







本文是我 LLM 系列的第三篇,重点讲解:为什么语言模型推理会分成两个阶段:Prefill 和 Decode?
我们不仅会回答这个“为什么”,还会带你走进 prefill 阶段的内部机制,搞懂 attention 的计算细节、KV Cache 是如何初始化的、为什么 prefill 计算量这么大。
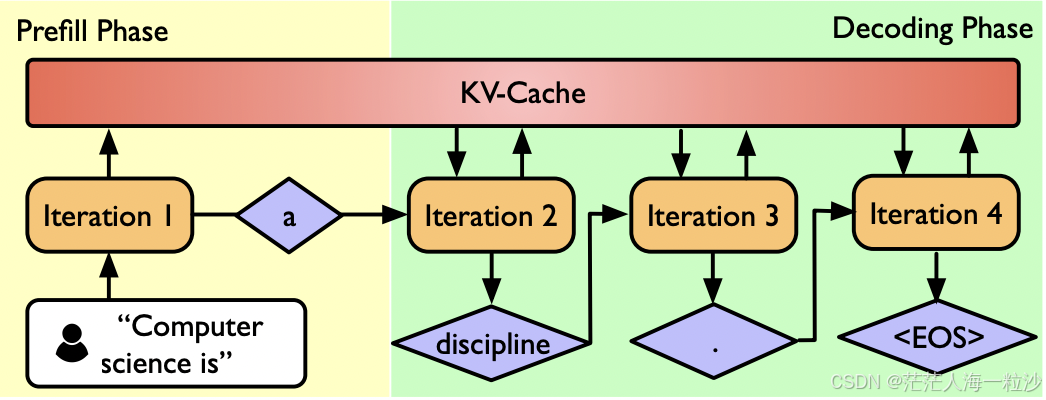
一句话解释:Prefill 和 Decode 的分工
大语言模型生成文本的过程本质上是给定上下文,逐词预测下一个词。
但在实现上,这个过程被明确地分成两个阶段:
| 阶段 | 目的 |
|---|---|
| Prefill | 模型读取并“理解”你输入的所有上下文 |
| Decode | 模型基于已有信息一步步生成回复 |
为什么不能用一个阶段做完?
因为输入和输出的计算特性完全不同:
-
输入 prompt 是完整的、一次性提供的,适合并行计算。
-
输出 token 是未知的,只能一个一个推理,必须串行。
这种“数据形态差异”导致我们不得不把它们拆成两个阶段,并用不同方式处理。
Prefill:模型如何“理解”你输入的 prompt?
什么是 prefill?
Prefill 阶段是语言模型推理中的第一个步骤,它负责处理你输入的所有上下文内容(prompt),为后续生成打下基础。
比如你问模型一句话:
“请解释一下 Transformer 的原理。”
这句话会被 tokenizer 编码为一串 token,比如 ["请", "解释", "一下", "Trans", "##former", "的", "原理", "。"]。
然后这些 token 会进入 Transformer 模型进行前向传播。重点来了 👇
Prefill 中模型内部到底发生了什么?
