






预训练现在数据量越来越大,模型参数越来越多,烧钱越来越快,但如何高效的筛选优质预训练数据,以便提高目标任务上的表现呢?有没有可以不用重头训练多版预训练对比的机智小妙招?本文也许可以给你一些启发。
《IMPROVING PRETRAINING DATA USING PERPLEXITY CORRELATIONS》,
链接:https://arxiv.org/pdf/2409.05816
作者是 Tristan Thrush, Christopher Potts 和 Tatsunori Hashimoto,来自斯坦福大学计算机科学系。文章的主要内容是提出了一个框架,用于在不进行昂贵的预训练运行的情况下,通过估计困惑度(perplexity)和基准测试性能之间的相关性来选择高质量的预训练数据。
摘要
高质量的预训练数据通常被视为高性能语言模型(LLMs)的关键。然而,由于数据选择实验需要昂贵的预训练运行,对预训练数据的理解进展缓慢。我们提出了一个框架,避免了这些成本,无需我们自己的LLM训练即可选择高质量的预训练数据。我们的工作基于一个简单的观察:许多预训练文本上的LLM损失与下游基准性能相关,选择高相关性的文档是一种有效的预训练数据选择方法。我们构建了一个新的统计框架,以困惑度-基准相关性的估计为中心,并使用来自Open LLM Leaderboard的90个LLMs样本对来自数万个网页域的文本进行数据选择。在160M参数规模的8个基准上的控制预训练实验中,我们的方法在每个基准上都优于DSIR,同时匹配了DataComp-LM中发现的最佳数据选择器,这是一个手工设计的bigram分类器。
1 引言
数据集策划对于训练高质量的大型语言模型(LLMs)越来越重要。随着预训练数据集的增长,从2020年的不到200B个token(Raffel et al., 2020; Gao et al., 2020)增长到今天的240T个token(Li et al., 2024),识别出将带来最佳LLMs的可用数据子集变得至关重要,为了满足这些需求,出现了各种各样的方法(Ilyas et al., 2022; Xie et al., 2023a;b; Engstrom et al., 2024; Everaert & Potts, 2024; Liu et al., 2024; Llama Team, 2024)。