






目录
一、模型简介与下载
DETR(Detection Transformer)是一种新型的目标检测模型,由Facebook AI Research (FAIR) 在2020年提出。DETR的核心思想是将目标检测任务视为一个直接的集合预测问题,而不是传统的两步或多步预测问题。这种方法的创新之处在于它直接预测目标的类别和边界框,而不是先生成大量的候选区域,然后再对这些区域进行分类和边界框回归。
1、模型架构
DETR的架构主要包括两个部分:CNN(卷积神经网络)编码器和Transformer解码器。
-
CNN编码器:通常使用ResNet作为骨干网络,负责从输入图像中提取特征。编码器输出一组固定大小的特征集合,这些特征集合包含了图像中所有目标的信息。
-
Transformer解码器:使用标准的Transformer架构,它接收编码器的输出,并生成目标的预测。解码器的输出是一个集合,其中包含了目标的类别和边界框坐标。
不好意思,模型简介这块的内容全来自于gpt的内容,不过大家大概知道它是个什么东西就好了,不同于传统的one-stage和two-stage目标检测模型,DETR采用了自然语言领域的transformer结构,这也是transformer首次运用到目标检测领域中。
2、模型下载
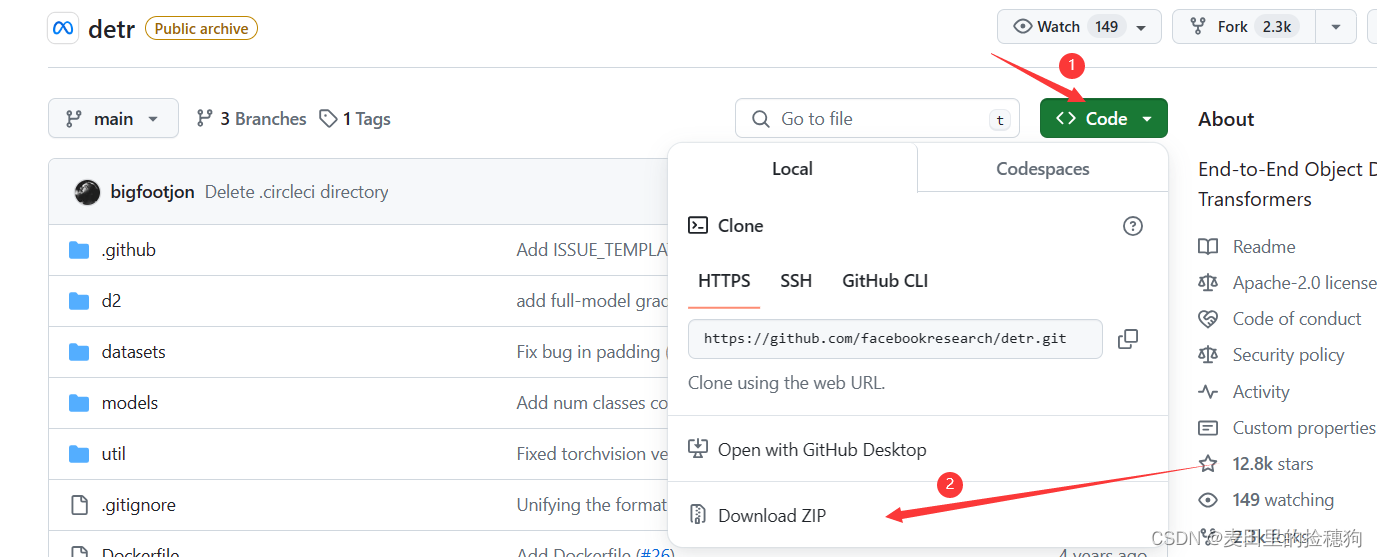
下载地址:facebookresearch/detr: End-to-End Object Detection with Transformers (github.com)
打开链接以后直接将项目工程克隆到本地然后解压:
二、使用labelme标注工具进行数据标注
labelme的下载很简单,在安装anaconda后直接在Anaconda Prompt命令窗口中输入以下指令,关于Anaconda+pycharm的安装和使用CSDN上有很多已有的教程,笔者在这里不做赘述了。打开Anaconda Prompt,新建python虚拟环境,
conda create -n detr python=3.8 其中detr为环境名,激活新建环境,指令如下:
conda activate detr激活后直接运行如下代码即可安装labelme,安装好以后,再输入labelme,即可启动.
pip install labelme #安装labelme
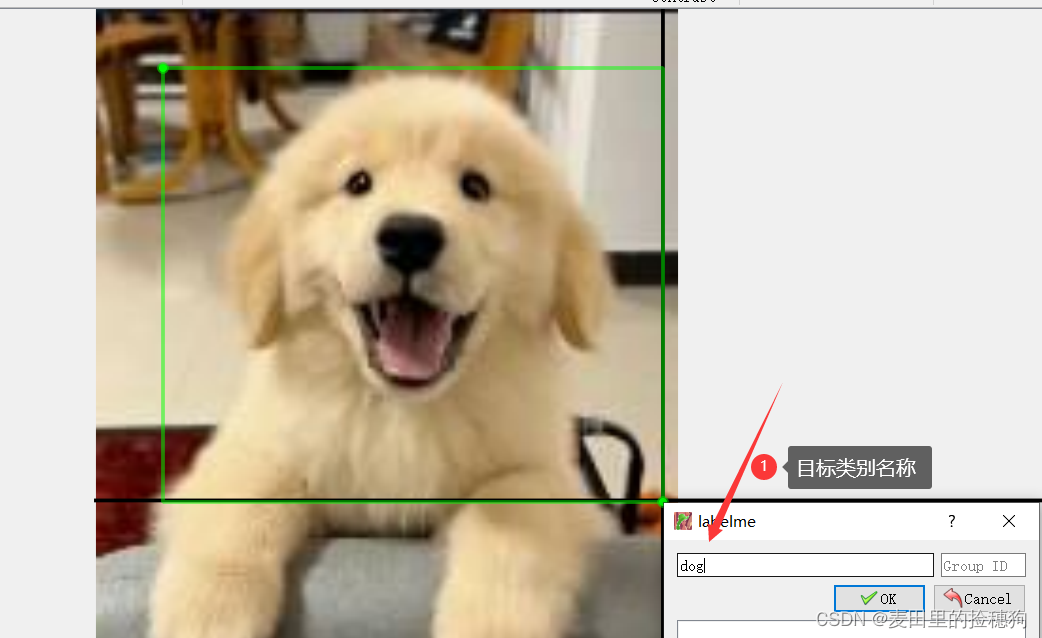
labelme #启动labelmelabelme的GUI界面如下:

