







前言
这是卷积的第十二篇文章,主要为大家介绍一下DenseNet,值得一提的是DenseNet的作者也是上一篇卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)论文的作者,即清华的黄高。相比于里程碑式创新的ResNet来讲,DenseNet的作用或许用既往开来来形容是最合适不过了。论文原文地址见附录。
介绍
论文先讲到了先前的网络因为使用了shortcut连接,网络已经变得越来越深了。接着引入了论文要介绍的DenseNet,正是利用了shortcut连接的思想,每一层都将前面所有层的特征图作为输入,最后使用concatenate来聚合信息。实验显示,DenseNet减轻了梯度消失问题,增大了特征重用,大大减少了参数量。
Figure 1是DenseNet的一个组件(dense block),整个网络是由多个这种组件堆叠出来的。可以看到DenseNet使用了concatenate来聚合不同的特征图,类似于ResNet残差的思想,提高了网络的信息和梯度流动,使得网络更加容易训练。
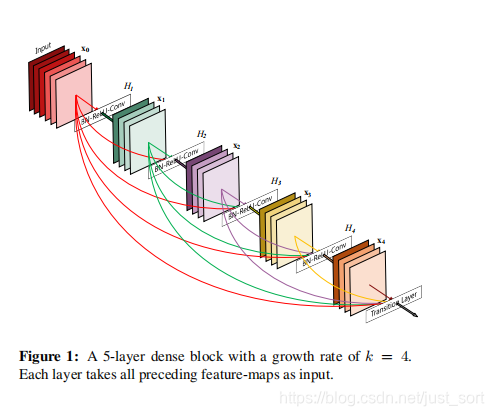
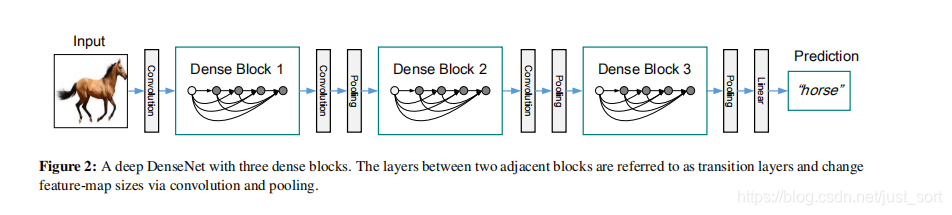
Figure 2展示了使用3个dense block搭建出来的DenseNet网络:
相关工作
-
通过级联来加深网络。
- 80年代的级联结构和DenseNet结构有点相似,但那时的主要目的是为了逐层训练多层感知机。
- 最近,提出使用batch梯度下降训练全连接级联网络。虽然在小数据集上有效,但这个方法最多只适合有几百个参数的网络。
- 何凯明等人提出的ResNet。
-
通过shortcut连接加深网络。
- Highway网络是第一个将网络深度做到100+的,使用了gating mapping。
- ResNet在Highway的基础上,将gating mapping换成了identity mapping。
- Stochastic depth ResNet通过随机dropout掉一些identity mapping来强制学习,这表明,ResNet中有很多冗余层,DenseNet就是受到这个启发来做的。
-
通过加宽网络来使网络更深。
- GoogleNet使用Inception模块加深了网络
- WRN加宽了ResNet
- FractalNet 也加宽了网络
-
提高特征重用。
- 相比于通过加深,加宽网络来增强表示能力,DenseNet关注特征重用。dense架构容易训练,并且参数更少。特征图谱通过 concat 聚合可以增加后面层输入的变化,提高效率。
- Inception 系列网络中也有用
concatenate来聚合信息,但DenseNet更加简单高效。
-
其他工作。
- NIN 将微型 mlp 结构引入 conv 来提取更加复杂的特征。
- Deeply Supervised Network (DSN) 添加辅助 loss 来增强前层的梯度。
- Ladder Networks 在 自动编码器 中引入了横向连接。
- Deeply-Fused Nets (DFNs) 提高信息流。
实现方法
对于一个卷积神经网络,假设输入图像
x
0
x_0
x0。该网络包含L层,每一层都实现了一个非线性变换
H
i
(
.
)
H_i(.)
Hi(.),其中
i
i
i表示第
i
i
i层。
H
i
(
.
)
H_i(.)