Step 1:Embedding 输入
-
每个 token 会映射成一个向量(embedding),形状为
[batch_size, seq_len, hidden_dim]
Step 2:Self-Attention 的全量计算
-
输入是完整的上下文,因此模型会执行一次完整的 masked self-attention。 不懂masked self-attention 可以参考这一篇博客
对于位置 i 的 token,会计算它和前面所有位置的注意力(包括自己):
其中:
-
是当前 token 的 query 向量
-
是它之前所有 token 的 key/value 向量
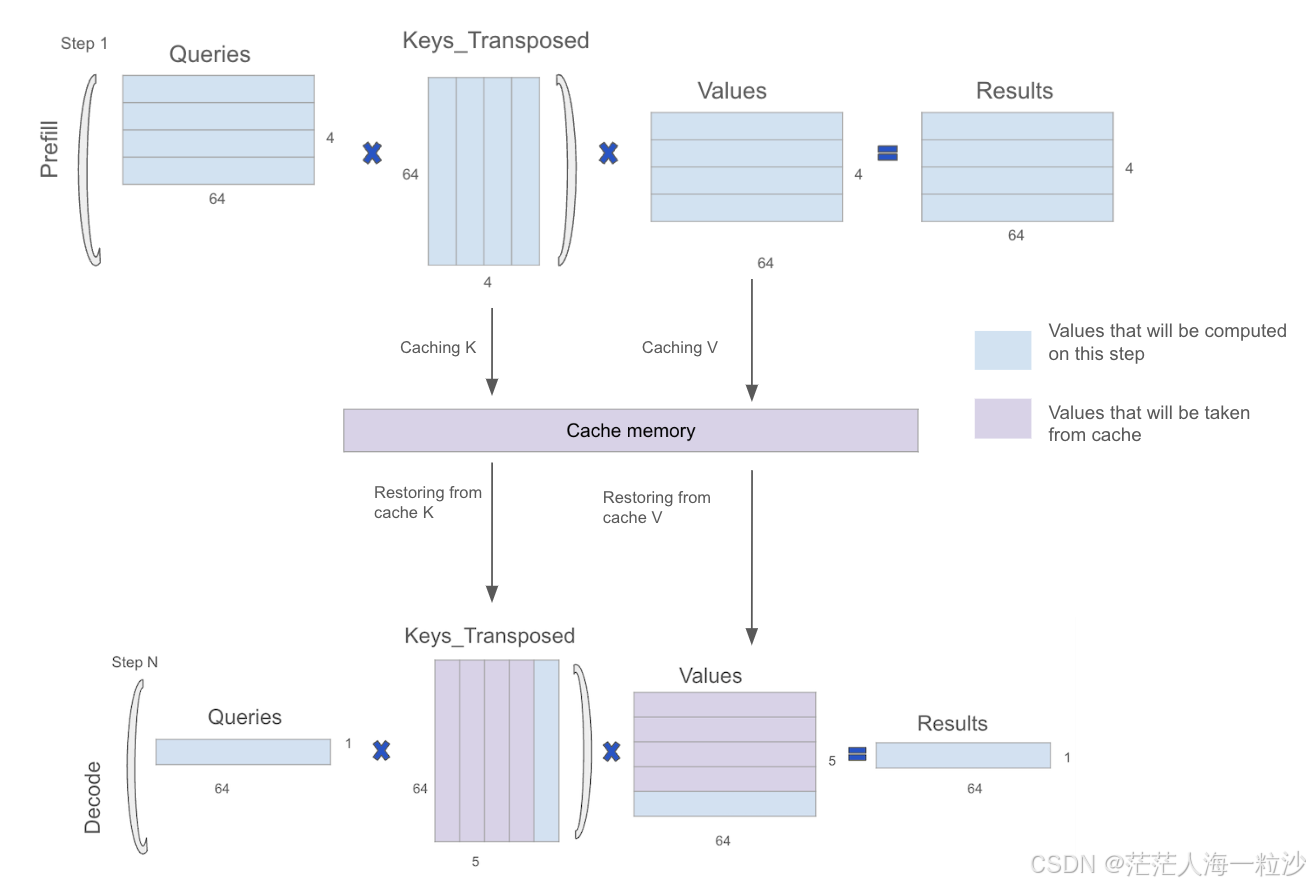
Step 3:生成 KV Cache
-
每层 Transformer 都会把每个 token 的 K 和 V 存下来,形成 KV Cache:
KV Cache = [K₁, K₂, ..., Kₙ], [V₁, V₂, ..., Vₙ]
这个 Cache 会在 decode 阶段被反复使用,避免重复计算。
为什么 prefill 的计算成本那么高?
