







@article{jung2020unsupervised,
title={Unsupervised deep image fusion with structure tensor representations},
author={Jung, Hyungjoo and Kim, Youngjung and Jang, Hyunsung and Ha, Namkoo and Sohn, Kwanghoon},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={3845–3858},
year={2020},
publisher={IEEE}
}
论文级别:SCI AI
影响因子:10.6
文章目录
📖论文解读
早期2020年的一篇CNN-VIF论文。作者提出了一种基于CNN的【轻量级】【通用】图像融合网络DIF-Net
该网络使用CNN完成特征提取、特征融合、图像重建。
使用【多通道图像对比度】的【结构张量】作为损失函数。
该方法适用于任意维度的输入和输出。
一般来说,图像融合里的通用网络指的是可以实现多模态(红外-可见光,医学)、多聚焦、多曝光等图像融合的网络结构,并非某个特定图像融合任务专用的网络结构,具有广泛的适用性。
🔑关键词
Image fusion, image contrast, structure tensor, convolutional neural network, and unsupervised learning.
图像融合,图像对比度,结构张量,卷积神经网络,无监督学习
💭核心思想
网络结构其实就是CNN+ ResBlock,融合使用Concat+卷积,重构和提取一样
主要有趣的地方在作者使用了对比度的结构张量作为损失函数。
🪅相关背景知识
