







 这篇博客介绍了显著目标检测(SOD)领域,特别是RGB-D数据的应用,如立体匹配、图像理解等。近年来,深度学习模型在融合RGB图像和深度图以提升SOD性能方面取得进展。文章详细讨论了不同类型的模型(传统/深度、单流/多流),融合策略(早期、多尺度、后期)以及注意力机制。同时,列举了多个代表性工作和数据集,并提出了评估指标。
这篇博客介绍了显著目标检测(SOD)领域,特别是RGB-D数据的应用,如立体匹配、图像理解等。近年来,深度学习模型在融合RGB图像和深度图以提升SOD性能方面取得进展。文章详细讨论了不同类型的模型(传统/深度、单流/多流),融合策略(早期、多尺度、后期)以及注意力机制。同时,列举了多个代表性工作和数据集,并提出了评估指标。
论文链接:https://arxiv.org/abs/2008.00230
仓库链接:https://github.com/taozh2017/RGBD-SODsurvey
介绍
显著目标检测(Salient Obejct Detection)是模拟人类视觉感知系统来定位场景中最吸引人的目标,已被广泛应用于各种计算机视觉任务中。
显著目标检测在现实中的应用有:立体匹配(stereo matching)、图像理解(img understanding)、共显著性检测(co-saliency detection)、动作识别(action recognition)、视频检测和分割(video detection and segmentation )、语义分割(semantic segmentation)等等。
在过去的几年中SOD领域取得了重大进展,但是在面临复杂的背景或场景中不同的光照条件等挑战因素时,深度图(depth maps)是克服这些挑战的一种方法,他为RGB图像补充了空间信息,并且由于深度传感器的大量可用性而变得更容易获取。
早期的SOD模型秦香与提取手工特征(handcrafted features)然后融合RGB图像和深度图。
最近,各种深度学习的模型侧重于利用有效的多模态相关性和多尺度层次信息来提高SOD的性能。
下图为深度学习模型在SOD领域发展的时间表:
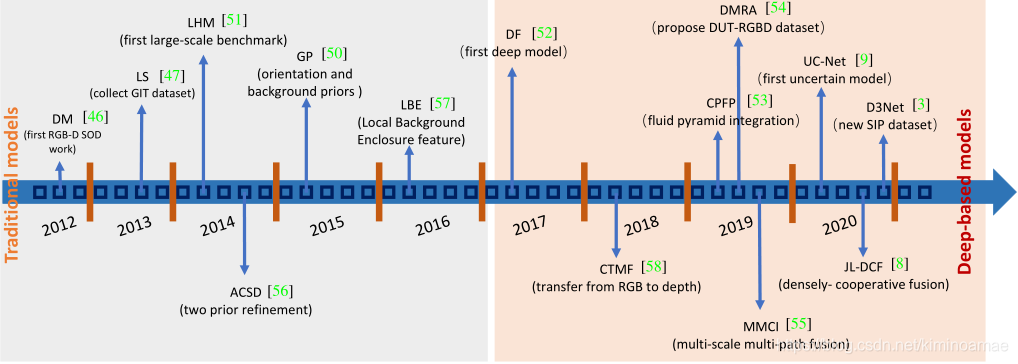
基于RGB-D的SOD模型的不同角度:
- 传统/深度模型:从特征提取角度来看
- 融合模式:在SOD任务中,有效融合RGB和深度图像是非常重要的,这个角度主要解释不同的融合策略的有效性。
- 单流/多流模型:从模型参数的角度考虑这个问题。单流可以保存参数,但是最终结果可能不是最优的,多流可能需要更多参数。因此,从这个角度了解不同模型计算量和精度之间的平衡。
- 注意力模块:注意力机制已经广泛运用于包括SOD在内的各种视觉任务。
1. 传统/深度模型
传统模型:
通过使用深度线索,几个有用的提示(如边界提示,形状属性,表面法线等)能用来增强复杂场景中显著对象的识别。早期的工作侧重于对从RGB图像和深度图生成的布局和形状特征之间的交互进行建模。
深度模型:
由于手工特征的表单能力有限,传统模型的SOD性能不能令人满意,因此,一些研究已经转向了深度神经网络来融合RGB-D数据。这些模型可以学习高级表示,以探索RGB图像和深度线索之间的复杂相关性,从而提高SOD的性能。下面是一些具有代表性的作品:
DF
提出一种新的卷积神经网络,将不同的低层显著性线索整合到层次特征中,从而有效地定位RGB-D图像中的显著区域。这是第一个基于CNN的RGB-D SOD模型。但是这个模型只利用了浅层结构来学习显著图。
PCF
提出了一个互补感知模块来集成跨模态和跨层次的特征表示,它可以通过明确使用跨模态/层次监督来有效利用互补信息,以减少融合模糊度。
CTMF
使用计算模型从RGB-D场景中识别显著对象,使用中枢神经系统学习RGB图像和深度线索的高级表示,同时利用互补关系和联合表示,此外,该模型将模型的结构从源域(即RGB图像)转移到目标域(即深度图)。
CPFP
提出了一种对比度增强的网络来产生增强的特征,并提出了一种流体金字塔集成模块来以分层的方式有效地融合跨模态信息。此外,考虑到深度线索易受噪声影响的事实,提出了一种特征增强模块来学习增强的深度线索以提高SOD的性能。值得注意的是,这是一个有效的解决方案。
