






简介
Chroma 词向量数据库是一个用于自然语言处理(NLP)和机器学习的工具,它主要用于词嵌入(word embeddings)。词向量是将单词转换为向量表示的技术,可以捕获单词之间的语义和语法关系,使得计算机能够更好地理解和处理自然语言。
Chroma 词向量数据库的主要功能和用途包括:
-
语义表示和相似度计算: 将单词转换为向量表示后,可以计算单词之间的相似度,找到在语义上相关的单词,从而支持词义的推断和理解。
-
词语聚类和分类: 使用词向量可以对单词进行聚类或分类,将具有相似含义的单词归为一类,从而帮助组织和理解词汇。
-
文本分类和情感分析: 词向量可以作为文本分类和情感分析任务的特征表示,有助于机器学习模型更好地理解文本内容和推断情感倾向。
-
推荐系统: 在推荐系统中,词向量可以用于理解用户的偏好和内容的语义,从而提供更准确的推荐。
-
语言生成和机器翻译: 词向量在语言生成和机器翻译任务中也有广泛应用,可以帮助模型生成更连贯和语义合理的文本。
Chroma 词向量数据库可能提供多种预训练模型,这些模型可以根据需求进行选择和应用,以支持各种自然语言处理任务。总的来说,它为研究人员和开发者提供了一个有用的工具,使他们能够利用词向量来处理自然语言数据并改善各种NLP任务的性能。
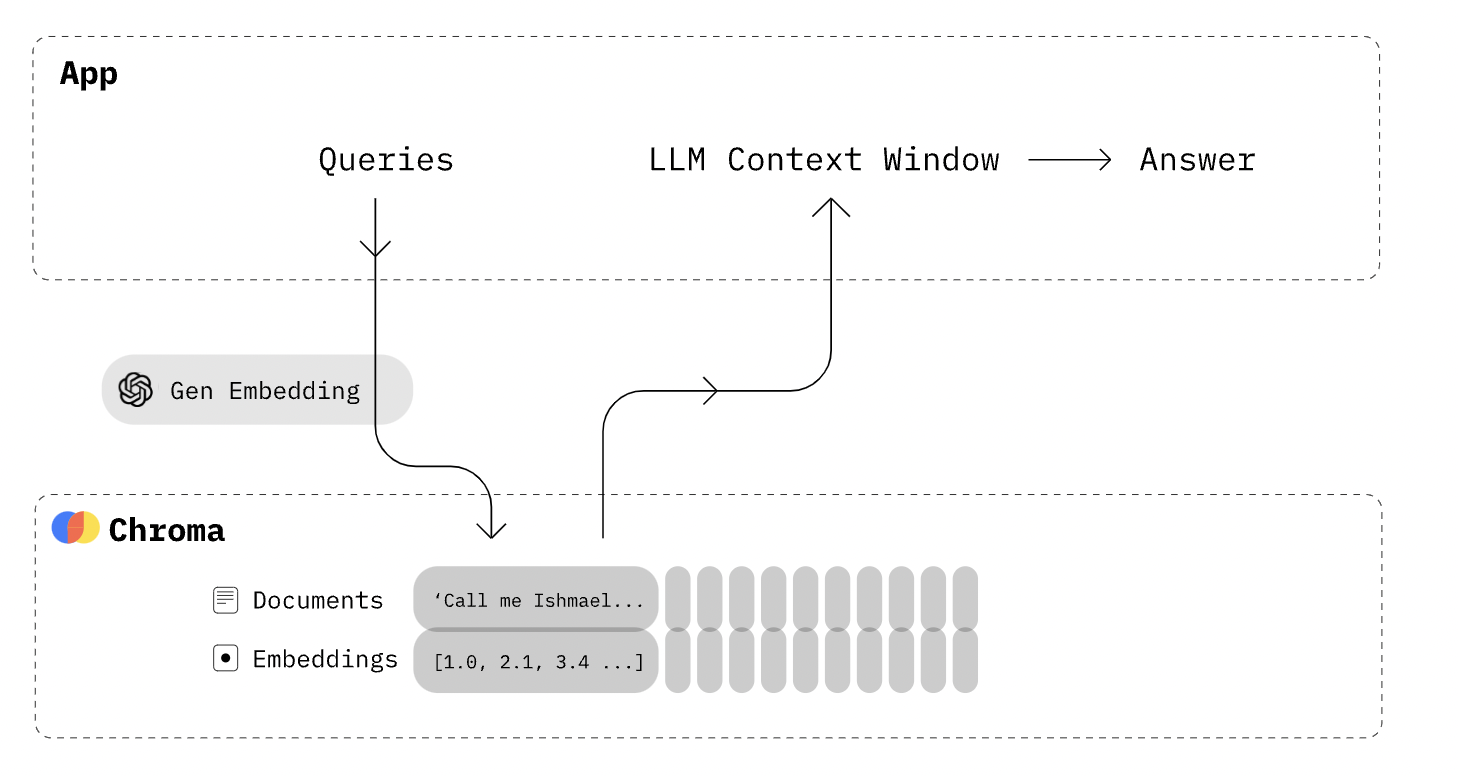
代码实践
安装chromadb
pip install chromadb创建chromadb
import chromadb
chroma_client = chromadb.Client()或者, 你想要把数据存放在磁盘上。
chroma_client = chromadb.PersistentClient(path="data")创建collection
collection是您存储嵌入、文档以及任何额外元数据的地方。您可以使用名称创建一个collection.
