






一、制作数据集
1.制作数据集文件夹
制作YOLOv4的数据集文件夹需满足一定目录格式。
1.首先创建一个文件夹。
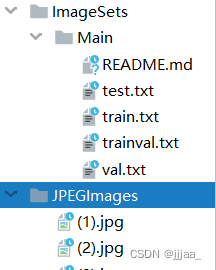
2.然后在这个文件夹内,再创建两个文件夹,分别叫imageSets和JPEGImages,这两个文件夹 一个用于存放标注后生成的标注文件,一个用于存放数据集图像。
3.最后还需要再创建一个train文件,用来做训练。
数据集目录如图所示:
2.收集图像
完成数据集文件夹创建后,这时候我们就需要收集需要目标检测的数据集图像了,这边我们以人为数据集做标记为例,我们需要收集的就是有人的图像。这里的收集途径有很多,百度、小红书,然后找到相关的图像给他截图下来了。
3.标注数据集
标注数据集需要用到labelimg标注软件,这个可以通过Python环境进行下载,下载的教程可以看其他博客,但有时候容易下载出错,所以我直接使用老师提供的标注软件labelimg直接运行。
最后我们一共标注了203张图像。
二、数据集训练模型
1.环境配置与下载官方源码
(1)下载YOLOv4官方源码
在这里,我使用的是基于课上老师的yolov4代码。
(2)下载PyCharm编译器
(3)下载Anaconda
(4)配置YOLOv4运行环境
2.配置训练文件
(1)准备功能
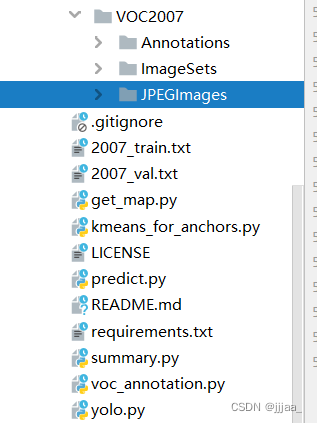
有了环境以及YOLOv4的源码,就可以开始训练模型了!首先将YOLOv项目文件夹与数据集文件夹放在同一个目录下,如下图所示。
(2)配置好运行的环境
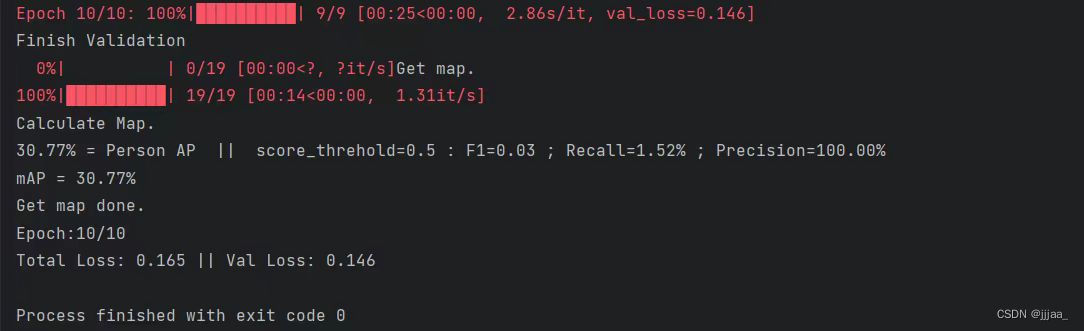
3.模型训练
现在就可以开始训练了,训练是通过yolov的train.py进行,点开yolov项目的train.py,训练前需要修改一些参数,需要修改的参数如下所示:

