







目录
smoothdata函数的功能是对含噪数据进行平滑处理。
语法
B = smoothdata(A)
B = smoothdata(A,dim)
B = smoothdata(___,method)
B = smoothdata(___,method,window)
B = smoothdata(___,nanflag)
B = smoothdata(___,Name,Value)
[B,window] = smoothdata(___)说明
B= smoothdata(A) 使用以启发方式确定的固定窗口长度返回向量元素的移动平均值。窗口向下滑动向量的长度,计算每个窗口中的元素的平均值。
-
如果 A 为矩阵,smoothdata 计算每列的移动平均值。
-
如果 A 是多维数组,则 smoothdata 沿大小不等于 1 的第一个维度进行运算。
-
如果 A 是包含数值变量的表或时间表,则 smoothdata 针对每个变量单独执行运算。
B= smoothdata(A,dim) 沿 A 的维度 dim 执行运算。例如,如果 A 是一个矩阵,则 smoothdata(A,2) 对 A 中的每行数据进行平滑处理。
B = smoothdata(___,method) 为上述任一语法指定平滑处理方法。例如,B = smoothdata(A,'sgolay') 使用 Savitzky-golay 滤波器对 A 中的数据进行平滑处理。
B = smoothdata(___,method,window) 指定平滑处理方法使用的窗口长度。例如,smoothdata(A,'movmedian',5) 通过求五元素滑动窗的中位数,来对 A 中的数据进行平滑处理。
B= smoothdata(___,nanflag) 指定在使用上述任一语法时如何处理 NaN 值。'omitnan' 将忽略 NaN 值,'includenan' 则会在每个窗口中进行计算时包含 NaN 值。
B= smoothdata(___,Name,Value) 使用一个或多个名称-值对组参数指定用于平滑处理的其他参数。例如,如果 t 是时间值向量,则 smoothdata(A,'SamplePoints',t) 相对于 t 中的时间对 A 中的数据进行平滑处理。
[B,window] = smoothdata(___) 还会返回移动窗长度。
示例
使用移动平均值对数据进行平滑处理
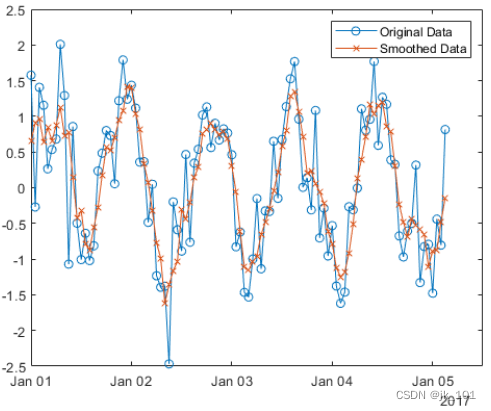
创建含有含噪数据的向量,并使用移动平均值对数据进行平滑处理。绘制原始数据和经过平滑处理的数据。
x = 1:100;
A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100);
B = smoothdata(A);
plot(x,A,'-o',x,B,'-x')
legend('Original Data','Smoothed Data')如图所示:
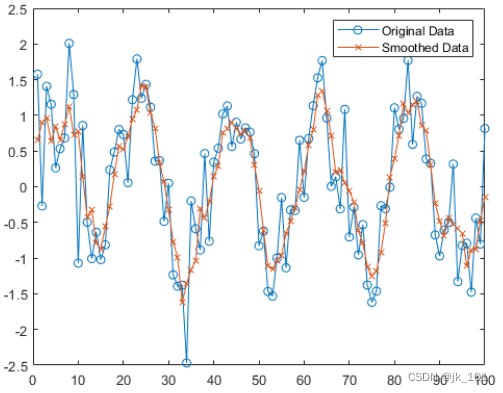
含噪数据的矩阵
创建一个矩阵,其中的行表示三个含噪信号。使用移动平均值对三个信号进行平滑处理,并绘制经过平滑处理的数据。
x = 1:100;
s1 = cos(2*pi*0.03*x+2*pi*rand) + 0.5*randn(1,100);
s2 = cos(2*pi*0.04*x+2*pi*rand) + 0.4*randn(1,100) + 5;
s3 = cos(2*pi*0.05*x+2*pi*rand) + 0.3*randn(1,100) - 5;
A = [s1; s2; s3];
B = smoothdata(A,2);
plot(x,B(1,:),x,B(2,:),x,B(3,:))如图所示:
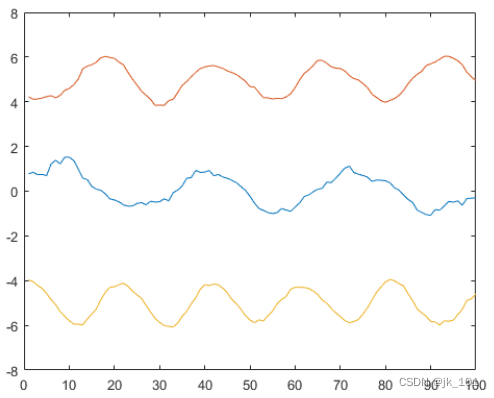
高斯滤波器
使用高斯加权移动平均滤波器对含噪数据向量进行平滑处理。显示滤波器使用的窗口长度。
x = 1:100;
A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100);
[B, window] = smoothdata(A,'gaussian');
window
window = 4使用长度为 20 的较大窗口对原始数据进行平滑处理。绘制两种窗口长度的平滑数据。
C = smoothdata(A,'gaussian',20);
plot(x,B,'-o',x,C,'-x')
legend('Small Window','Large Window')如图所示:
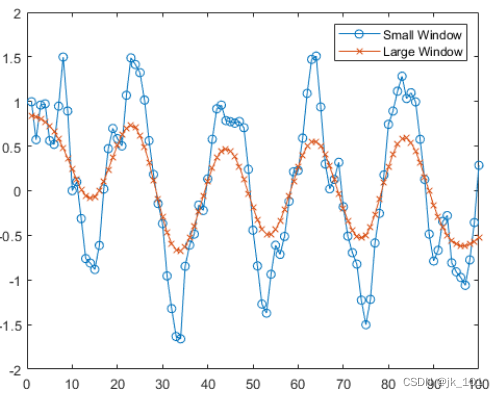
包含 NaN 的向量
