




关系图:
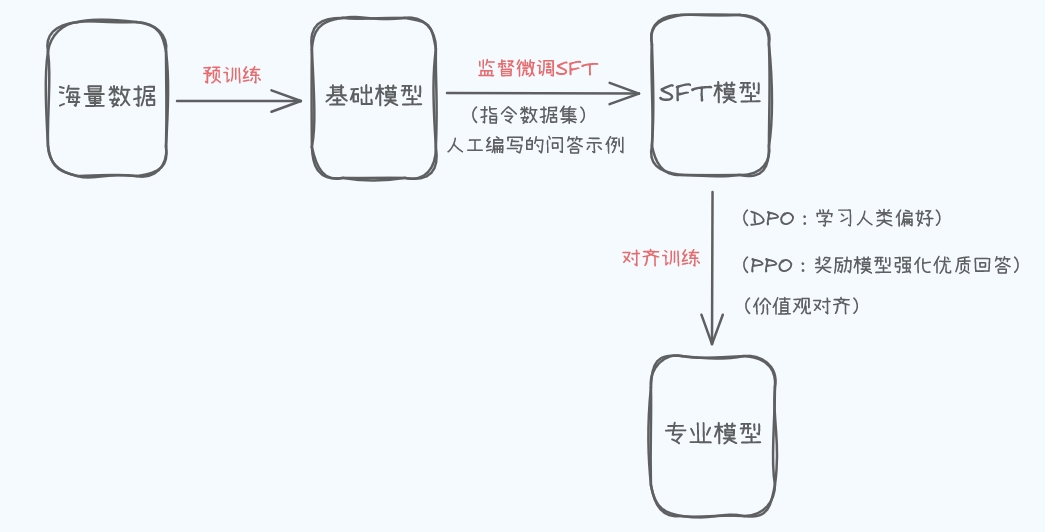
一、预训练
1、目标: 让模型掌握最基础、最通用的语言能力和世界知识。
2、怎么做?
-
给模型喂食海量的、未标注的文本数据(互联网网页、书籍、文章、代码等),数据量通常是TB甚至PB级别(万亿/千万亿词)。
-
训练任务通常是“预测下一个词”(自回归语言建模)或“完形填空”(掩码语言建模)。模型不断尝试根据前面的词预测下一个最可能出现的词。
3、结果: 得到一个基础模型。
二、微调
1、目标: 在基础模型强大的通用能力之上,让它学会执行特定任务或按照人类期望的方式行事。
2、为什么需要? 预训练得到的基础模型虽然知识渊博,但不好用、不可控、不专业。微调让它变得有用、安全、可控。
3、怎么做
使用规模小得多但质量高得多、针对性强的数据集,在基础模型上继续进行训练。微调有多种类型:
(1)SFT监督微调
-
目标: 教会模型理解并执行指令。
-
怎么做? 使用高质量的 指令-回复对 数据集。例如:
-
输入:
写一首关于春天的短诗。 -
期望输出:
春风拂面柳丝长,...
