







RLHF:Reinforcement Learning from Human Feedback 人类反馈强化学习
大模型之所以像人一样表达,核心在于RLHF机制的实现。 特别是xxx-chat的开源大模型,都是经过RLHF之后的。
RLHF的两个策略:PPO和DPO
PPO:Proximal Policy Optimization 近端策略优化
DPO:Direct Preference Optimization 直接策略优化
RLHF的实现过程:
1、给模型一个prompt
2、在t时刻,模型根据上文,产出一个token(对应强化学习的动作,记作At)
3、在t时刻,At对应的即时收益为Rt,总收益是Vt(Vt=即时收益+未来收益),也可以理解成“对人类喜好的衡量”,此时模型的状态有St变为St+1
那Rt、Vt怎么得到呢?模型什么时候更新?
RLHF的4个角色:
1、Actor Model:训练目标-语言模型。需要训练
2、Critic Model:用来预估总收益Vt。需要训练
3、Reward Model:计算即时收益Rt。提前训练好,RLHF阶段冻结
4、Reference Model:在RLHF阶段给语言模型增加“约束”、类似残差连接的作用。提前训练好,RLHF阶段冻结
提前训练好的 Reward Model 和 Reference Model 分别是SFT和RW阶段的产物,在本文中不做描述。
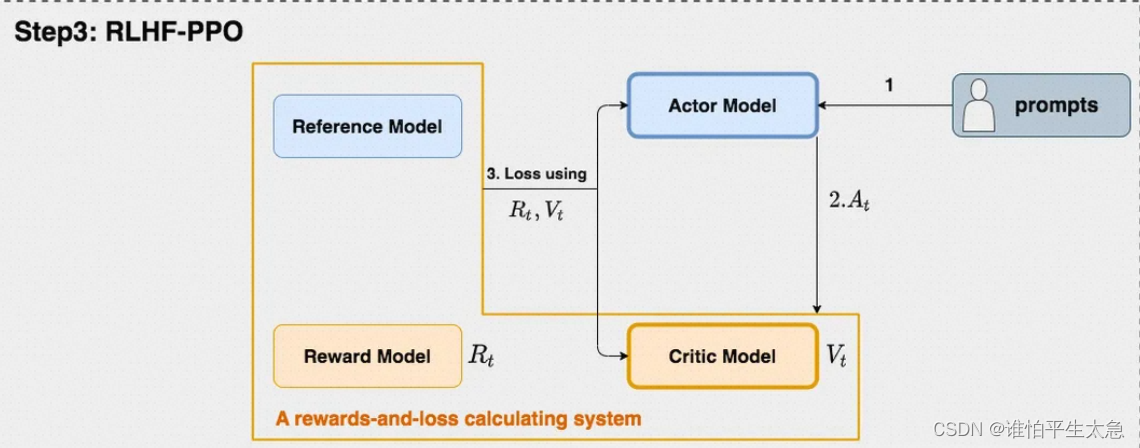
整个RLHF-PPO的过程,重点在于 Rt和Vt如何定义、并如何用来计算损失?
损失分成两个部分:
1、更新Actor model的actor loss:用于评估Actor是否产生了符合人类喜好的结果
2、更新Critic model的critic loss:用于评估Critic是否正确预测了人类的喜好
在思考loss怎么设计之前,先想想我们有什么。 我们有一个SFT之后的Reference Model,这也是Actor Model的初始模型;还有一个RW之后的Reward Model,这也是Critic Model的初始模型。 然后我们就要在一些高质量数据上,用 左脚(Critic Model)踩右脚(Actor Model),再一步步更新左脚和右脚,得到一个上天了的左右脚。
是不是很有难度。下面慢慢来理解 更新的发动机——损失函数。
先看 actor loss:
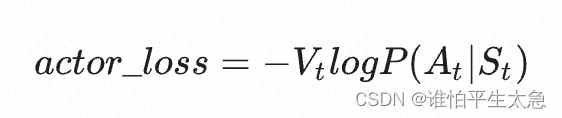
v1版本:最小化loss意味着最大化(基于St产生的At的概率 * 生成At时的预估总收益Vt)。v1版本是不是很合理。loss含义是 对上文St而言,如果token At产生的预估收益越高,那就增大它出现的概率,否则降低它的概率。那么皮球丢给了 Vt,毕竟我们只有一个 对整体打分的 Reward model,怎么就能直接用来生成 Vt了呢?
v2版本:就来审视Vt,毕竟是预估总收益,是不是可以用 当前的即时收益和未来可能的总收益 = Rt+ γ * Vt 更加精细。 并且定义了一个概念 优势 advantage 等于 这两者的差值。优势的作用是 联接了 Rt和Vt。 使得 actor_loss 更加具体。
我们回顾下 Vt的概念:Critic对At的总收益预测。实际执行At的总收益是 Vt加上优势。
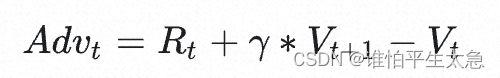
然后,我们用优势 adv_t来替换掉 Vt,得到第二版的 actor_loss
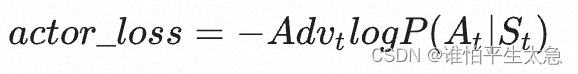
v3版本:对Rt进行改造,使其能够衡量Actor模型是否遵从了Ref模型的约束。 这一步设计的目的是 要让 Rt 可计算,其中一种设计是 除了最后的T时刻, 其余时刻的即时奖励,我们就用“Actor是否遵循了Ref的约束”来进行评价。

v4版本:对Adv_t进行改造,使其不仅考虑了当前时刻的优势,还考虑了未来的优势。这一步的目的是 丰富 Adv_t的设计,尽管已经可计算了。
v5版本:重复利用了1个batch的数据来做ppo_epochs次更新,并引入剪裁机制,控制actor的更新幅度。这一步的目的优化迭代效率。
再看 critic loss: 实际收益和预估收益的MSE作为loss即可。
实际收益:Adv_t + Vt
预估收益:在ppo_epochs过程中,Vt可以理解成 Critic_old。
相当于伴随着 critic loss的减小,预估收益 Vt 越来越接近实际收益。
也因为 actor loss的减小,产生At的收益越来越大,也就是Actor Model表现得越来越好。

















 4022
4022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









