







目录
一、需求说明
1.搭建轻量级的本地大模型环境,用于智能体的开发和测试使用。
2.进行数据查询问答来验证环境可用。
3.当使用远程环境时,实现大模型api调用。
二、本地大模型部署
1.LM studio和Ollama
本地大模型的轻量化部署,可以考虑使用LM studio和Ollama。先说结论,我选择Ollama,主要是考虑到其轻量化、开源、模型丰富且下载速度极快、资源占用低等优秀特性。
当然,按照惯例,我们还是用kimi分析一下两者的优劣势,大家按需自取。
LM Studio 和 Ollama 都是用于部署和运行大型语言模型(LLM)的工具,它们各有特点和优势。
LM Studio 是一个开源、用户友好的平台,它提供了图形用户界面(GUI)和命令行界面(CLI),使得即使是非技术人员也能轻松地部署和使用大型语言模型。它支持本地运行LLMs,允许用户在没有互联网连接的情况下,在本地设备上运行模型。LM Studio 还支持从平台如 Hugging Face 下载兼容的模型文件,并提供了一个应用内Chat UI,使用户能够与AI模型进行交互。此外,LM Studio 还支持多模型同时运行,并通过“Playground”模式增强性能和输出。
Ollama 则是一个更注重命令行操作的工具,它提供了一个简洁易用的命令行界面和服务器,用户可以通过简单的命令来下载、运行和管理各种开源LLM。Ollama 的优势在于其开源免费、简单易用、模型丰富以及资源占用低。它支持多种模型,如Llama 3、Mistral、Qwen2等,并提供一键下载和切换功能。Ollama 还支持在Docker环境中运行,这为用户提供了更多的灵活性和便利性。