创建包含 NaN 值的含噪向量,对数据进行平滑处理并忽略 NaN,这是默认设置。
A = [NaN randn(1,48) NaN randn(1,49) NaN];
B = smoothdata(A);对包含 NaN 值的数据进行平滑处理。包含 NaN 的窗口中的平均值为 NaN
C = smoothdata(A,'includenan');绘制 B 和 C 中经过平滑处理的数据图。
plot(1:100,B,'-o',1:100,C,'-x')
legend('Ignore NaN','Include NaN')如图所示:
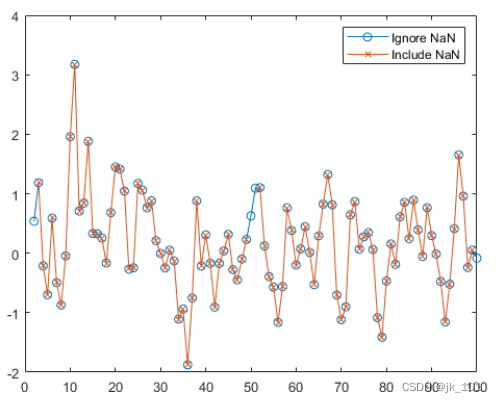
使用样本点对数据进行平滑处理
创建对应于时间向量 t 的含噪数据的向量。相对于 t 中的时间对数据进行平滑处理,并绘制原始数据和经过平滑处理的数据图。
x = 1:100;
A = cos(2*pi*0.05*x+2*pi*rand) + 0.5*randn(1,100);
t = datetime(2017,1,1,0,0,0) + hours(0:99);
B = smoothdata(A,'SamplePoints',t);
plot(t,A,'-o',t,B,'-x')
legend('Original Data','Smoothed Data')如图所示:
输入参数说明
A - 输入数组
输入数组,指定为向量、矩阵、多维数组、表或时间表。如果 A 是表或时间表,则变量必须为数值,或者必须使用 'DataVariables' 名称-值对组显式列出数值变量。当使用同时包含非数值变量的表时,指定变量很有用。
dim - 沿其运算的维度
沿其运算的维度,指定为正整数标量。如果未指定值,则默认值是大小不等于 1 的第一个数组维度。
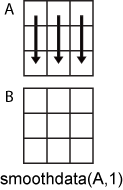
假设有一个矩阵 A。
B = smoothdata(A,1) 对 A 中的每列数据进行平滑处理。
B = smoothdata(A,2) 对 A 中的每行数据进行平滑处理。
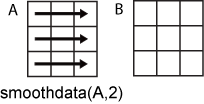
当 A 为表或时间表时,不支持 dim。smoothdata 分别对每个表或时间表变量进行运算。
method - 平滑处理方法
平滑处理方法,指定为以下选项之一:
-
'movmean' - A 的每个窗口内的移动平均值。此方法对于减少数据中的周期性趋势很有用。
-
'movmedian' - A 的每个窗口内的移动中位数。当存在离群值时,此方法对于减少数据中的周期性趋势很有用。
-
'gaussian' - A 的每个窗口内的高斯加权移动平均值。
-
'lowess' - A 的每个窗口内的线性回归。该方法可能会耗费大量计算资源,但会减少不连续性。
-
'loess' - A 的每个窗口内的二次回归。此方法的计算开销略高于 'lowess'。
-
'rlowess' - A 的每个窗口内的稳健线性回归。此方法比 'lowess' 方法的计算开销更大,不过它在处理离群值时更为稳健。
-
'rloess' - A 的每个窗口内的稳健二次回归。此方法比 'loess' 方法的计算开销更大,不过它在处理离群值时更为稳健。
-
'sgolay' - Savitzky-Golay 滤波器,它根据在 A 的每个窗口上拟合的二次多项式进行平滑处理。当数据变化很快时,此方法可能比其他方法更有效。
window - 窗口长度
窗口长度,指定为正整数标量、由正整数组成的二元素向量、正持续时间标量或由正持续时间组成的二元素向量。
如果 window 是正整数标量,则窗口以当前元素为中心并且包含 window-1 个相邻元素。如果 window 是偶数,则窗口以当前元素和上一个元素为中心。如果 window 是由正整数组成的二元素向量 [b f],则窗口包含当前元素、其之前的 b 个元素和之后的 f 个元素。
当 A 是时间表或 'SamplePoints' 指定为 datetime 或 duration 向量时,window 的类型必须为 duration,并相对于样本点计算窗口。
当窗口长度还指定为输出参数时,输出值与输入值匹配。
nanflag - NaN 条件
NaN 条件,指定为下列值之一:
-
'omitnan' - 忽略输入中的 NaN 值。如果窗口所包含的值全部为 NaN,则 smoothdata 返回 NaN。
-
'includenan' - 在每个窗口内计算时包括 NaN 值,得到 NaN。

















 4954
4954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