让我们做个简单对比:
| Prefill | Decode(单步) | |
|---|---|---|
| 处理 token 数 | 全部 prompt(如几百) | 1 个 |
| Attention 计算 | 全 attention matrix | 只看已有 KV |
| 是否可并行 | ✅ 是 | ❌ 否(必须串行) |
| 计算资源 | 重 | 轻 |
Prefill 最大的特点是:
需要 “每个 token 与前面所有 token 做 attention”
不能复用 KV Cache(因为是第一次建立)
Prefill 是典型的 compute-bound 阶段:
-
大量矩阵乘法和 attention 计算主导性能瓶颈
-
GPU 的算力利用率很高,但内存带宽压力较小
因此如果你的 prompt 很长,prefill 阶段就会非常耗时。很多模型响应慢,不是生成慢,而是 prompt 处理慢。
Decode:token-by-token 地生成输出
在 prefill 之后,模型已经建立了一个完整的 KV Cache,可以开始逐步生成 token。
每次 decode 只需要:
-
把最新生成的 token 输入进去
-
拿之前的 KV Cache 来做 attention
-
预测下一个 token
Decode 是典型的 memory-bound 阶段:
-
每生成一个 token,都需要访问所有历史的 KV Cache(多层、多头)
-
计算量小,但内存带宽压力大
-
特别在 batch size 小、生成序列长的场景,GPU 利用率会很低
👉 如果你还不熟悉 decode 阶段和 KV Cache 的运作机制,强烈推荐先阅读我这篇:KV Cache 详解:新手也能理解的 LLM 推理加速技巧。那里详细讲了 decode 阶段是如何通过缓存加速推理的。
拆分 Prefill 和 Decode 是“推理效率最大化”的关键
我们回到标题的问题:
为什么 LLM 推理要分成 Prefill 和 Decode?
因为这两个阶段的输入特性和计算方式本质不同:
| 区别点 | Prefill | Decode |
|---|---|---|
| token 来源 | 用户完整输入 | 模型每次只生成一个 |
| 是否可并行 | 是(全部 token 并行) | 否(串行生成) |
| 是否用 KV Cache | 否(此阶段生成 KV Cache) | 是(复用之前生成的 Cache) |