-
-
结果: 模型学会看到类似指令时,生成类似风格的回复。它从“语言学家”变成了能完成任务的“执行者”。
(2)对齐
-
目标: 让模型的输出更安全、更有帮助、更符合人类价值观,减少有害、偏见、幻觉(编造事实)和不一致。
-
怎么做? 使用更复杂的、基于人类反馈的技术:
-
基于人类反馈的强化学习:
-
训练一个奖励模型来学习人类更喜欢哪种回答(比如,哪个更有帮助?哪个更无害?)。
-
使用强化学习算法(如PPO)来调整模型参数,最大化奖励模型给出的预期奖励。模型学会生成人类更偏好的回答。
-
-
直接偏好优化:
-
一种更高效的替代方法(如DPO)。直接使用人类对回答的偏好数据(例如,回答A比回答B更好)来训练模型,绕过训练奖励模型和强化学习的复杂步骤。
-
-
4、结果: 模型从一个单纯的“执行者”变成了一个更可靠、有用、安全的“助手”。
三、结果对比
-
预训练输出 = 基础模型: 知识渊博但不听话、不可控。
-
(SFT)微调输出 = 任务专家模型: 能较好执行特定指令。
-
(对齐)微调输出 = AI助手: 既专业又安全可靠。
四、SFT 和 DPO 数据集格式
SFT微调一般用Alpaca格式,DPO优化的偏好数据一般用Sharegpt格式
1、SFT:让模型学习 “输入指令→输出符合预期的响应”:
Alpaca 格式的标准结构(JSON)
基础格式包含instruction(指令)、input(可选补充信息)、output(预期响应)三核心字段,支持单轮和多轮扩展:
// 1. 带补充信息的单轮指令(如需要上下文的任务)
{
"instruction": "基于以下文本总结核心观点",
"input": "SFT常用Alpaca格式,DPO常用ShareGPT格式,前者聚焦指令-响应对齐,后者聚焦偏好对比。",
"output": "核心观点:SFT与DPO的主流数据格式不同——SFT用Alpaca格式(适配指令-响应对齐),DPO用ShareGPT格式(适配偏好对比)。"
}
// 2. 多轮对话扩展(适配聊天场景,LLaMA Factory等工具支持)
{
"instruction": "模拟客服与用户的多轮对话",
"conversations": [ // 用conversations字段替代单轮的input/output
{"from": "user", "value": "我的订单还没发货,怎么回事?"},
{"from": "assistant", "value": "您好!请提供您的订单号,我帮您查询物流状态。"},
{"from": "user", "value": "订单号是12345678"},
{"from": "assistant", "value": "查询到您的订单已发货,物流单号为SF123456789,当前在【上海转运中心】,预计2天内送达。"}
]
}
2、DPO:让模型学习 “人类偏好”(即 “哪个响应更好”),因此 ShareGPT 格式围绕多轮对话中的 “用户输入→多个候选响应 + 偏好标签”。
ShareGPT 格式的标准结构(JSON)
核心是conversations数组,每个对话轮次包含 from(角色)、value(内容),且在多候选场景中需通过 label 偏好标签标注 chosen(人类偏好的响应)和 rejected(人类不偏好的响应)。
// 1. DPO专用:带偏好标注的多候选对话(核心格式)
{
"conversations": [
{"from": "user", "value": "推荐一本机器学习入门书"}, // 用户输入(固定)
// 候选1:人类偏好的响应(chosen)
{"from": "assistant", "value": "推荐《机器学习实战》:优点是案例驱动,代码可直接运行,适合零基础;缺点是理论深度较浅,适合入门后再学理论书。", "label": "chosen"},
// 候选2:人类不偏好的响应(rejected)
{"from": "assistant", "value": "机器学习书很多,你自己搜吧。", "label": "rejected"}
]
}
// 2. 复杂多轮DPO数据(多轮对话+每轮多候选)
{
"conversations": [
{"from": "user", "value": "什么是过拟合?"},
{"from": "assistant", "value": "过拟合是模型在训练数据上表现好,但在新数据上表现差,对吗?", "label": "rejected"}, // 解释不完整
{"from": "assistant", "value": "过拟合是模型过度学习训练数据的噪声,导致泛化能力下降——比如训练时准确率98%,测试时只有70%,常见解决方法是正则化、增加数据量。", "label": "chosen"}, // 解释完整
{"from": "user", "value": "那怎么用正则化解决过拟合?"}, // 第二轮用户输入
{"from": "assistant", "value": "正则化就是加惩罚项,比如L1、L2。", "label": "rejected"}, // 解释简略
{"from": "assistant", "value": "常用L2正则化(权重衰减):在损失函数中加入权重的平方和,限制权重过大,避免模型过度依赖个别特征;L1正则化则是加入权重的绝对值,会让部分权重为0,实现特征选择,两者都能降低过拟合风险。", "label": "chosen"} // 解释详细
]
}


















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









