







原创:杨其泓
一、前言
FaceNet是一个十分经典的人脸识别模型,并且具有较好的性能,但要实现使用自己的数据进行人脸识别,还需要对模型进行重新训练。本文将介绍跑通一个简单FaceNet的全部流程,以及踩坑记录。
二、方案技术路线
- 人脸检测:使用 Dlib 中预先训练的模型检测面部;
- 人脸校准:使用 Dlib 的实时姿势估计与 OpenCV 的仿射变换来尝试使眼睛和下唇在每个图像上出现在相同位置;
- 卷积网络:使用深度神经网络把人脸图片映射为 128 维单位超球面上的一个点;
- 分类:使用三元损失函数对每张图片对应的超球面的点(128维向量)比较相似度以此进行分类。
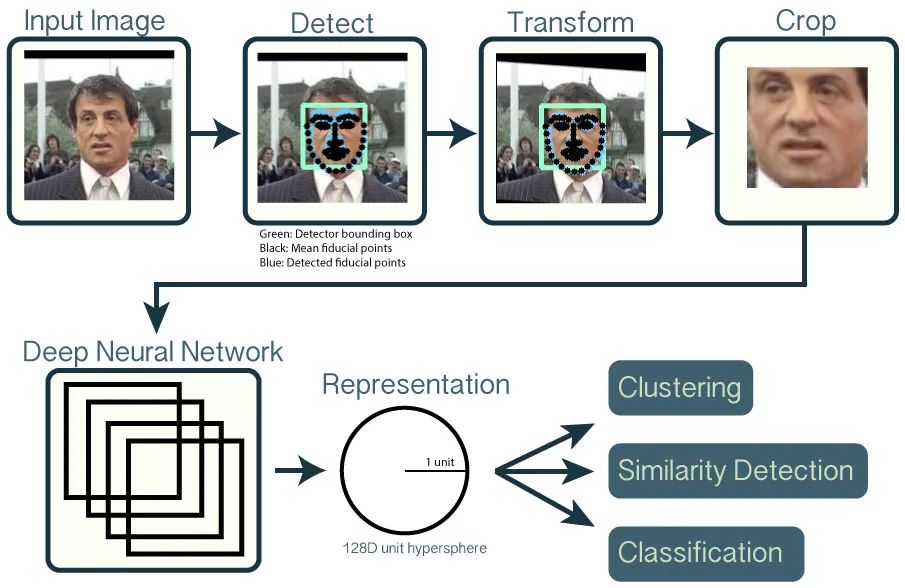
图片来源:https://cmusatyalab.github.io/openface/
三、参考
3.1 论文
FaceNet: A Unified Embedding for Face Recognition and Clustering.
论文链接:https://arxiv.org/abs/1503.03832
3.2 代码
Github代码链接:https://github.com/foamliu/FaceNet
3.3 数据
-
训练集
CelebFaces Attributes Dataset (CelebA) 是一个大型的人脸数据集,有10,177个身份和202,599张人脸图像。

数据链接:
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
Celeba数据集是香港中文大学的公开数据集,所以支持百度网盘下载!选择Baidu Drive即可将数据集转存至自己的网盘,Celeba数据集大约有22个G(解压后24左右),所以最好要弄个百度网盘SVIP账号再下。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