Hi(.)可以是一个组合操作,如BN, ReLU, Conv,将第
i
i
i层的输出记作
x
i
x_i
xi。
稠密连接
为了进一步改善网络层之间的信息交流流,论文提出了不同的连接模式:即引入从任何层到所有后续层的直接连接。结果,第 i i i层得到了之前所有层的特征映射 x 0 , x 1 , . . . , x i − 1 x_0,x_1,...,x_{i-1} x0,x1,...,xi−1作为输入: x i = H i ( [ x 0 , x 1 , . . . , x i − 1 ] ) x_i=H_i([x_0,x_1,...,x_{i-1}]) xi=Hi([x0,x1,...,xi−1]),其中 [ x 0 , x 1 , . . . , x i − 1 ] [x_0,x_1,...,x_{i-1}] [x0,x1,...,xi−1]表示特征映射的级联。
复合函数
定义 H i ( . ) H_i(.) Hi(.)为三个连续操作的组合,即: B N + R e L U + C o n v 。 BN+ReLU+Conv。 BN+ReLU+Conv。
池化层
DenseNet使用了
2
×
2
2\times 2
2×2的平均池化做特征下采样。
增长率
当每个
H
i
H_i
Hi都产生
k
k
k个特征映射时,它表示第
i
i
i层有
k
0
+
k
∗
(
i
−
1
)
k_0+k*(i-1)
k0+k∗(i−1)个输入特征,
k
0
k_0
k0表示输入层的通道数。DenseNet与已存在架构不同之处在于DenseNet可以有很窄的层,例如:
k
=
12
k = 12
k=12。其中参数
k
k
k称为网络的增长率。下表展示了不同深度的DenseNet网络结构,其中
k
=
32
k=32
k=32:
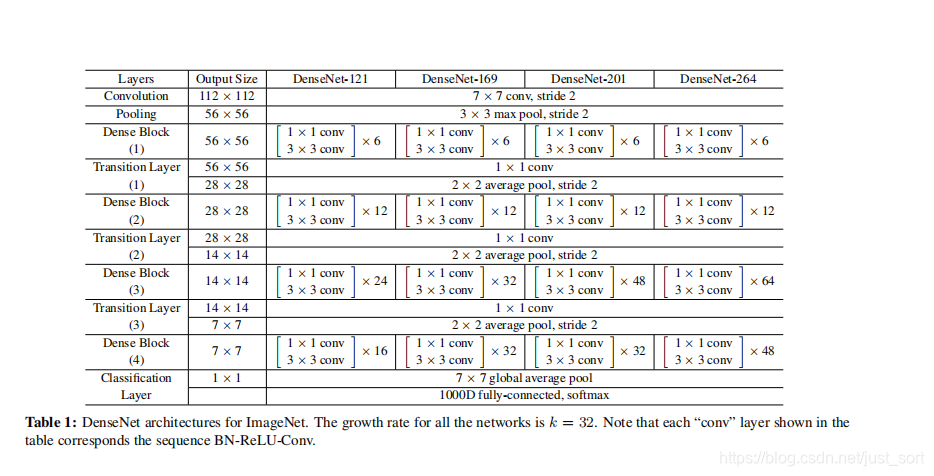
为什么DenseNet结构有效?
对此的一种解释是DenseNet中的每个层都可以访问对应块中所有前面的特征映射,因此可以访问网络的“集体知识”。我们可以将特征映射看作网络的全局状态。每个层将自己的
k
k
k个特征映射添加到这个状态。增长速度控制着每一层新信息对全局状态的贡献。全局状态一旦写入,就可以从网络中的任何地方访问,并且与传统网络体系不同,不需要逐层复制它。
瓶颈层
虽然每一层只产生
k
k
k个输出特征映射,但它通道具有更多的输入。有文章指出,在每个
3
×
3
3\times 3
3×3卷积之前可以引入
1
×
1
1\times 1
