






算法交易又称自动交易、黑盒交易或者机器交易,它指的是通过使用计算机程序来发出交易指令的方法。在交易中,程序可以决定的范围包括交易时间的选择、交易的价格,甚至包括最后需要成交的证券数量。这种类型的交易试图利用计算机相对于人类交易者的速度和计算资源。
算法交易广泛应用于投资银行、养老基金、共同基金,以及其他买方机构投资者,以把大额交易分割为许多小额交易来应付市场风险和冲击。卖方交易员,例如做市商和一些对冲基金,为市场提供流动性,自动生成和执行指令。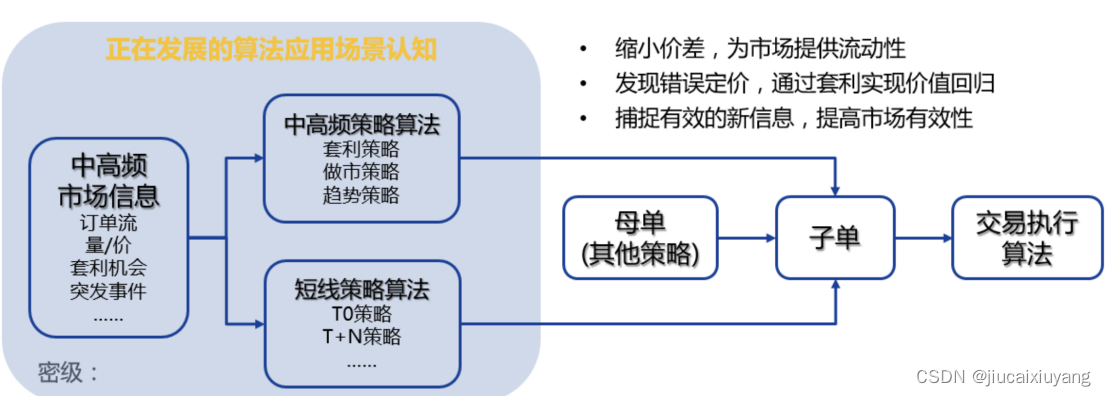
算法的几种类型:
第一:被动算法常见:
被动算法基于历史数据建模对大额委托进行拆分成小单流入市场,增加委托隐秘性降低冲击成本。被动算法目前有十种,分别是:
1. XT TWAP:迅投基于时间加权平均的均匀拆单算法。
2. KF TWAP CORE:卡方基于时间加权平均的拆单算法。
3. KF VWAP CORE:卡方基于历史成交量加权平均的拆单算法。
4. XT VWAP:迅投基于历史成交量加权平均的拆单算法。
5. KF POV CORE:卡方基于成交量与市场总成交量占比的拆单算法。
6. XT VP:迅投基于参与量与市场成交总量成特定比例的拆单算法。
7. KFPASSTHRU:卡方指定价格报单的拆单算法。
8. XT PINLINE:迅投基于市场vwap智能优化价格的拆单算法。
9. XT DMA:迅投尽可能快速完成拆单目标的拆单算法。
10. XT ICEBERG:迅投基于冰山单保持一定成交速度的拆单算法。
第二:主动算法:
是一种特殊的机器学习算法,其特点在于它能够主动地选择未标记样本中具有最大信息量的样本,并向标记者请求标签。
具体来说,主动学习算法可以分为以下两个阶段:
1. 初始化阶段:
在这个阶段,算法会随机从未标记样本中选取一部分作为训练集,并由标记者进行标注,用来建立初始分类器模型。
2. 循环查询阶段:
在这个阶段,算法会从未标记样本集中,按照某种查询标准选取具有最大信息量的样本,并向标记者请求标签。然后,这个已标注的样本会被加入到训练集中,并用来重新训练分类器。这个过程会不断迭代,直到达到训练停止标准为止。
主动学习算法的主要优势在于,它可以利用未标记样本中蕴含的大量信息,来提升分类器的性能。
同时,由于它只需要少量的已标记样本进行初始化,因此可以节省大量的标注成本。
但是,它的缺点在于,由于需要不断地向标记者请求标签,因此它的训练时间可能会比被动学习算法更长。
第三:T0算法交易
是一种基于算法的交易策略,主要应用于股票市场中。
该策略的核心思想是将一笔大单按照算法拆分成无数个小单,以降低冲击成本、隐藏交易意图。
在T0算法交易中,交易者通常会使用大量的短周期量价和微观结构指标,结合行业、概念的当日走势,使用复杂的机器学习算法预测当日量价走势。这种策略旨在提高交易的效率和准确性,以获取更好的投资回报。
(1)、均值回归策略。
它通过计算股票价格相对于其均值的偏离程度,来判断买入和卖出的时机。当股票价格偏离均值较大时,认为存在回归的趋势,可以选择买入;而当股票价格偏离均值较小时,认为回归趋势即将结束,可以选择卖出。
(2)、趋势跟踪策略。
它根据市场行情的变化,跟踪股票价格的变动趋势,从而做出买入或卖出的决策。当股票价格上涨时,趋势跟踪策略会建议买入;当股票价格下跌时,趋势跟踪策略会建议卖出。
(3)、日内交易策略。
它主要利用市场上的短期波动,在短时间内进行买入和卖出操作,以获取利润。日内交易策略通常需要快速反应和精准的操作技巧。
算法交易一般涉及就是这个几个主要方面,今天是干货分享篇,建议收藏!欢迎随时关注交流!

















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









