







 IFCNN是一种全卷积的端到端图像融合模型,利用预训练的ResNet101进行特征提取,采用元素融合策略处理多通道输入。论文介绍了网络结构、损失函数、数据集和训练设置,并与多个基线模型进行了比较。
IFCNN是一种全卷积的端到端图像融合模型,利用预训练的ResNet101进行特征提取,采用元素融合策略处理多通道输入。论文介绍了网络结构、损失函数、数据集和训练设置,并与多个基线模型进行了比较。
@article{zhang2020ifcnn,
title={IFCNN: A general image fusion framework based on convolutional neural network},
author={Zhang, Yu and Liu, Yu and Sun, Peng and Yan, Han and Zhao, Xiaolin and Zhang, Li},
journal={Information Fusion},
volume={54},
pages={99–118},
year={2020},
publisher={Elsevier}
}
论文级别:SCI A1
影响因子:18.6
📖
文章目录
📖论文解读
该论文是【基于CNN】的图像融合方法。网络模型是【端到端】,适用于【多类型图像融合任务】,从【多聚焦图像融合】展开。
此外,作者还发布了新的数据集。
🔑关键词
- General image fusion framework 通用图像融合框架
- Convolutional neural network 卷积神经网络
- Large-scale multi-focus image dataset 大规模多聚焦图像数据集
- Better generalization ability 更好的泛化性能
💭核心思想
IFCNN是一个【全卷积】的【端到端】【通用】图像融合模型,模型包括:特征提取、特征融合、特征重构三部分。
- 输入(【多组】【3通道】图像)
- RGB->YCbCr,叠加Y通道3次作为输入
- 单通道图像,直接叠加3次变成3通道
- 特征提取
使用在ImageNet上预训练的ResNet101的第一个卷积层作为特征提取的第一个卷积层,但是因为该卷积层是用于分类任务的,因此添加了第二个卷积层以适应图像融合任务。 - 特征融合
并没有采用concat后再卷积融合的操作,而是使用元素融合规则(元素【最大】、【最小】、【平均】)。前者要求特征输入模块参数个数随输入改变,而元素融合规则不需要,可以融合任意数量的输入图像。本文使用:- 可见光-红外、多聚焦、多模态医学:【元素最大】
- 多曝光:【元素平均】
- 特征重构
因为特征提取结构简单,特征抽象级别不高,所以重构也简单的使用了两层卷积 - 输出
引入了【感知损失】对模型进行正则化,
🪢网络结构
作者提出的网络结构如下图所示。结构很清晰明了。
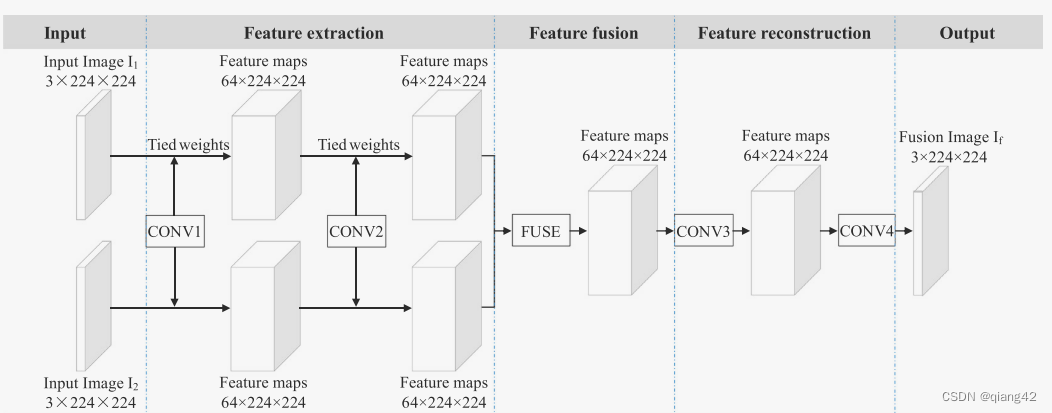
CONV1包含64个7×7的卷积核,步长为1,padding为3。(不需要再训练,直接使用固化的参数)
CONV2包含64个3×3的卷积核,步长为1,padding为1。
在FUSE中,采用了相应任务的元素融合规则,公式如下:
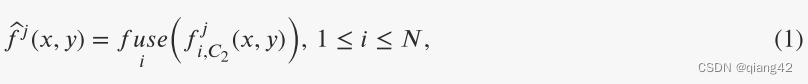
f
i
,
c
2
j
f^j_{i,c_2}
fi,c2j代表了CONV2中,从第i张图像提取的第j个特征图。
f
j
^
\hat {f^j}
fj^代表了融合特征图的第j个通道。
f
u
s
e
fuse
fuse表示元素融合规则。
因为下采样会丢失信息,因此该网络没有进行任何下采样。整个网络中特征图和输入图像尺寸均一致。
CONV3包含64个3×3的卷积核,步长为1,padding为1。
CONV3包含3个1×1的卷积核,目的是为了将64通道的特征图压缩至3通道。
在输入的地方,RGB2YCbCr的公式为:
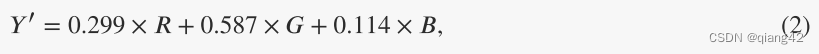
📉损失函数
感知损失由ResNet101最后一个卷积层提取的预测融合图像特征图与标签融合图像的均方误差构成:
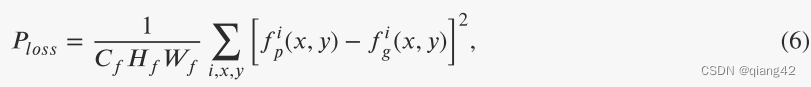
f
p
f_p
fp和
f
g
f_g
fg分别代表预测融合图像的特征图以及融合图像ground truth的特征图,i为特征图的通道索引,
C
f
C_f
Cf、
H
f
H_f
Hf、
W
f
W_f
Wf分别代表特征图的通道数、高、宽。
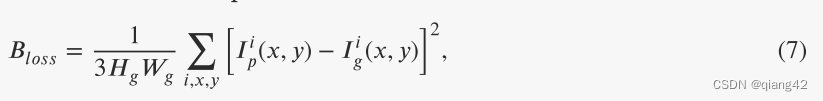
I
p
I_p
Ip和
I
g
I_g
Ig分别代表预测融合图像以及融合图像的ground truth,i为RGB图像通道索引。
H
g
H_g
Hg、
W
g
W_g
Wg分别为融合图像ground truth的高和宽。
总损失如下:

