







前言

论文地址:https://proceedings.neurips.cc/paper/2020/file/1325cdae3b6f0f91a1b629307bf2d498-Paper.pdf
前人工作&存在问题
由于transformer在多语言MT、跨语言PT、和多任务上的应用,模型容量需要被扩大。
然而,transformer不是越深越好(梯度消失)。具体的,在多语言\任务上,如何增大模型容量,同时保证语言、任务之间有正向的迁移,是一个开放的命题。
本文贡献
训练隐变量,用隐变量的采样来选择模型层,来提高模型的深度。
具体做法
layer selection
transformer中的某一层的某一个sublayer长这样(用的是pre-norm而非post-norm):

对于某一层(包含多个sublayer),模型训练一个分布(对应的模型参数是z),然后从该分布抽样一个实数,代表选择该层的一个系数。
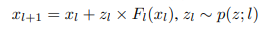
此时,模型的训练目标是最大化条件概率p(y|x;θ,z)。然而,“Marginalizing over z becomes intractable when l grows large”,因此需要使用变分推理(variational inference),取得ELBO。
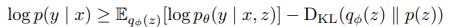
由公式3右边第一项可知,模型训练时需要输入具体的z,来计算p(y|x, z),这就涉及到了采样。文章使用gumbel-softmax重参数化发来使得这一过程可微。具体来说,额外定义一个
gumbel distribution(G(0, 1)),对它进行采样,而模型只需为每一个语种、每一层定义一个二维的参数:[α1,α2],利用gumbel distribution的特性,来间接完成采样。另外,随着temperature hyperparameter(τ)不断趋向于0,采样出来的结果会更加离散(hard\discrete)。

另外,对于公式3的右边第二项,我们需要假设一个理想的分布p(z),让模型参数z的分布通过KL散度去拟合它。文中说:使用共轭先验分布β(a,b)可以控制参数z(a=b=1是一个均匀的先验,a>b会让z向选择更多的层进行优化,a<b会让z向跳过更多的层进行优化)(文章使用aggregated posterior(不懂)来作为先验)。
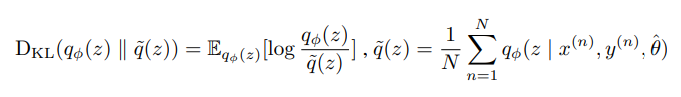
在这样的设置下,模型第 l 层的梯度计算如下,后续的实验会证明起到了normalization的作用:
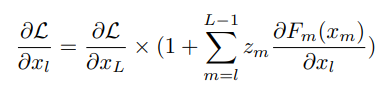
考虑多种语言,有两种策略:1. 为每一种语言单独学习一套参数z;2. 定义一个同一的网络,输入一个语言embedding,得到一套对应的参数z。文中说,虽然策略2能够学习到语言的共性(commonality),但会带来额外 N x d的参数量。
最后,引入对模型层数的监督(层数看似是确定的,但会影响inference的速度)。得到最终的loss。
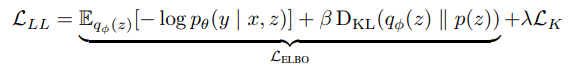
具体实验
略
是否解决的梯度消失问题?
en-de翻译
MLM预训练
多语言机器翻译
KL散度项中不同先验的影响
KL散度在loss中不同的权重影响
隐式的层数 vs 静态的层数















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