是否使用Cuda,没有GPU可以设置成False。以及数据集图像的数量。
4.常见报错
(1)数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。
(2)注意存放的路径是否同一路径。
三、利用模型进行目标检测
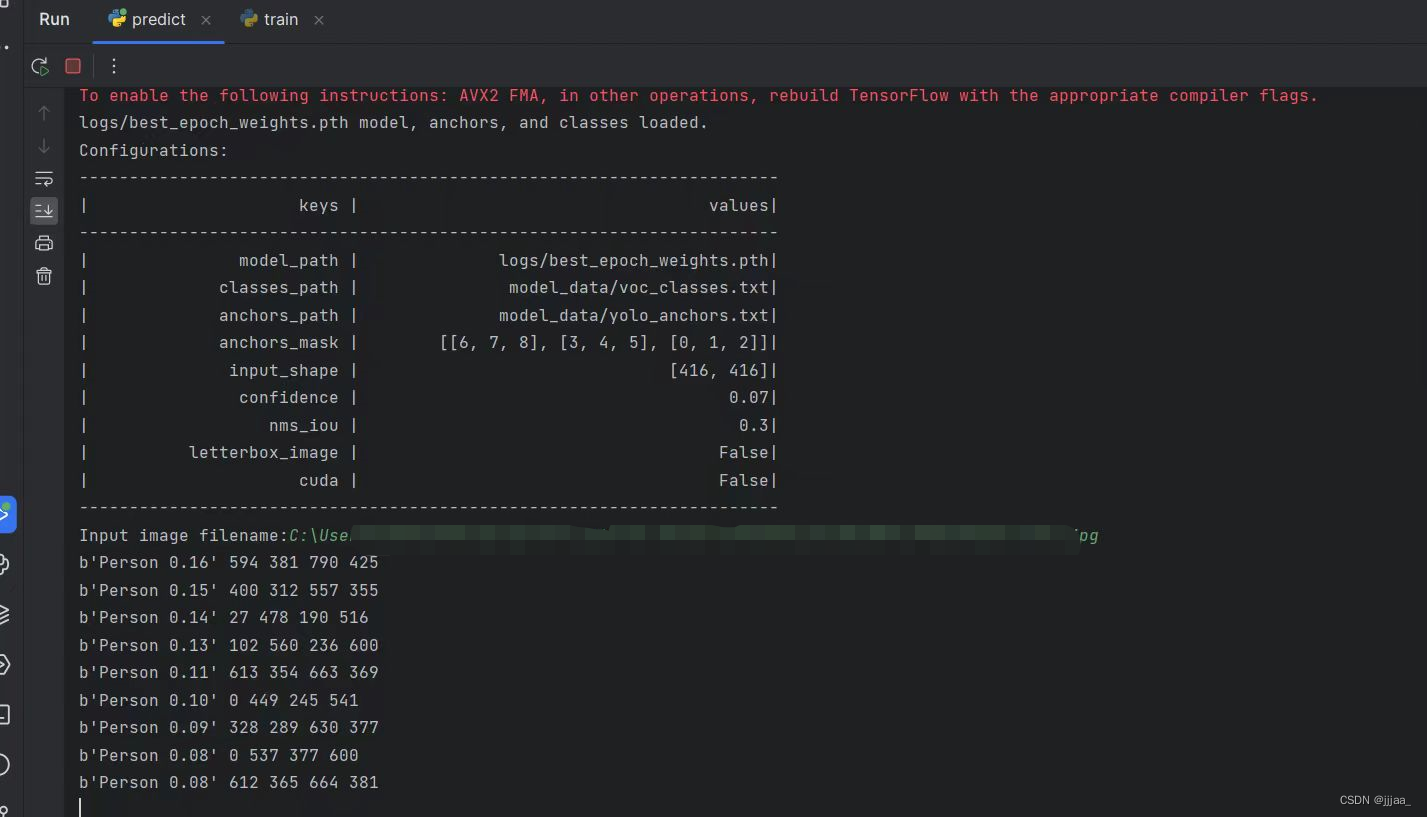
跑检测是通过yolov4的predict.py进行,点开yolov4项目的predict.py
总结
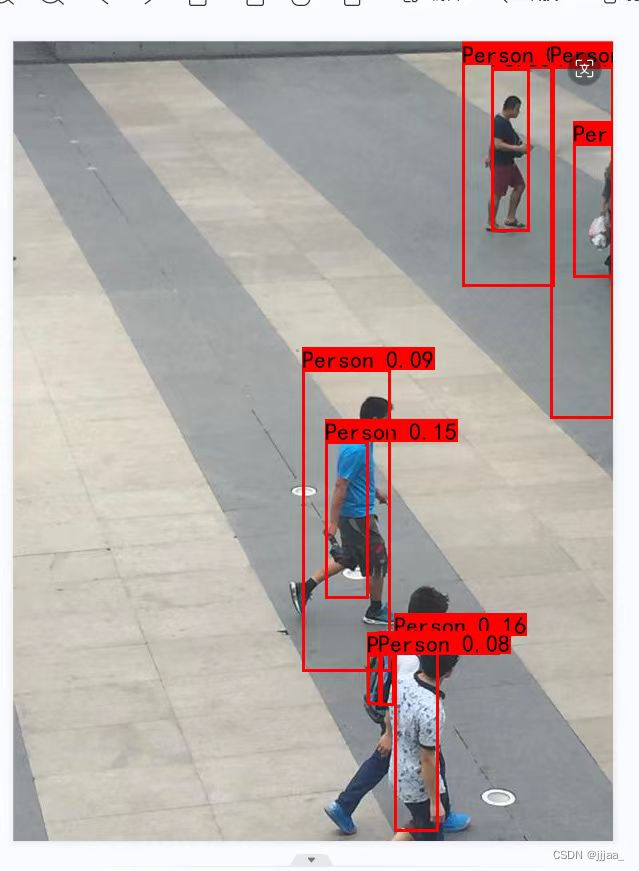
大概就是这样一个流程。通过本实验,我们成功利用自己标注的数据集训练出一个针对特定任务的深度学习模型,并在测试图片上取得了效果。实验结果表明,自标注数据集在模型训练中具有重要应用价值,能够有效提升模型性能。当然,在实验过程中仍存在不足,如数据集规模和质量还有待提高,模型的优化测略还需进一步探索等等。在这里只提供大概流程、遇到的一点点问题以及实验的结果。
最后的最后
















 2064
2064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