ω
1
\omega_1
ω1和
ω
2
\omega_2
ω2为权重系数,本文设置均为1.
🔢数据集
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置
- 在多聚焦图像数据集上,只用 B l o s s B_loss Bloss预训练5000次,batchsize64
- 冻结BN层参数,采用 T l o s s T_loss Tloss进行60000个epoch精细训练,batchsize32(此步骤计算量较大,所以降低)
🔬实验
📏评价指标
- VIFF
- ISSIM
- NMI
- SF
- AG
参考资料
[图像融合定量指标分析]
🥅Baseline
- GFF,LPSR,MFCNN,MECNN
🔬实验结果






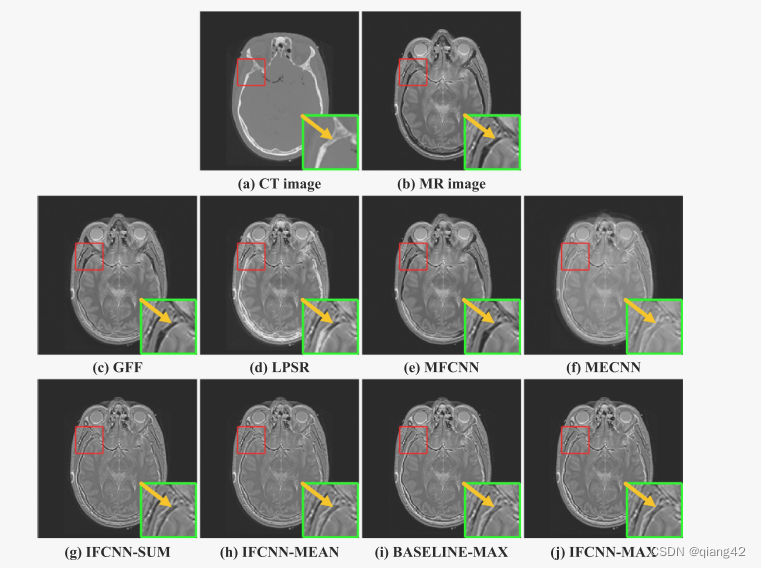
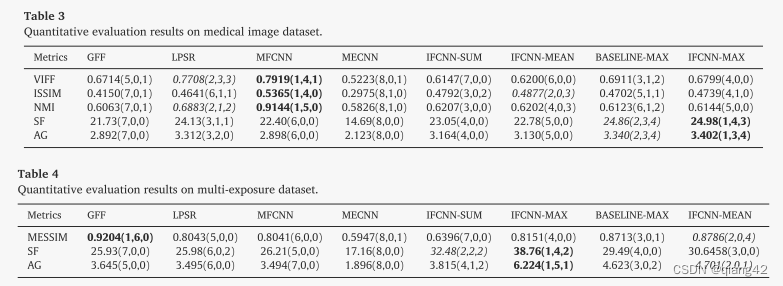

更多实验结果及分析可以查看原文:
📖[论文下载地址]
💽[代码下载地址]
🚀传送门
📑图像融合相关论文阅读笔记
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[Visible and Infrared Image Fusion Using Deep Learning]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📚图像融合论文baseline总结
📑其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~



















 9885
9885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