| 计算消耗 | 高,尤其是长 prompt | 单步小,但生成过程长 |
因此,拆成两个阶段是为了精准优化每一步的计算路径,比如:
-
Prefill 可用 FlashAttention 等并行技术提升性能
-
Decode 可用 KV Cache、speculative decoding 等加速生成
Prefill vs Decode 的性能瓶颈差异
在推理过程中,Prefill 和 Decode 阶段不仅在结构上不同,在性能瓶颈上也大相径庭:
| 阶段 | 特点 | 性能瓶颈 | 原因 |
|---|---|---|---|
| Prefill | 一次处理整个输入序列 | Compute-bound | 多 token 并行计算,Attention + MLP 计算密集 |
| Decode | 每次生成一个 token,逐步执行 | Bandwidth-bound | 每次要读取大量 KV Cache,但计算量小,等数据成为瓶颈 |
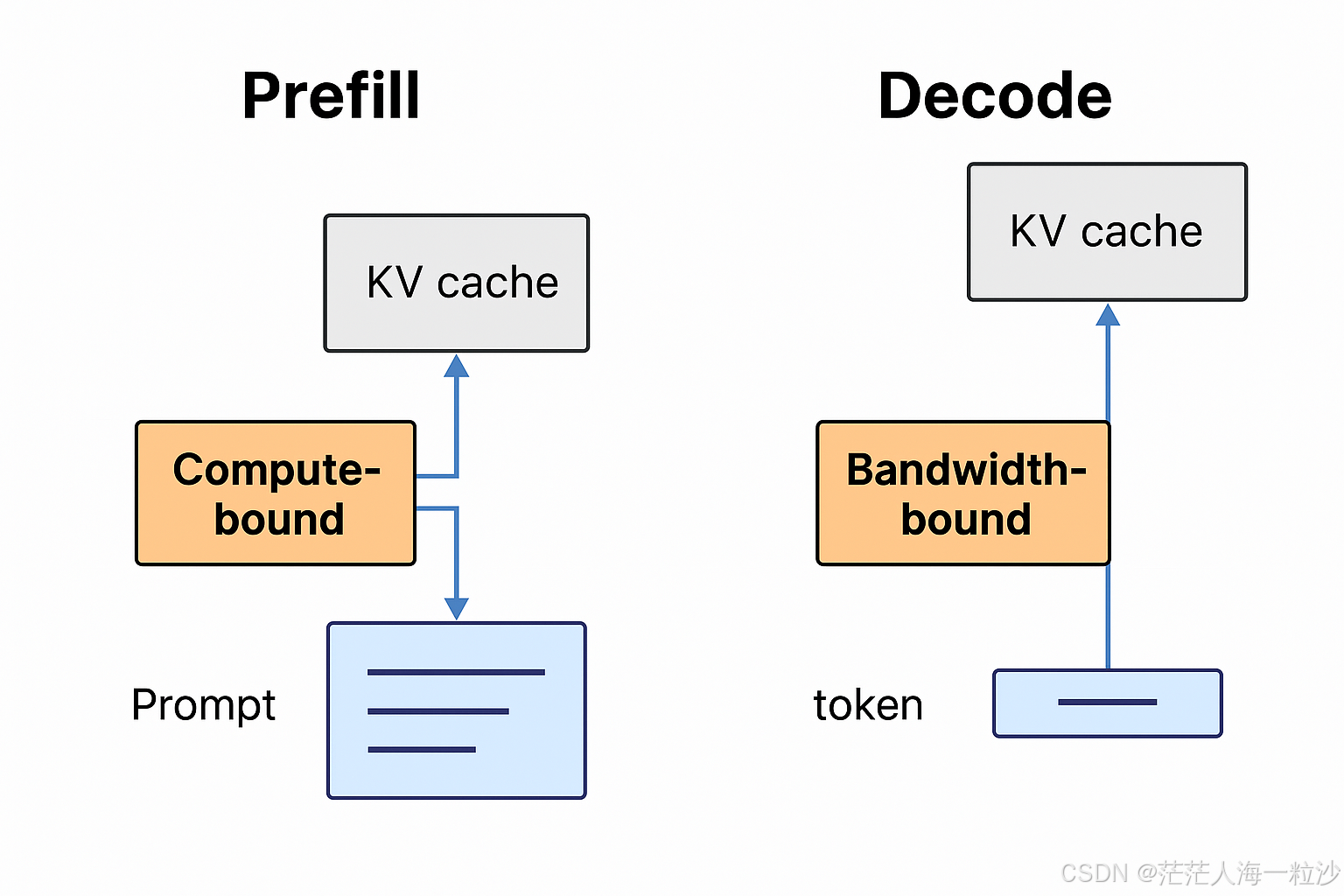
为什么 Decode 会是 Bandwidth-bound?
在 Decode 阶段,虽然只生成一个新 token,但为了计算它的注意力得分,需要加载 全部历史 token 的 KV Cache。这意味着:
-
每层都要从 GPU 内存中读取大量数据;
-
实际计算(比如 Q × K^T)规模却很小;
-
导致 GPU 大量时间都在等内存传输,而不是在计算。
这就是典型的 Bandwidth-bound 场景 —— 内存带宽成为限制性能的关键因素,而不是算力本身。
那 Memory-bound 又是什么?
容易混淆的是 “memory-bound”,但它和 bandwidth-bound 有所不同:
| 类型 | 具体含义 | 常见表现 |
|---|---|---|
| Compute-bound | 受限于计算单元(ALU、CUDA 核心等) | GPU 计算占满 |
| Bandwidth-bound | 受限于 访问速度:内存太慢,等数据成为瓶颈 | GPU 闲着在等内存 |
| Memory-bound | 受限于 内存容量,模型或缓存太大放不下 | OOM / 频繁调度数据 |


















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