然而,数据驱动的数据选择方法通常涉及昂贵的模型重新训练步骤,这限制了它们的有效性,并且没有算法被报告能够一致地击败或匹配手工制作的分类器进行数据选择(Li et al., 2024)。
2 相关工作
为了超越去重、困惑度过滤和手工策划的现状(Laurençon et al., 2022; BigScience, 2023; Abbas et al., 2023; Groeneveld et al., 2024; Soldaini et al., 2024; Penedo et al., 2024; Llama Team, 2024),提出了针对性的方法来过滤预训练数据,以便产生的LLM在给定基准上获得更高的分数。有轻量级方法使用n-gram重叠或嵌入相似性来选择与给定基准数据相似的训练数据。还有一些不太可扩展的方法需要在不同数据混合上训练代理LLMs。
3 问题设置
我们的目标是构建预测预训练数据分布如何影响下游基准性能的预测模型,并用它们来构建更好的语言模型。不幸的是,这项任务具有挑战性且计算成本高昂。在数据建模等范式中采用的标准方法是获得N个不同的预训练分布{pi : i ∈ [N], pi ∈ R+ 0 D},覆盖D ≫ N个域(例如arxiv.org, stackoverflow.com等),预训练并在目标基准上测量模型错误yi ∈ [0, 1],然后拟合一个模型p → y。这种方法需要N次LLM训练运行,规模足够以获得在y上的非随机性能。这可能需要数千万到数亿美元的费用,对于像MMLU这样难度较高的基准,即使是1B参数LLMs的性能通常也不会超过随机机会(Beeching et al., 2023)。
4 方法
我们现在描述我们的方法的细节,首先介绍算法本身及其背后的直觉,然后是更精确和数学化的解释。
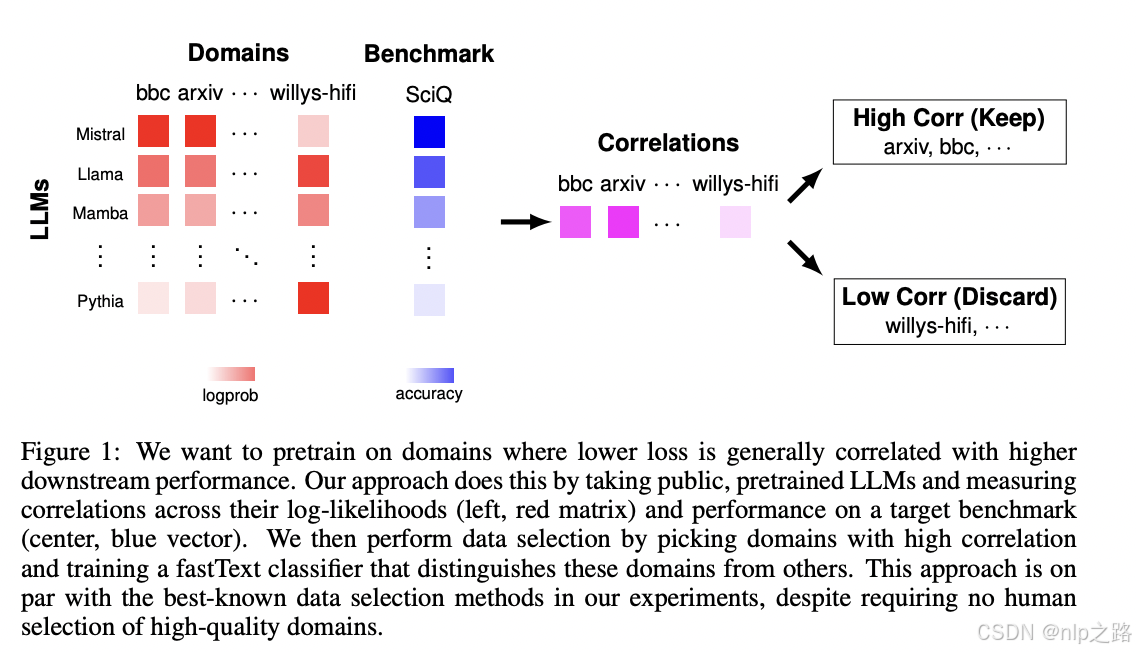
