







总结自视频(吴恩达大模型入门课):9_13_generative-ai-project-lifecycle_哔哩哔哩_bilibili
生成周期如下图,包含四部分:任务范围(Scope),选择大模型(Select),调整大模型,部署应用程序。

1. 任务范围(Scope)
同时多个任务。

还是限定在某个具体任务即可。
以此估计任务的难度和成本。
2. 选择大模型(Select)
选择现成的开源大模型,还是自己从零(pretrain)开始训练一个。

从0开始训练时,首先要根据不同的任务,选择不同的网络结构。
2.1 Encoder-only LLM
仅使用Transformer的编码器部分(如BERT、RoBERTa等),通过双向自注意力机制捕捉文本的全局上下文信息。其预训练阶段的核心任务是掩码语言模型(MLM),即随机掩盖输入文本中的部分token,让模型根据上下文预测被掩盖的token。
例如,输入句子“The cat [MASK] on the mat”,模型需预测被掩盖的“sat”

Encoder-only模型无需生成序列,而是专注于理解输入内容,如分类或特征提取。
Encoder-only模型的训练分为预训练和微调两个阶段:
预训练
-
掩码语言模型(MLM):随机掩盖15%的输入token(如替换为[MASK]、随机词或保留原词),模型预测被掩盖的原始词,以学习双向上下文表征
-
辅助任务:如BERT的下一句预测(NSP),判断两个句子是否连续,增强句子间关系建模
-
动态掩码:改进版本(如RoBERTa)采用动态掩码策略,每次训练时随机更换掩盖位置,提升鲁棒性
微调
-
预训练模型通过少量标注数据适配下游任务,如添加分类层进行情感分析或问答。
-
例如,使用[CLS]标记的聚合表示驱动分类任务,或提取实体识别任务的序列标注。
应用场景
Encoder-only模型适用于无需生成文本、侧重理解与分析的任务,典型场景包括:
-
文本分类
-
情感分析(判断句子情感倾向)。
-
主题分类(如新闻归类为体育、科技等)。
-
-
信息抽取
-
命名实体识别(NER):识别文本中的人名、地点等实体。
-
关系抽取:分析实体间的关联(如“苹果”公司与“乔布斯”的关系)。
-
2.2 Decoder-only LLM
仅使用Transformer的解码器部分(如GPT系列),也叫自回归模型(autoregressive model),因为它们在生成文本时是逐词进行的,每个词依赖于之前的词。
通过单向自注意力机制(仅关注当前词左侧的上下文)逐词生成文本。这和Encoder-only的双向上下文不同。需要明确两者的区别,比如BERT是Encoder-only,而GPT是Decoder-only的例子。
也叫因果语言模型(causal language model),因果指的是每个词只能关注前面的词,避免未来信息的泄露,这也是自回归的核心。
-
与Encoder-only模型的区别
-
Decoder-only模型生成文本,擅长开放式任务(如对话、续写);
-
Encoder-only模型理解文本,擅长分类、信息抽取等分析任务。
-
训练方式,完整的句子,训练时挨个从句子开头开始输入到模型中,预测下一个token,遵循因果语言模型,逐词生成,每个词依赖于之前的词。

应用场景
- Decoder-only模型适用于需要生成连贯文本或动态推理的任务,典型场景包括:
-
文本生成
-
创意写作(诗歌、故事生成)
-
内容续写(如邮件自动补全、代码补全工具GitHub Copilot)
-
-
对话系统
-
开放域聊天机器人(如ChatGPT)
-
任务导向对话(订票、客服问答)
-
2.3 Encoder-Decoder LLM
使用完整的Transformer结构
-
T5(Text-to-Text Transfer Transformer)
-
BART(Bidirectional and Auto-Regressive Transformer)
Encoder-Decoder模型的训练结合了双向编码和自回归生成,其中T5将所有任务(分类、翻译、生成)统一为“文本到文本”格式。
2.3.1 训练方式
去噪自编码(Denoising Autoencoding)
-
对输入文本进行破坏(如随机掩码、删除或打乱词序),编码器学习恢复原始文本,解码器生成完整输出。
-
例如,BART通过多种噪声策略(文本填充、句子置换等)提升鲁棒性。
跨度预测(Span Prediction)
-
如T5将输入文本中的连续片段替换为特殊标记,解码器需预测被掩盖的原始内容。