collection = chroma_client.create_collection(name="my_collection")或者
collection = chroma_client.get_or_create_collection(name="my_collection")改变距离函数,默认是L2
collection = client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"} # l2 is the default
)| Distance | parameter | Equation |
|---|---|---|
| Squared L2 | 'l2' | |
| Inner product | 'ip' | |
| Cosine similarity | 'cosine' |
存储embedding, 文本,元数据,和id,
collection.add(
embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)根据词嵌入取数据
results = collection.query(
query_embeddings=[[1.2, 2.3, 4.5]],
n_results=2
)根据词嵌入和关键字取数据
results = collection.query(
query_embeddings=[[1.2, 2.3, 4.5]],
where_document={"$contains": "another"}
n_results=2
)根据id取数据
results = collection.get(
ids=["id1"]
)默认Chroma使用hugggingface里的all-MiniLM-L6-v2作为词向量模型。支持以下词向量模型
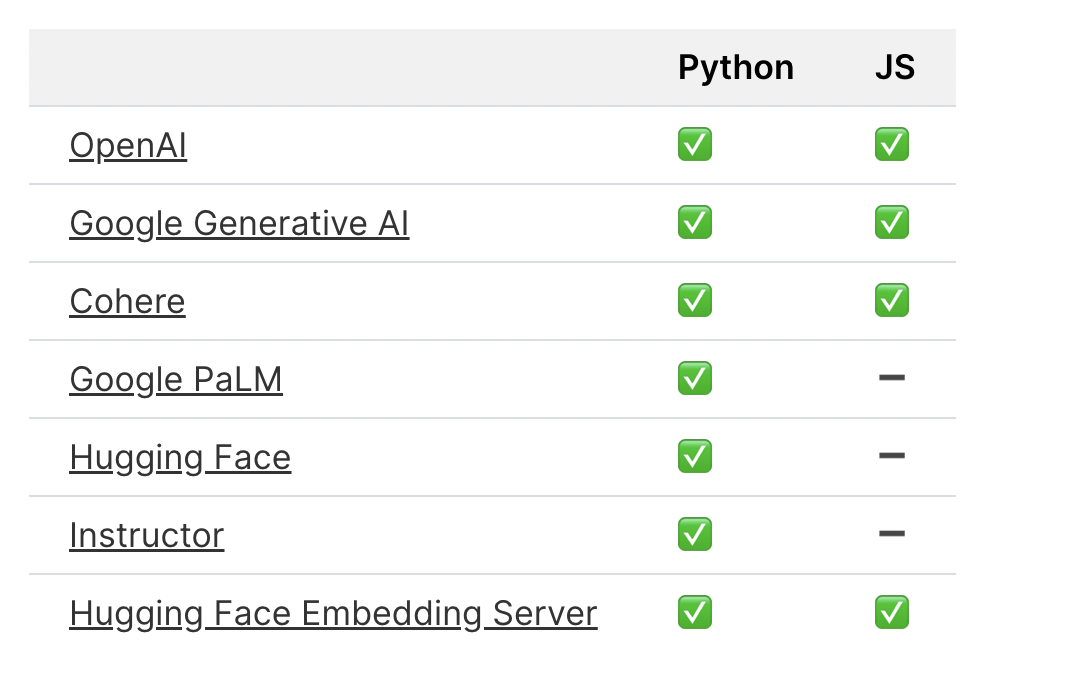
如果你不想要,直接用你自己的模型,就是在存数据之前调用你的模型把文本转成词向量。
比如我用tensorflowhub里面的。
import tensorflow as tf
import tensorflow_hub as hub
def get_vectors(docs):
url = "./ml/nnlm_embedding"
s_embedding = hub.KerasLayer(url, input_shape=[], dtype=tf.string)
doc_vectors = s_embedding(docs)
return doc_vectors参考


















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