这里笔者随便以一张图片进行样例演示,打开图片以后,鼠标点击右键,选择创建矩形,就可以进行图片的标注了,标注好的文件点击保存即可。

三、模型训练
1、环境配置
进入工程文件所在路径,具体如下,用户可以改为自己的文件存放路径。
cd D:\com_visionExperiments\Graduation_pro\detr-main
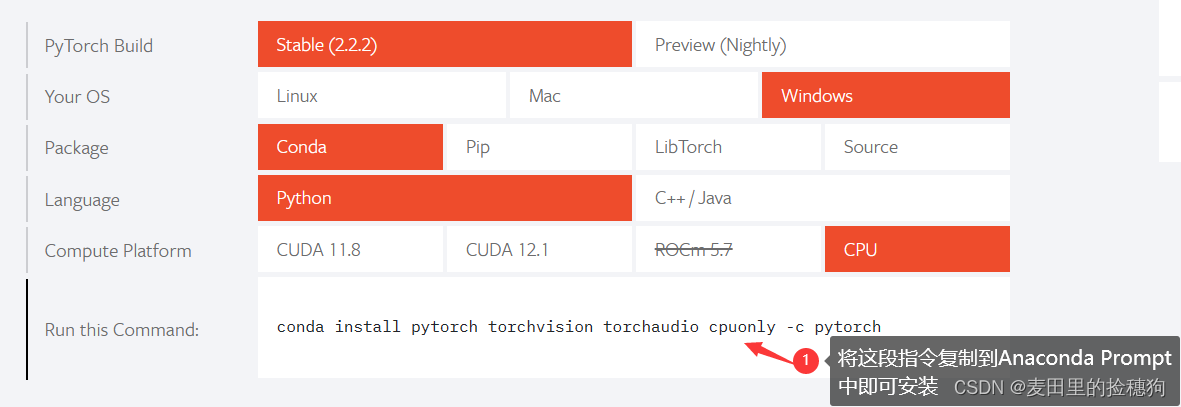
安装pytorch,进入pytorch官网:PyTorch,选择自己需要的类型进行安装,由于笔者本人是AMD显卡,所以只能使用cpu版本的pytorch,,所以需要单独安装。如果读者是英伟达显卡,可以安装cuda版本的,如果还不熟悉的可以去看看别人的教程,csdn有很多大佬写的很清楚。或者直接在requirement.txt中就可以安装,不过笔者一般都是单独安装。
安装模型需要的文件包:
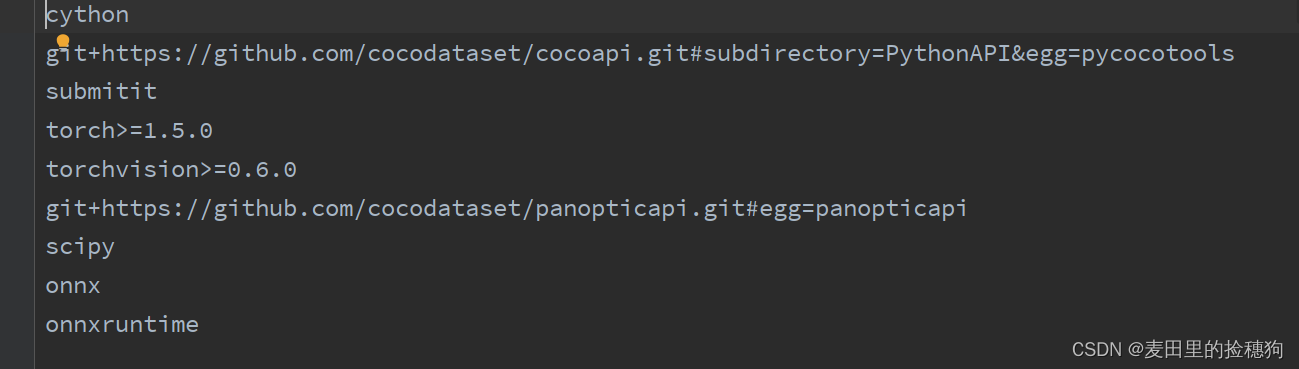
pip install -r requirements.txtrequierments.txt中存放了模型需要用到的库,如下所示.或者当我们用pycharm打开工程后,软件代码区上方就会提示install requirements.txt,用户直接点击安装即可。
其中关于pycocotools和panopticapi可能会安装出错,需要用户手动安装,可以参考这篇博客:
Python 离线安装环境方法 python离线包怎么安装_mob6454cc680fc0的技术博客_51CTO博客
笔者估计panopticapi可以成功安装,但是pycocotools可能会出错,对于这种情况不妨直接在Anaconda Prompt中进行安装,如下:
pip install pycocotools2、文件管理和格式转换
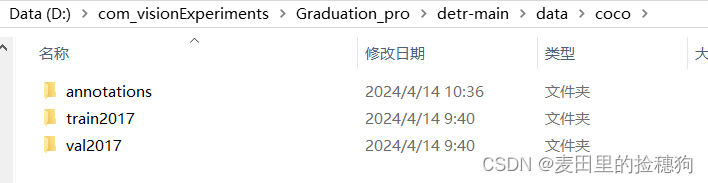
labelme标注好的数据格式是.json,但是对于DETR的训练来讲我们需要将标注好.json的数据转化为coco数据格式,具体的文件存放格式参考下图,这也是官方给出的文件管理方式,用户需要严格参照:

其中,annotations中存放的是转化为coco数据格式的标签文件,具体如下:

用户必须严格按照笔者图中的文件命名方式进行命名,训练集清一色命名为instances_train2017.json,验证集清一色命名为instances_val2017.json,这是模型本身的命名要求,用户需要严格遵守。
train2017和val2107中存放训练集图片和验证集图片即可,如下图:
在pycharm中打开模型工程,新建python脚本文件,使用下面的脚本代码即可将labelme标注好的.json文件批量转化为coco格式,其中代码最后两行为需要修改的文件路径,只做这两处改动即可运行代码,具体的请参考这篇博客,笔者也是参考的文中方法二。Labelme标注的json数据转化为coco格式的数据_json转换成coco-CSDN博客
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
# import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
class labelme2coco(object):
def __init__(self, labelme_json=[], save_json_path='./tran.json'):
self.labelme_json = labelme_json
self.save_json_path = save_json_path
self.images = []
self.categories = []
self.annotations = []
# self.data_coco = {}
self.label = []
self.annID = 1
self.height = 0
self.width = 0
self.save_json()
def data_transfer(self):
for num, json_file in enumerate(self.labelme_json):
with open(json_file, 'r') as fp:
data = json.load(fp) # 加载json文件
self.images.append(self.image(data, num))
for shapes in data['shapes']:
label = shapes['label']
if label not in self.label:
self.categories.append(self.categorie(label))
self.label.append(label)
points = shapes['points'] # 这里的point是用rectangle标注得到的,只有两个点,需要转成四个点
points.append([points[0][0], points[1][1]])
points.append([points[1][0], points[0][1]])
self.annotations.append(self.annotation(points, label, num))
self.annID += 1
def image(self, data, num):
image = {}
img = utils.img_b64_to_arr(data['imageData']) # 解析原图片数据
# img=io.imread(data['imagePath']) # 通过图片路径打开图片
# img = cv2.imread(data['imagePath'], 0)
height, width = img.shape[:2]
img = None
image['height'] = height
image['width'] = width
image['id'] = num + 1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height = height
self.width = width
return image
def categorie(self, label):
categorie = {}
categorie['supercategory'] = 'Cancer'
categorie['id'] = len(self.label) + 1 # 0 默认为背景
categorie['name'] = label
return categorie
def annotation(self, points, label, num):
annotation = {}
annotation['segmentation'] = [list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = num + 1
# annotation['bbox'] = str(self.getbbox(points)) # 使用list保存json文件时报错(不知道为什么)
# list(map(int,a[1:-1].split(','))) a=annotation['bbox'] 使用该方式转成list
annotation['bbox'] = list(map(float, self.getbbox(points)))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
# annotation['category_id'] = self.getcatid(label)
annotation['category_id'] = self.getcatid(label) # 注意,源代码默认为1
annotation['id'] = self.annID
return annotation
def getcatid(self, label):
for categorie in self.categories:
if label == categorie['name']:
return categorie['id']
return 1
def getbbox(self, points):
# img = np.zeros([self.height,self.width],np.uint8)
# cv2.polylines(img, [np.asarray(points)], True, 1, lineType=cv2.LINE_AA) # 画边界线
# cv2.fillPoly(img, [np.asarray(points)], 1) # 画多边形 内部像素值为1
polygons = points
mask = self.polygons_to_mask([self.height, self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
'''从mask反算出其边框
mask:[h,w] 0、1组成的图片
1对应对象,只需计算1对应的行列号(左上角行列号,右下角行列号,就可以算出其边框)
'''
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
# 解析左上角行列号
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
# 解析右下角行列号
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c - left_top_c,
right_bottom_r - left_top_r] # [x1,y1,w,h] 对应COCO的bbox格式
def polygons_to_mask(self, img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco = {}
data_coco['images'] = self.images
data_coco['categories'] = self.categories
data_coco['annotations'] = self.annotations
return data_coco
def save_json(self):
self.data_transfer()
self.data_coco = self.data2coco()
# 保存json文件
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4, cls=MyEncoder) # indent=4 更加美观显示
labelme_json = glob.glob('./data/mouth/train/*.json')#labelme标注好的.json文件存放目录
# labelme_json=['./1.json']
labelme2coco(labelme_json, './data/coco/annotations/instances_train2017.json')#输出结果的存放目录
在运行代码之前可能还需要安装必要的库,比如opencv和sklearn等,按照下面操作即可:
pip install opencv-python #安装opencvconda install -c anaconda scikit-learn #安装sklearn库
值得注意的是,以上所有的库安装用户都必须在开头新建的detr环境下进行。转化后的文件放入annotations中,然后将训练集图片和验证集图片放入train2017和val2017即可开始接下来的训练了,再次提醒,文件管理存放方式一定要严格按照前文所述方式。
注意:labelme标注好的json文件中会存储原来被标注图片的存放路径。在转换以后的instances_train/val2017.json中可以查看。如下图:

detr在训练时会读取该路径下的图片进行训练,所以在一开始进行标注的时候就要将数据放在指定的模型工程文件路径下进行标注,否则就会出现报错提醒你No such file or directory...笔者在训练模型初没有意识到这个问题,所以辗转反侧,废了很大的功夫,现在在这里指出但求可以为后人扫清障碍。如果很不幸你确实没有意识到这个问题,在标注好数据以后惊醒,那么下面的代码可以更改json文件中保存的被标注图片的路径,可以运行下面代码更改了路径以后再将json文件转化为相应的instaces_train/val2017.json,这个代码也是我在网上找的,参考链接:批量修改json文件重命名后路径imagPath_请确保您已经将data.json替换为实际的json文件路径-CSDN博客
import json
import os, sys
#将labelme标注好的json文件中的图片路径改成想要的
json_path = r'D:/com_visionExperiments/Graduation_pro/detr-main/data/coco/labels/val_labels/'
#输入的json文件路径
def get_json_data(json_path):
with open(json_path, 'rb') as f:
params = json.load(f)
# 加载json文件中的内容给params
a = filename[:-5]
params['imagePath'] = a + ".jpg" # 这两行控制修改的内容 时间有限就写的很草率
dict = params
# 将修改后的内容保存在dict中
f.close()
# 关闭json读模式
return dict
# 返回dict字典内容
def write_json_data(dict):
# 写入json文件
with open(json_path1, 'w') as r:
# 定义为写模式,名称定义为r
json.dump(dict, r, indent=2) # indent控制间隔
# 将dict写入名称为r的文件中
r.close()
# 关闭json写模式
# 获取文件夹中的文件名称列表
filenames = os.listdir(json_path)
# 遍历文件名
for filename in filenames:
filepath = json_path + '/' + filename
# print(filepath)
dict = {}
the_revised_dict = get_json_data(filepath)
json_path1 = 'D:/com_visionExperiments/Graduation_pro/detr-main/data/coco/labels_tran/val/' + filename # 修改json文件后保存的路径
write_json_data(the_revised_dict)值得注意的是这个还会把原来路径下的json文件批量拷贝到你指定的新路径下,如果不需要这个功能的话,拷贝以后删除就可以了。
3、修改模型参数
在训练之前还要在官网下载预训练模型,地址:facebookresearch/detr: End-to-End Object Detection with Transformers (github.com)

