







一、前置知识
条件生成对抗网络(cGANs):条件生成对抗网络(cGAN) - 知乎 (zhihu.com)
对比学习:对比学习(Contrastive Learning),必知必会 - 知乎 (zhihu.com)
二、关于本文
目前研究所处瓶颈及其所面对的问题:
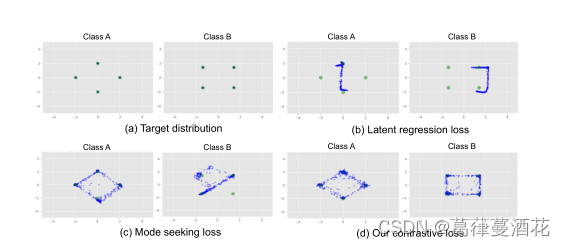
(a)两个不同类别的分布,其中每个类别都是高斯混合模型。
(b)使用潜在回归损失( Latent regression loss:鼓励图像和潜在空间之间的可逆映射)学习到的结果,可以看出误差较大。
(c)Mode seeking loss :通过最大化两个任意图像的不相似性来提高生成多样性,但从上图生成的结果来看,当两个采样的潜在编码(潜在分布特征)之间的距离可能很接近,它们的合成图像不仅被很好的区分,而且根据它最大近似分布的特点学习到新的分布很容易变的偏差极大,也就是说,生成结果只取决于潜在编码(潜在分布特征)而忽略了条件输入。
(d)由本文提出的潜在增广对比损失的学习分布生成的样本,它表现出了极强的无偏差分布,该分布适当地依赖于条件输入和潜在编码(潜在分布特征)。
简单的总结本文所作出的工作:本文工作的核心重点在于,在GAN生成网络开始进行生成工作之前,通过加入类标签的有监督方式进行初步分类,将输入图片的感兴趣部分称为‘positive’或者’正‘区域,同时非感兴趣区域称为‘negative'或者负区域。并近似的将正区域中的点形成一个个的超球体,超球体内正相关超球体外负相关。将对比学习的重点侧重于我们感兴趣的超球体内。
而在此之前cGan的工作其实主要集中于图片的像素级区域的对比与学习,引入超球体的概念是一种增强学习的过程。即插即用也是本文提出方法的一个理论关键点。
具体来看:

应用方法part1:该部分主要完成特征图像的生成,上图中第一部分完成对原始图片中感兴趣部分的混合生成,具体来说z∼N(0,1)即该点所处位置为“P”or"N",之后通过第一次生成得到这一批的类加权图像,之后使用这批类加权图像生成我们GAN网络的特征图片。(图片到图片,翻译为我们想要的目标特征图片),注意在这部分中直接使用了生成器中的编码层作为辅助编码器,即
于
编码层使用相同的代码。

应用方法part2:该部分主要完成类标签的生成,对原始类标签引入超球体的积极或消极的感兴趣区域对比筛别机制,生成新的条件类标签(类标签-条件生成任务的类标签)。注意:由于类条件图像生成任务不需要生成器中编码层,因此我们使用条件判别器的赋值层,这些赋值层也能够编码判别特征。
之后的操作就是cGANs的正常操作。
cGANs结构图:

在理想条件下,生成图片会同时受到类标签与图片潜在分布的多重影响。
三、具体损失公式解读
传统GAN的损失公式:

本文区别于传统GAN引入了条件label即y,则它的损失公式为:

当然这部分的损失只控制生成图片跟贴近于原始图片,为了体现多样性本文提出了第二个损失函数。

通过对之前引入超球体后生成的特征图片进行对比并计算损失, 这就控制了超球体内尽可能相似,超球体外尽可能不相似。使用这种新的损失函数作为正则化项。
上面公式中的即内积被定义为衡量相似性的手段。
最终的损失函数表达为:

对于映射过程中产生的损失:

扩展到本算法中后:


对比传统的MSGAN牺牲真实性换取多样性,BicycleGAN牺牲多样性换取真实性,本文提出的方法在真实性于多样性之间做出了一种较好的平衡。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