🪅结构张量
令
I
I
I为M通道图像,图像
I
I
I像素(x,y)处的梯度可以用Jacobian矩阵表示:
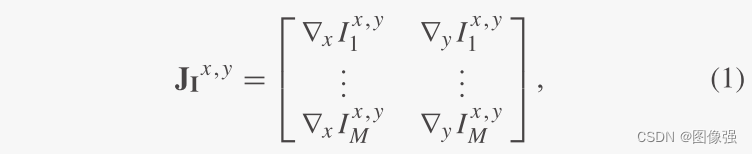
I
i
I_i
Ii是图像
I
I
I的第
i
i
i个通道,
∇
x
∇x
∇x或者
∇
y
∇y
∇y是水平或者垂直方向的导数。
v
=
[
c
o
s
θ
,
s
i
n
θ
]
T
v=[cos\theta, sin\theta]^T
v=[cosθ,sinθ]T方向上的梯度由
J
I
x
,
y
v
J_{I^{x,y}}v
JIx,yv给出
假设使用欧几里得度量(也就是欧式距离),图像
I
I
I上
v
v
v方向的像素(x,y)处对比度,可以用
J
I
x
,
y
v
J_{I^{x,y}}v
JIx,yv计算:
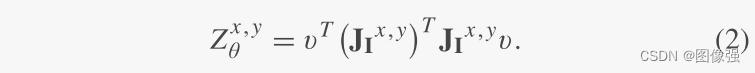
2×2矩阵
Z
I
x
,
y
=
(
J
I
x
,
y
)
T
J
I
x
,
y
Z_{I^{x,y}}=(J_{I^{x,y}})^TJ_{I^{x,y}}
ZIx,y=(JIx,y)TJIx,y是一个【结构张量(structure tensor)】:
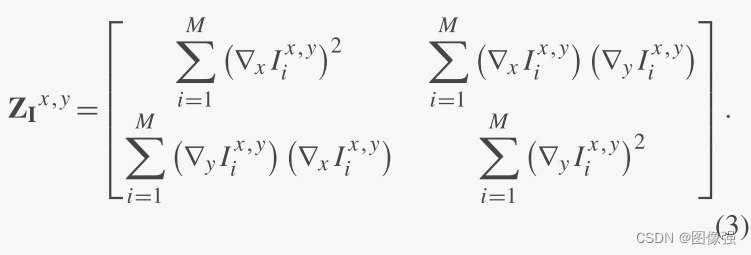
结构张量是具有实值的对称矩阵,因此它具有两个实数且非负的特征值。结构张量的特征向量表示多通道图像对比度最大和最小的方向,相应的特征值表示变化率。
扩展学习
欧几里得度量
🪢网络结构
作者提出的网络结构如下所示。目前看来清晰简单的结构,无需赘述,想要了解详细一点的同学可以去看原文。
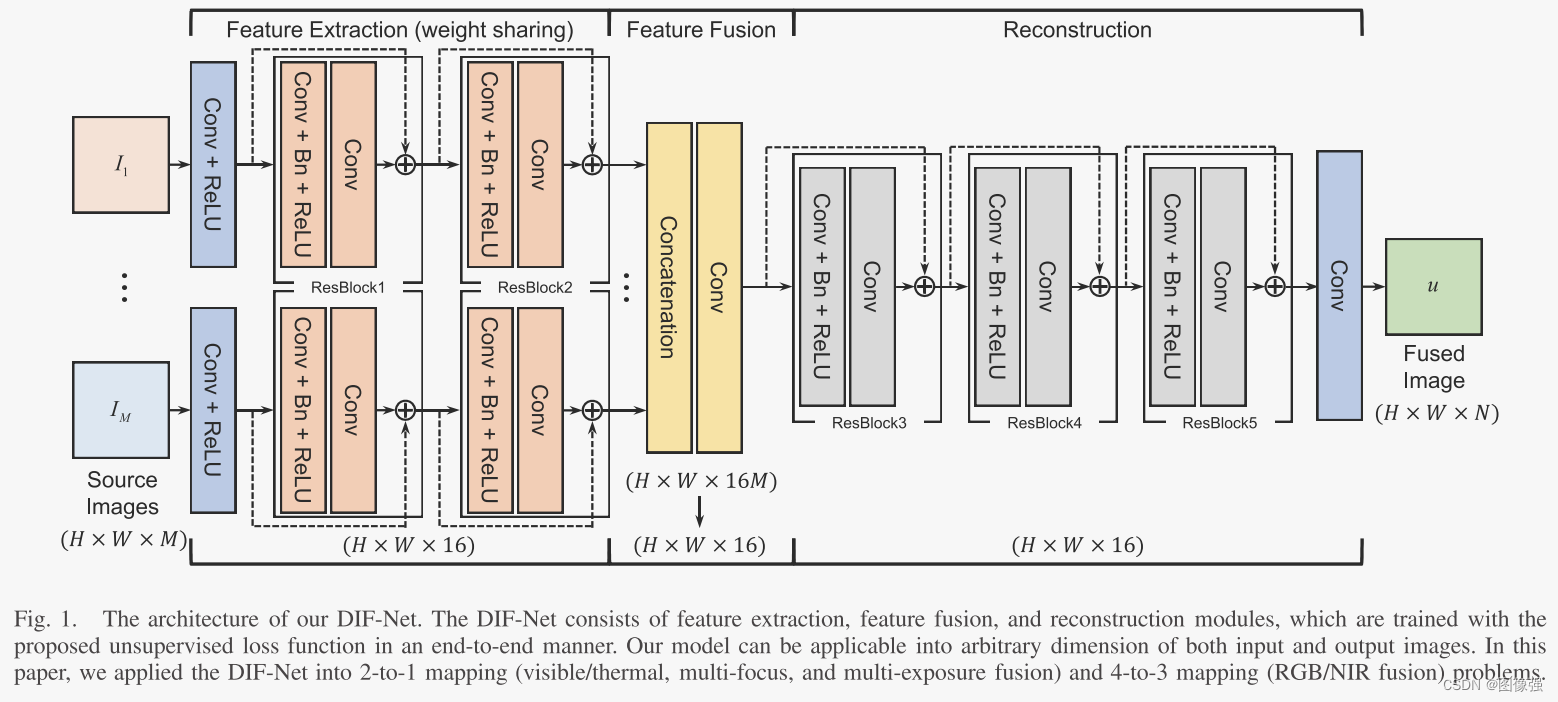
📉损失函数
损失函数=强度项+结构项