将下载好的模型保存在DETR工程所在的路径下:
在pycharm中新建python脚本文件,内容如下:
import torch
pretrained_weights= torch.load('detr-r50-e632da11.pth')
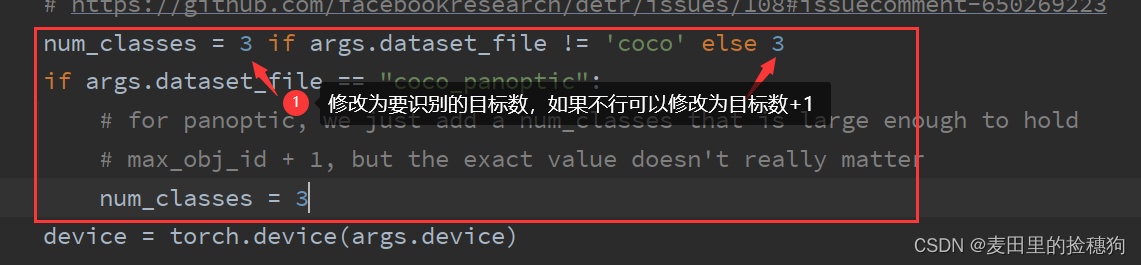
num_class = 3 #类别数
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1, 256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights, "detr-r50_%d.pth"%num_class)其中num_class为类别数,网上很多教程说是类别数加一,但是笔者确实是填识别的类别数就行了,读者可以先按照我这样操作不行再改成类别数加一。执行代码,即可以生成自己的训练模型文件,如下:
在模型的工程文件下的models中打开detr.py文件,如下:
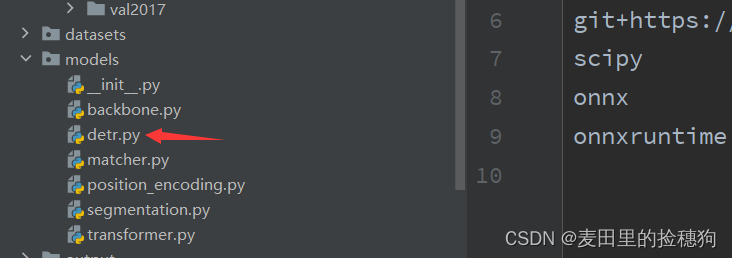
修改代码中的参数,还是前文所说,网上一般其他教程都是目标数+1,但是我直接设置为待识别的目标数就可以训练,我也不知道为什么。
打开main.py,修改模型配置:

大概在代码的82行左右可以找到如下语句,将其改为自己的数据存放路径。
parser.add_argument('--dataset_file', default='coco')#不用修改
parser.add_argument('--coco_path', type=str,default='/data/coco')#改为自己的数据路径找到代码的87行,将default后面的路径修改为自己指定的结果输出路径,如下:
parser.add_argument('--output_dir', default='output',help='path where to save, empty for no saving')#将default后面的路径修改为自己指定的输出路径指定训练方式,由于笔者是AMD显卡,所以只能使用cpu训练(很费劲)。一般这里默认是cuda,如果配置好gpu的读者可以不用修改,但是如果是cpu进行训练,一定要改为我这种形式,否则会报错。

加载训练模型,如图,其中detr-r50_3.pth是之前我们生成的训练模型。

改到这里其实就可以直接运行main.py进行数据的训练了,除此之外也可以在命令窗口进行参数配置和训练,指令如下,其中epoch为训练的轮数,其他的参数和上面讲解的一样理解就可以了。
python main.py --dataset_file "coco" --coco_path "data/coco" --epoch 300 --lr=1e-4 --batch_size=8 --num_workers=4 --output_dir="outputs" --resume="detr-r50_3.pth"当然了还有很多其他的参数配置信息,网上有很多大佬讲解的也很详细,这方面我目前还么有涉足。训练过程如下(很慢)。

4、训练过程可视化分析
训练完以后在output中产生如下结果:

打开eval中保存有如下结果,这里包含了PR曲线,以及在不同召回率下的评分,笔者也是刚接触,具体的也不太清楚:
在detr-main的工程文件夹下找到util文件夹,找到plot_utils.py,如下图:

在plot_utils.py的最后加上以下代码,并执行可以看到训练的结果:
if __name__ == '__main__':
files = list(Path('../output/eval').glob('*.pth'))
plot_precision_recall(files)
plt.show()
plot_logs(logs=Path('../outputs/log/'),fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt')
plt.show()
运行产生如下结果:

可能大家很奇怪为什么我的pr曲线始终是一条为1的直线,这是因为我只用了10张图片进行训练,所以结果出现了过拟合,不过也无所谓,本篇文章的目的就在于记录一下DETR模型的训练过程和方法,读者可以在自己的数据集上进行训练,查看结果。















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