总的来说,如果你更喜欢图形化操作界面,希望有一个直观且易于上手的工具,LM Studio 可能是更好的选择。而如果你更倾向于使用命令行,或者需要一个轻量级且资源占用低的工具,Ollama 可能更适合你的需求。两者都为用户提供了探索和利用大型语言模型的可能性,具体选择哪个工具,可以根据个人的使用习惯和需求来决定。
2. Ollama的安装
2.1.官网注册和下载
安装就此略过,github上有具体指南:
https://github.com/ollama/ollama
2.2.模型查看和选择
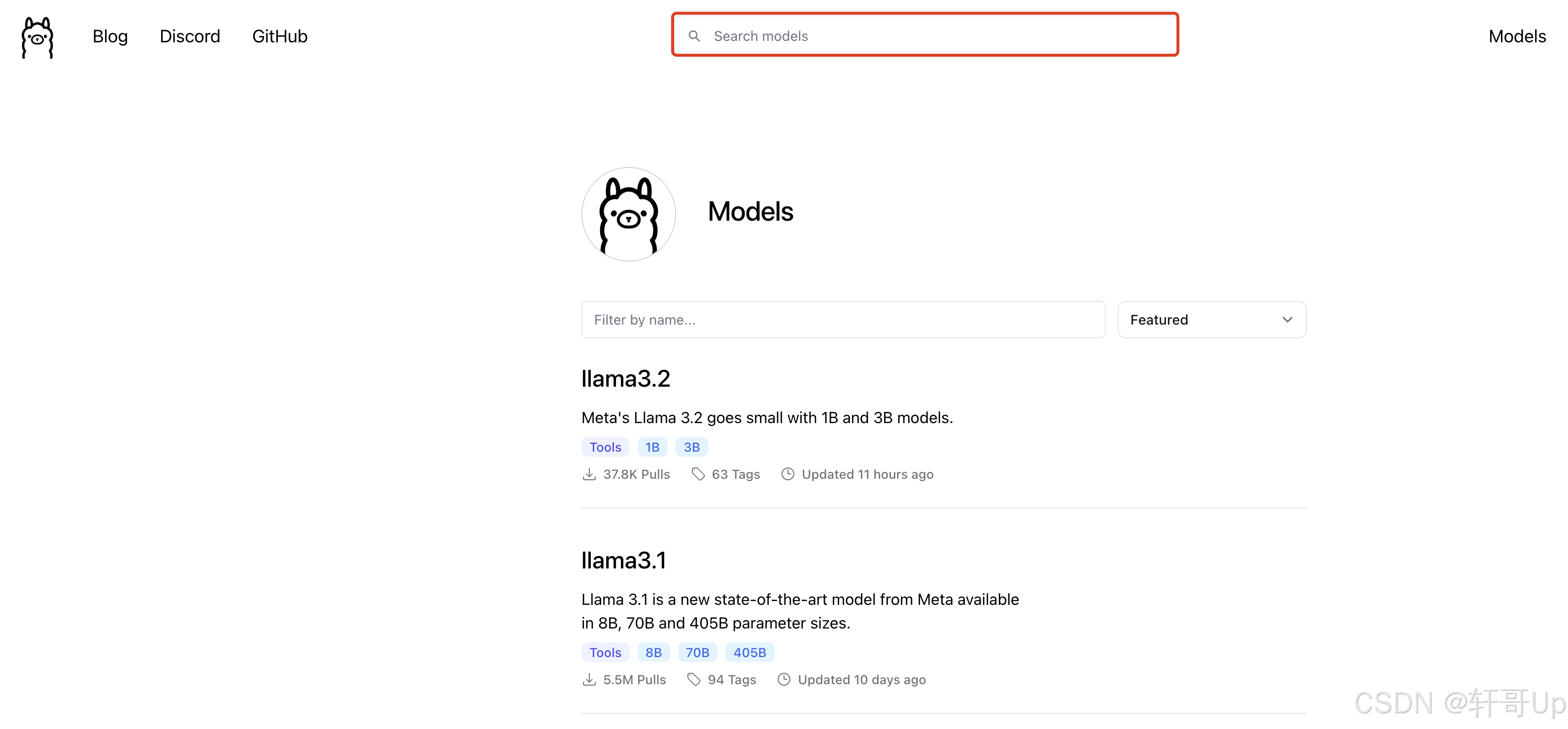
方式一:用户可以自行搜索查看
方式二:在github的模型清单查看
在https://github.com/ollama/ollama/tree/main,查看Model library 样例。
注意:
1.您应该至少有 8 GB 的 RAM 来运行 7B 型号,16 GB 的 RAM 来运行 13B 型号,32 GB 的 RAM 来运行 33B 型号。
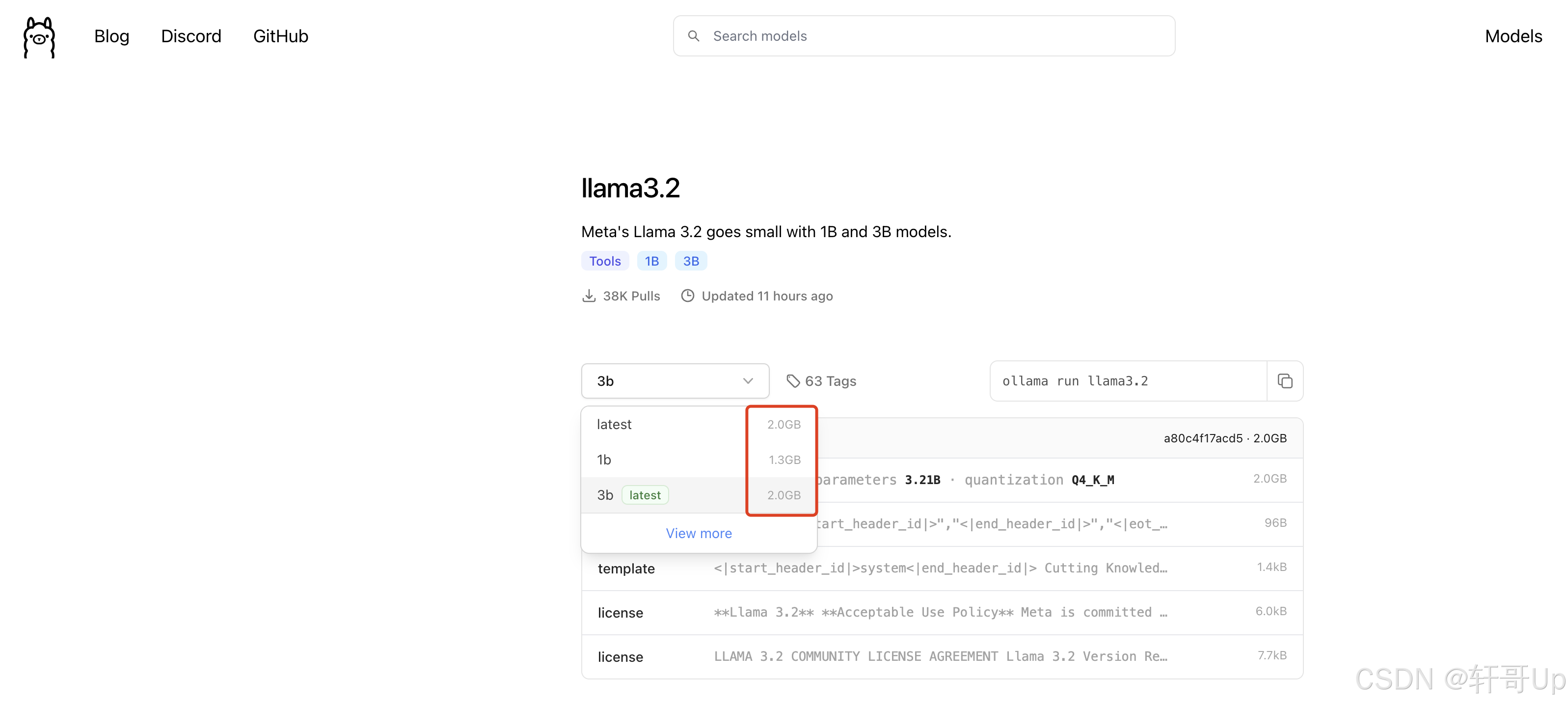
2.如何查看模型的大小。
2.3.模型安装
打开终端,运行命令即可。贴心的Ollama,连字都舍不得你敲,一键复制,简直是喂饭到嘴里。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8673
8673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