🔢数据集
- 训练:TNO
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置

🔬实验
📏评价指标

- MI- FMI- X- SCD- H- P- M
扩展学习
[图像融合定量指标分析]
🥅Baseline
- NSCT, CBF, GFF, GTF, ConvSR,VggML,FusionGAN,DenseFuse
✨✨✨扩展学习
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
🔬实验结果

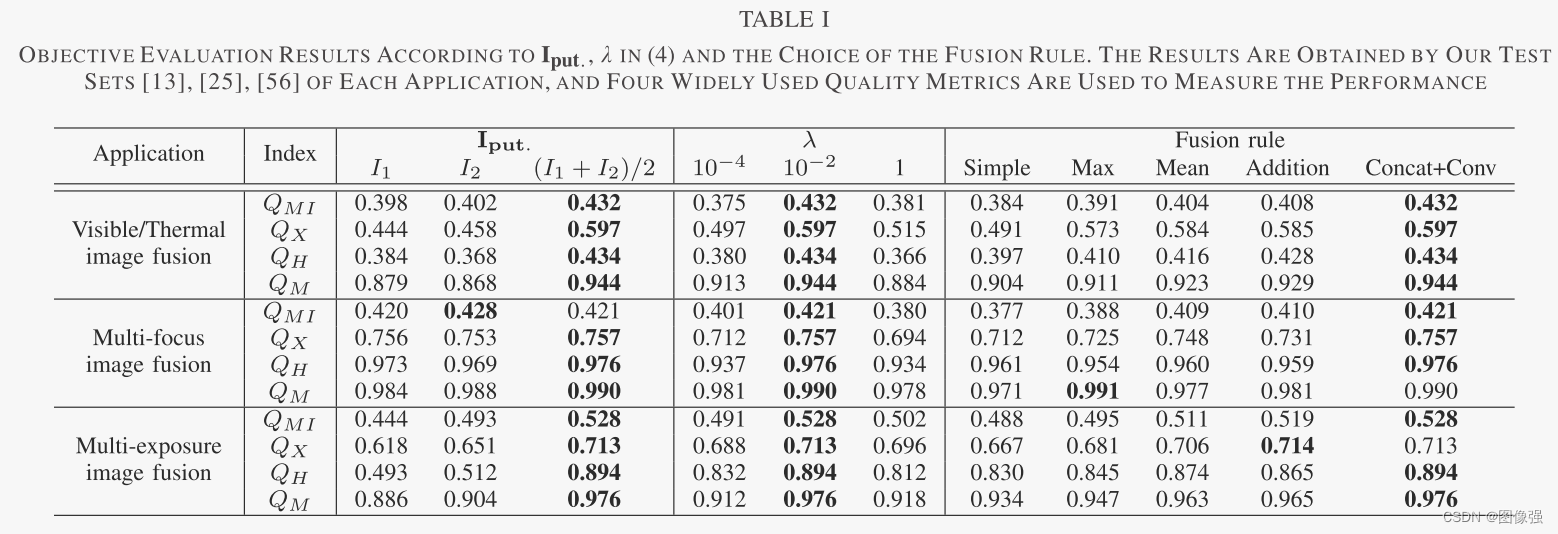




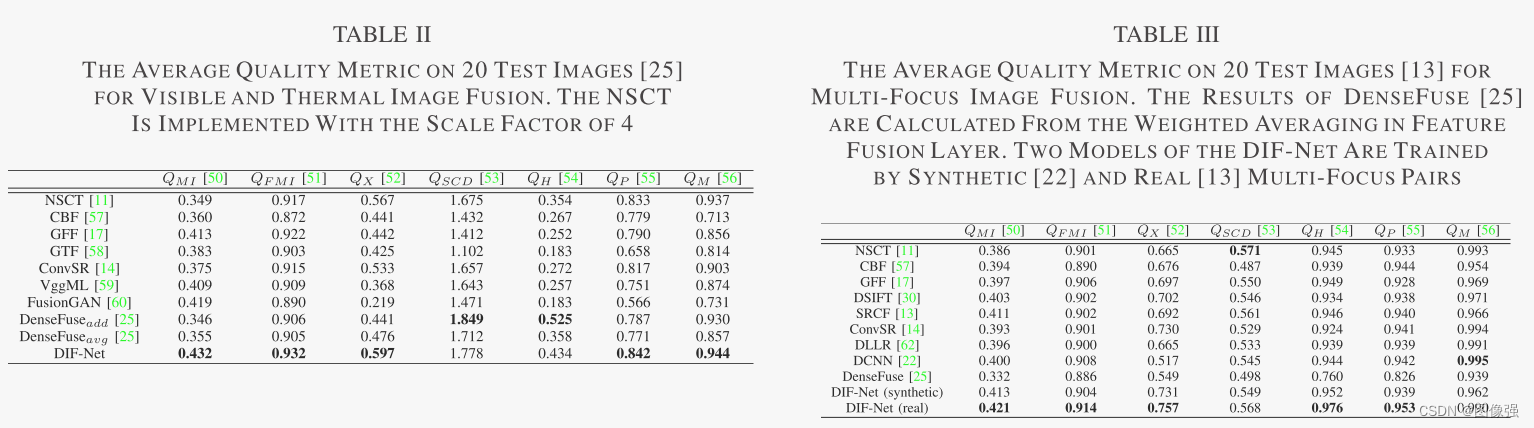





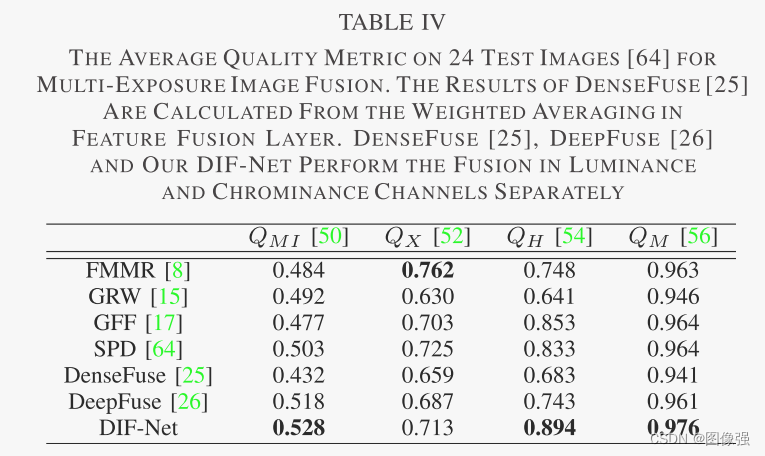
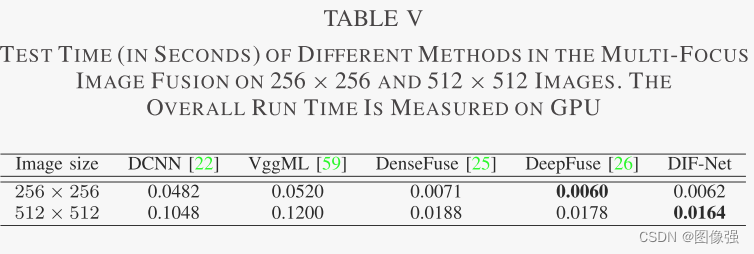
更多实验结果及分析可以查看原文:
📖[论文下载地址]
🚀传送门
📑图像融合相关论文阅读笔记
📑[(MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion]
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
🌻【如侵权请私信我删除】
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~

















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











