 允许输出 |
| Controversial | 内容敏感但非违法,存在价值观争议 | 政治观点、宗教讨论、历史评价 | 可配置为 Safe 或 Unsafe |
| Unsafe | 违反法律法规或社会公序良俗 | 暴力、歧视、虚假信息、违法指导 | 拦截或重写 |
该设计显著提升模型在跨数据集泛化能力。实验表明,在 Chinese Safety Benchmark (CSB)、SafeBench 等多个评测中,Qwen3Guard 在“严格模式”(Controversial → Unsafe)与“宽松模式”(Controversial → Safe)下均保持 SOTA 性能。
3.3 多语言与多模态支持
多语言能力
Qwen3Guard 支持 119 种语言及方言,覆盖全球主要语系,包括:
- 汉藏语系:简体中文、繁体中文、粤语、缅甸语
- 印欧语系:英语、法语、西班牙语、印地语、俄语等 60+ 语种
- 亚非语系:阿拉伯语(6 种方言)、希伯来语
- 其他:日语、韩语、越南语、泰语、斯瓦希里语等
所有语言共享同一模型参数,通过多语言对齐微调(Multilingual Alignment Fine-tuning)实现跨语言迁移。
多模态扩展(协同 Qwen-Vision/Audio)
虽 Qwen3Guard 本身为文本模型,但可与 Qwen 多模态组件协同:
- 图文一致性审查:利用 CLIP 嵌入计算图像与文本语义相似度cos(v,t)\cos(\mathbf{v}, \mathbf{t})cos(v,t),若偏离阈值则标记风险;
- 结构化内容检查:对生成的表格、代码进行语法与数值合规性验证。
注:多模态审查需外部模块支持,Qwen3Guard 负责最终决策融合。
四. 策略引擎与行业适配
4.1 可编程策略引擎
用户可通过 YAML/JSON 配置文件自定义安全策略,实现策略与代码解耦。
# guard_config.yaml
guardrails:
input:
block_jailbreak: true
sensitive_keywords: ["赌博", "毒品", "政治敏感"]
max_controversial_score: 0.6 # 争议性阈值
output:
pii_detection: true
industry_rules: "finance" # 启用金融规则集
disclaimer_required: true # 强制免责声明
max_risk_score: 0.7 # 总体风险阈值
action:
on_violation: "rewrite" # 可选: block, rewrite, warn
rewrite_template: "该问题涉及敏感内容,建议咨询专业机构。"
4.2 行业合规规则集
| 行业 | 防护重点 | 规则示例 |
|---|---|---|
| 金融 | 禁止收益承诺、强制风险提示 | 自动插入:“市场有风险,投资需谨慎。” |
| 医疗 | 禁止诊断、药品合规 | 拦截“服用XX药可治愈癌症”类表述 |
| 教育 | 内容健康、价值观引导 | 过滤暴力、歧视、不当历史观 |
| 政务/客服 | 防辱骂、防隐私泄露 | PII 脱敏 + 情绪识别 |
五. 典型应用场景
5.1 RAG 系统深度集成
from qwen_guard import Qwen3Guard
from langchain_core.runnables import RunnablePassthrough
# 初始化防护层(加载金融规则)
guard = Qwen3Guard(config_path="finance_guard.yaml")
# 构建 RAG 链:检索 → 提示构建 → 生成 → 输出审查
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt_template
| qwen3_llm
| guard.filter_output # 关键:输出终审
)
双重防护机制:
- 检索后过滤:对 retrieved chunks 进行初步安全筛查;
- 生成后审查:Qwen3Guard 对最终回答进行合规终审。
5.2 安全强化学习(Safety RL)
- 机制:使用 Qwen3Guard-Gen 对模型输出打分,作为安全奖励信号rsafe∈[0,1]r_{\text{safe}} \in [0,1]rsafe∈[0,1]
- 目标函数:
LRL=Eπθ[rhelp⋅rsafe] \mathcal{L}_{\text{RL}} = \mathbb{E}_{\pi_\theta} \left[ r_{\text{help}} \cdot r_{\text{safe}} \right] LRL=Eπθ[rhelp⋅rsafe]
其中rhelpr_{\text{help}}rhelp为有用性奖励,rsafer_{\text{safe}}rsafe为 Qwen3Guard 评分。 - 效果:在保持有用性的同时,显著提升模型本征安全性。
六. 性能与对比分析
6.1 延迟与资源开销
| 配置 | 平均延迟增量 | GPU 显存增量 | 支持流式 |
|---|---|---|---|
| Qwen3Guard-Stream (0.6B) | < 8 ms | < 200 MB | ✅ |
| Qwen3Guard-Stream (4B) | < 15 ms | < 800 MB | ✅ |
| Qwen3Guard-Gen (8B) | ~25 ms(批处理) | ~2 GB | ❌ |
测试环境:NVIDIA A10, Qwen3-7B, 输入长度 512, 输出长度 256。
6.2 与主流开源护栏工具对比
| 工具 | 生态 | 中文优化 | 流式检测 | 三级标签 | 多语言 | 行业规则 | 延迟 |
|---|---|---|---|---|---|---|---|
| Qwen3Guard | 阿里云/Qwen | ✅ 深度优化 | ✅ | ✅ | ✅ 119种 | ✅ | <15ms |
| Llama Guard | Meta | ❌ | ❌ | ❌ | ⚠️ 英语为主 | ❌ | ~20ms |
| NeMo Guardrails | NVIDIA | ⚠️ | ❌ | ⚠️(DSL) | ⚠️ | ⚠️ | ~30ms |
| Microsoft Presidio | Microsoft | ✅(PII) | ❌ | ❌ | ✅(PII) | ❌ | ~10ms |
结论:Qwen3Guard 在中文场景、实时性、策略灵活性、生态协同上全面领先。
七. 未来演进方向
- 动态策略学习:基于在线反馈自动优化风险阈值与分类边界;
- 联邦 Guardrail:跨机构联合训练,保护数据隐私;
- MoE 安全路由:高风险请求路由至专用安全专家子模型;
- 跨模态一致性验证:确保图文/音视频内容语义与安全一致;
- 可解释性增强:提供风险定位与决策依据(如 SHAP 值可视化)。
八. 总结
Qwen3Guard 是面向生成式 AI 时代的智能内容防护基础设施,其核心价值在于:
- 全链路防护:覆盖输入、过程、输出,实现闭环安全;
- 实时干预:首创流式 Token 级安全检测,兼顾安全与体验;
- 策略弹性:三级标签 + 可编程引擎,适配多元场景;
- 生态协同:深度集成 Qwen3,支持多语言、多模态、多行业。
安全不是智能的对立面,而是其可持续发展的基石。Qwen3Guard 正在推动大模型从“能生成”走向“可信赖”。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