1×1卷积层作为瓶颈层,以减少输入特征映射的数量,从而提高计算效率。实验发现这种设计对于DenseNet特别有效,并将具有瓶颈层的网络称为DenseNet-B,即具有BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)组件的的
H
i
H_i
Hi。
压缩
为了进一步提高模型的紧凑性,可以减少过度层上的特征映射的数量。如果一个dense block包含m个特征映射,可以让其紧跟着的变化层生成
θ
×
m
\theta \times m
θ×m个输出特征映射,其中
0
<
θ
<
=
1
0<\theta<=1
0<θ<=1作为压缩因子。当
θ
=
1
\theta=1
θ=1时,跨转换层的特征映射的数量保持不变。
实验
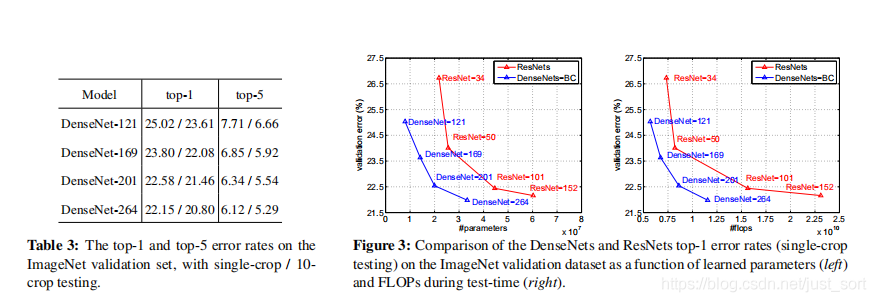
通过Table 2可以看出DenseNet在准确率和参数量上取得了较好的平衡,精度上全面超越ResNet网络。
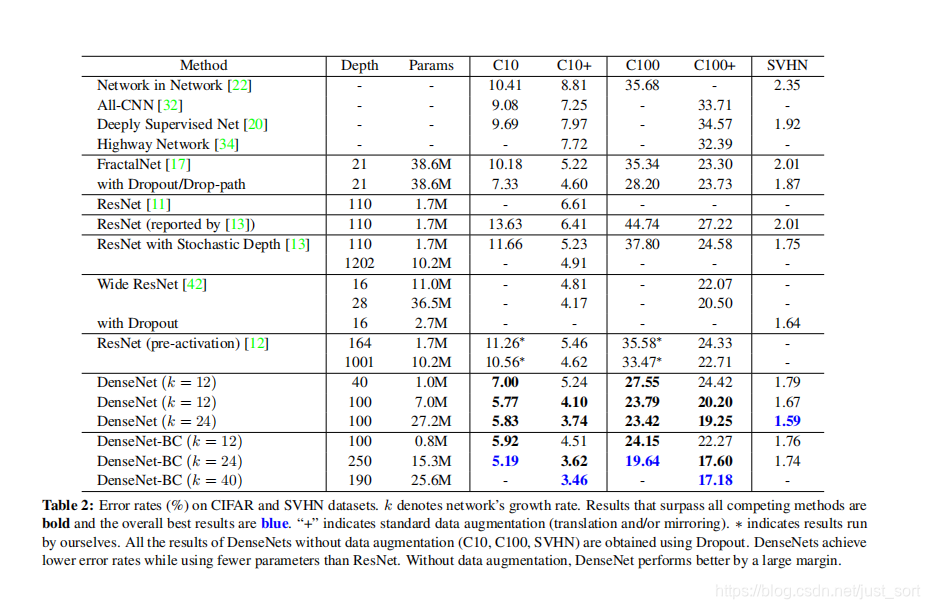
Figure 3对比了ResNet和DenseNet参数量和FLOPS是如何影响测试错误率的,可以看出相同准确率时DenseNet 的参数更少,推理时的计算量也更小。
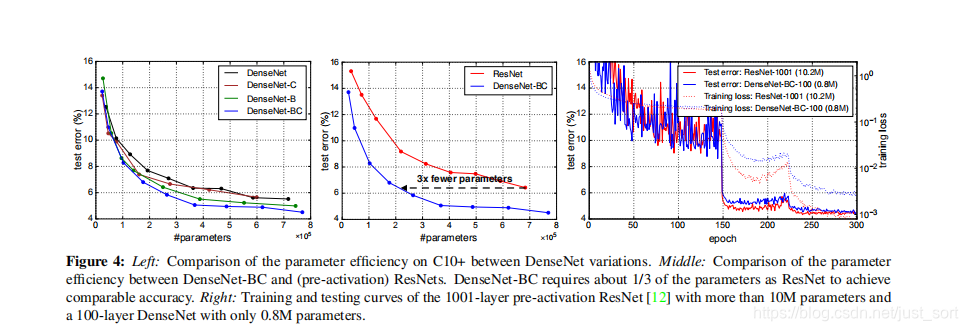
从Figure 4可以看出,在相同性能下DenseNet的参数量是ResNet的三分之一;1001层的pre-activation ResNet(参数为10M)的性能和100层的DenseNet (参数为0.8M)相当。说明DenseNet的参数利用效率更高。
结论
这篇论文论文提出了一个新的网络结构DenseNet,解决了ResNet遗留的网络层冗余的问题,引入了具有相同特征映射大小的任意两个层之间的直接连接。我们发现,DenseNet可以自然地扩展到数百个层,且没有表现出优化困难。DenseNet趋向于随着参数量的增加,在精度上也产了对应的提高,并没有任何性能下降和过拟合的情况。但是根据天下没有免费的午餐定理,DenseNet有一个恐怖的缺点就是内存占用极高,比较考验硬件,另外DenseNet和ResNet一样仍存在调参困难的问题。
附录
- 论文原文:https://arxiv.org/pdf/1608.06993.pdf
- 参考:https://www.cnblogs.com/zhhfan/p/10187634.html
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