(1)基于Open LLM Leaderboard的样本集合,用多个公开的LLM模型,拿到他们的log-likelihood值和目标benchmark任务的accuracy;(因为观察到模型困惑度越低,下游任务表现越好)

(2)挑选与目标任务高相关性的领域,训fasttext文本二分类器(相关 or 不相关);
(3)用这个分类器去海量数据中筛选符合相关的数据来预训练

5 结果
我们通过三组实验验证了我们预测下游性能和数据选择的方法:首先从头开始预训练160M参数的LLMs来研究我们的主要目标,即选择预训练数据以提高下游性能,然后分析损失预测下游性能的能力,并最后分析损失矩阵X。
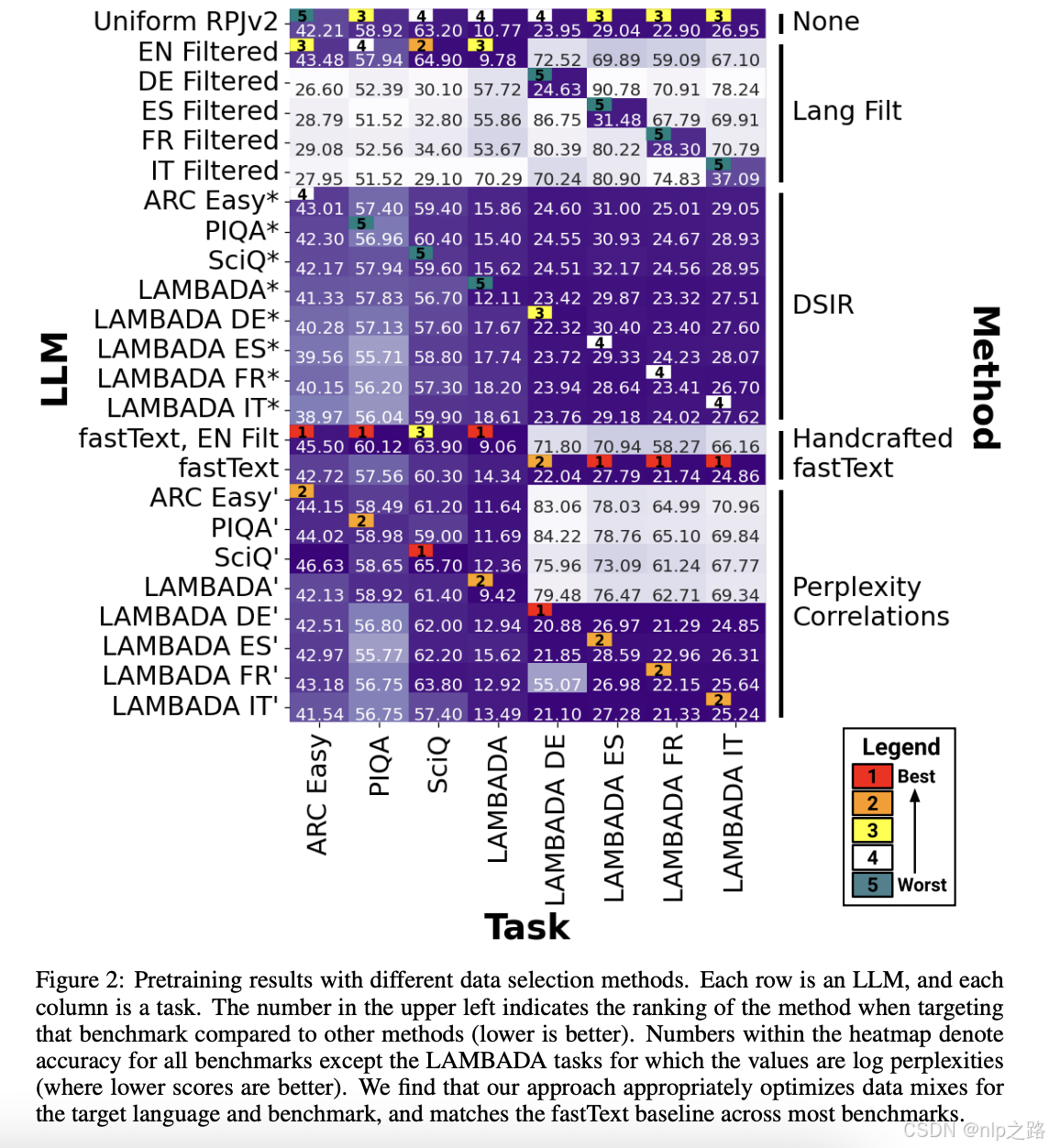
6 预注册的稳健性检查
在小规模实验中,我们的方法与Li等人的调查中领先的方法竞争:一个固定的fastText模型(Joulin et al., 2016),手动增加了最佳的语言过滤。这种方法是启发式的,手工制作的,需要适当的语言过滤与目标基准匹配,以及对优质预训练数据外观的假设。我们的方法不作这些假设,并且随着更多公共模型的发布,我们有更好的数据来估计θ∗,它可能会有所改进。
7 结论
高性能数据选择是否需要精心制作的启发式规则或昂贵的模型训练运行?我们的工作展示了一种可行的替代方法——利用现有的公共模型作为数据选择的信息来源。预训练实验表明,一种简单的基于相关性的数据选择方法可以是有效的,但更广泛地说,我们展示了如何1)使用单指数模型作为下游性能的替代品,以及2)构建将损失与下游性能联系起来的模型,并有效地使用这些替代品进行数据选择。最后,我们提出了在保留数据上进行预注册的扩展实验,以测试报告结果的外部有效性。我们希望这种类型的实验将有助于提高数据选择实验结果的可信度。
欢迎微信扫码关注公众号 nlp之路, 回复LLM, 免费领取LLM相关资料


















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