2.3.2 应用领域
翻译,文本总结,问答;

2.3.3 典型案例与模型演进
-
Transformer(2017)
-
首个Encoder-Decoder架构的模型,为机器翻译设计,奠定后续模型基础。
-
-
BART(2019)
-
结合双向编码(类似BERT)和自回归解码(类似GPT),在文本生成与理解任务中表现均衡。
-
-
T5(2020)
-
提出“Text-to-Text”统一框架,将所有任务视为文本生成,简化训练流程。
-
-
PEGASUS(2020)
-
专为摘要任务优化,通过选择重要句子作为预训练目标(GSG任务)。
-
-
FLAN-T5(2022)
-
基于T5的指令微调版本,支持多任务泛化与零样本生成。
-
2.3.4 与Encoder-only/Decoder-only模型的对比
| 特性 | Encoder-only (BERT) | Decoder-only (GPT) | Encoder-Decoder (T5) |
|---|---|---|---|
| 核心能力 | 文本理解 | 文本生成 | 理解+生成 |
| 注意力机制 | 双向 | 单向(因果掩码) | 编码器双向,解码器单向 |
| 典型任务 | 分类、NER | 对话、续写 | 翻译、摘要 |
| 输入输出关系 | 单文本输入,固定输出 | 单文本输入,生成输出 | 双文本(输入→输出) |
| 预训练任务 | MLM、NSP | 因果语言建模 | 去噪自编码、跨度预测 |
训练方式区别如下图。

3. 调整大模型
调整模型方法有:prompt engineering, Fine-tuning, Align with human feedback
3.1 提示词工程(prompt engineering)
-
定义:通过设计或优化输入提示(prompt),引导模型生成更符合预期的输出。
-
特点:
-
无需修改模型内部参数,只需调整输入。
-
适用于预训练模型(如GPT系列),直接通过提示控制输出。
-
-
应用场景:
-
让模型生成特定格式的文本(如代码、表格)。
-
引导模型完成特定任务(如问答、翻译)。
-
-
优点:
-
简单高效,适合快速实验。
-
不需要额外训练数据或计算资源。
-
-
缺点:
-
对复杂任务效果有限。
-
提示设计需要经验和技巧。
-
3.2 微调(Fine-tuning)
-
定义:在预训练模型的基础上,使用特定任务的数据进一步训练,调整模型参数以适应新任务。
-
特点:
-
需要任务相关的数据集。
-
调整模型参数,使其更专注于特定任务。
-
-
应用场景:
-
将通用语言模型(如GPT、BERT)适配到特定领域(如医疗、法律)。
-
针对特定任务(如情感分析、文本分类)优化模型。
-
-
优点:
-
效果通常优于提示工程。
-
可以显著提升模型在特定任务上的性能。
-
-
缺点:
-
需要大量标注数据和计算资源。
-
训练过程复杂,可能出现过拟合。
-
3.2.1 全参数微调(full fine-tuning)
解冻全部模型参数,利用领域数据重新训练。
-
优点:效果最佳,模型完全适配新数据分布。
-
缺点:计算成本高,易过拟合,需大量显存(如微调LLaMA-7B需4×24GB GPU)。
-
适用场景:数据充足(>10万条)、硬件资源丰富的场景。
全参数微调问题:灾难性遗忘,是全参数微调(Full Fine-tuning)大语言模型(LLM)时的一个常见问题,指的是模型在微调过程中过度拟合新任务数据,导致其遗忘预训练阶段学到的通用知识,从而降低模型在原始任务或其他任务上的性能。这一问题在资源有限或数据分布差异较大的场景中尤为突出。

解决办法:
- 不微调;
- 同时微调多个任务;
- 不完全微调,使用参数高效微调(Parameter-Efficient Fine-tuning, PEFT)。
3.2.2 参数高效微调
针对显存和计算限制,PEFT通过冻结大部分参数、仅训练少量新增结构实现高效适配。
具体可参考:LLM参数高效微调PEFT-CSDN博客
3.2.3 微调训练集
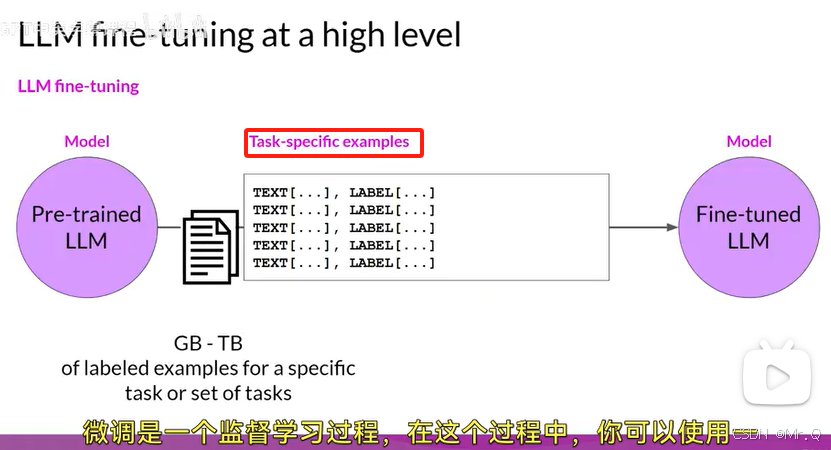
注意数据准备,训练数据要转换成和特定任务相关的指令,如下图所示,所以微调模型也叫指令模型。

3.3 基于人类反馈的对齐(Align with Human Feedback)
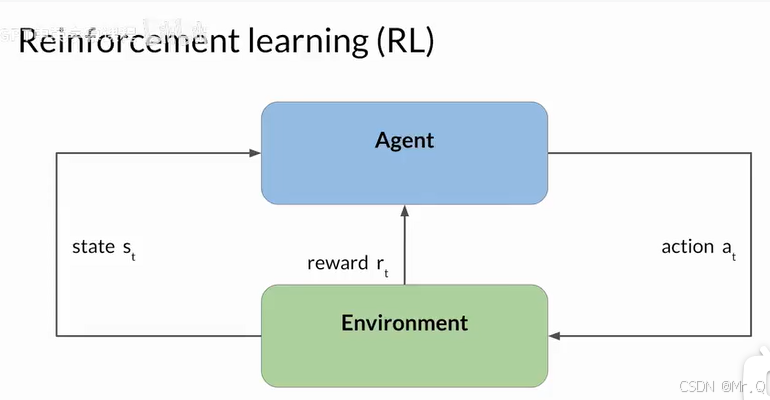
-
定义:通过人类反馈微调模型(强化学习,Reinforcement Learning from human feedback,简称RLHF),使其输出更符合人类价值观或任务需求。
-
特点:
-
使用人类标注的偏好数据(如选择更好的输出)。
-
通常结合强化学习(如RLHF,基于人类反馈的强化学习)。
-
-
应用场景:
-
让模型生成更安全、更符合伦理的输出。
-
优化对话系统,使其更自然、有用。
-
-
优点:
-
显著提升模型的实用性和安全性。
-
使模型更符合人类期望。
-
-
缺点:
-
需要大量人类标注数据,成本高。
-
实现复杂,涉及强化学习等技术。
-
3.4 模型评价指标
3.4.1 ROUGE1
评估生成文本与参考文本的重叠程度,常用于文本摘要。
单词匹配,Recall计算,标注是有4个单词(human),生成了5个中有4个被预测到了,即召回4个;正确率,生成的单词中,出现在标注的概率,F1值同理,都是只管单词,而不管单词的顺序和语义。

3.4.2 ROUGE2
两个单词匹配。一对去匹配,这样就带有顺序信息,评估更加准确。如下图,Recall标注中有3个对子,召回了2个"it is"和“cold outside",所以召回率是2/3;准确率和F1同理。ROUGE2分数明显比ROUGE1低,这是因为匹配单词越长,就越难匹配,分数就越低。

3.4.3 ROUGE-L
基于最长公共子序列(LCS),首先会计算标注和生成文本之间的最长公共子串长度。这里最长公共子串长度是2,有两个最长公共子串长度都是2。

3.4.4 BLEU

评估生成文本与参考文本的n-gram(n个单词,1-gram计算1个单词匹配准确率,2-gram计算2个单词匹配准确率,3-gram计算3个单词匹配准确率)重叠程度,常用于机器翻译。简单高效,广泛使用,但是忽略语义和语序,对多样性不敏感。
-
统计生成文本与参考文本中n-gram(如1-gram、2-gram)的匹配数。
-
引入惩罚因子(Brevity Penalty)惩罚过短生成文本。
4. 部署应用程序
优化大模型,使其充分利用计算机资源。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