UC-Net
提出了一种基于概率RGB-D的SOD网络,通过条件变分自动编码器(via conditional variational autoencoders即VAEs)来模拟人类标注的不确定性。他通过在学习的潜在空间中采样,为每个输入图像生成多个显著图。这是第一个研究基于RGB-D的SOD不确定性的工作,并受到数据标记过程的启发。该方法利用不同的显著图来提高最终的SOD性能。
2. 融合模型
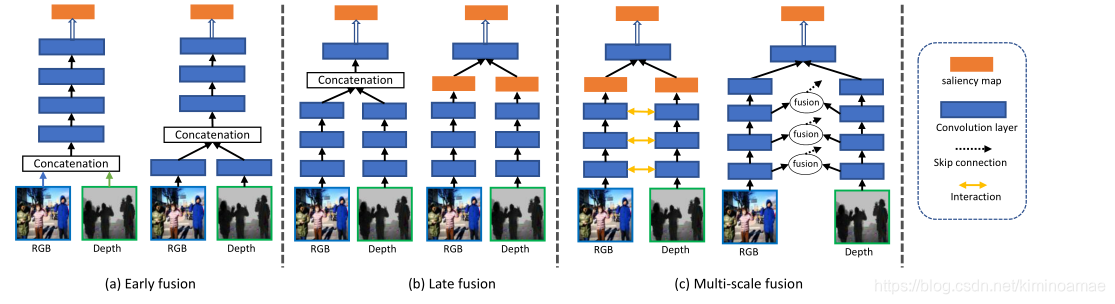
对基于RGB-D的SOD模型,有效融合RGB图像和深度图非常重要。现有的融合策略可以分为三类:早期融合,多尺度融合,晚期融合。每个融合策略提供如下细节:
早期融合
早期融合的方法可以遵循两条路之一
- RGB图像和深度图被直接集成,以形成四通道输入。这被表示为"input fusion"
- RGB和深度图像首先被馈送到每个独立的网络中,并且他们的低级表示被组合为联合表示,然后被馈送到后续的网络中,用于进一步的显著图预测。这被称为“early feature fusion”
后期融合
基于后期融合的方法还可以进一步分为两大类:
- 采用两个并行的网络分别学习RGB和深度数据的高级特征,并将其连接起来,然后用于生成最终的先属性预测。这被称为"later feature fusion"
- 使用两个并行网络来获得RGB图像和深度线索的独立显著图,然后将这两个显著图连接起来已获得最终预测图。这杯称为"late result fusion"
多尺度融合
为了有效地探索RGB图像和深度图之间的相关性,几种方法提出了多尺度融合策略。这些模型可以分为两类:
第一类学习跨模态交互,然后将他们融合到一个特征学习网络中。比如将RGB图像和深度图与跨模态交互模块相结合。这种方法将跨模态交互引入到多个层次中,这可以为增强深度流的学习提供额外的梯度,并使得能够探索低级和高级表示之间的互补性。
第二类在不同的层中融合了RGB图像的特征和深度图,然后将他们继承到解码器网络中(如skip connection),以产生最终的显著检测图,一些代表性的作品如下:
ICNet
提出了一种信息转换模块,以交互方式转换高级特征。该模型引入跨模态深度加权组合块,利用不同层次的深度特征增强RGB特征。
DPANet
使用门控多模块注意力(GMA)模块来利用长层相关性。GMA模块可以通过利用空间注意力机制来提取最有区别的特征。此外,该模型利用门函数控制跨模态信息的融合率,可以减少不可靠的深度线索带来的影响。
BiANet
采用多尺度双边注意力模块(MBAM)在多个层面捕捉更好的全局信息
JL-DCF
将深度图像视为彩色图像的特例,并使用共享的CNN进行RGB和深度特征提取。他还提出了一种密集合作的策略,以有效地组合从不同模态中学习到的特征。
BBS-Net
使用分叉主干策略(BBS)将多级特征表示拆分为教师和学生特征,并开发深度增强模块(DEM)从空间和通道属兔探索深度图中的部分信息。
不同融合策略的流程图
不同融合策略的流程图如下图:
3. 单流/多流模型
单流模型(Single-steam Models)
单流模型专注于单流架构实现显著性预测,这些模型往往在输入通道或特征学习部分融合RGB图像和深度信息。
MDSF采用多尺度判别显著性融合框架作为SOD模型,其中计算三个层次的四种类型特征,然后融合以获得最终的显著性图。
BED利用CNN架构集成自下而上和自上而下的SOD信息,该架构还集成了多种功能,包括背景围栏分布(background enclosure distribution即BED)和低水平深度图,来提高SOD的性能。
PDNet使用辅助网络提取基于深度的特征,该辅助网络充分利用深度信息来辅助主流网络。
多流模型(Multi-stream Models)
双流模型(Two-stream models)由分别处理RGB图像和深度线索的两个独立分支组成,并且通常生成不同的高级特征或显著图,然后将他们合并到两个流的中间阶段或末端。值得注意的是,最近的基于深度学习的模型中,利用了这种双流体系结构,其中几个模型捕获了RGB图像和跨多个层的深度线索之间的相关性。此外,一些模型利用多流结构,然后设计不同的融合模块来有效地融合RGB和深度信息。
4. 注意力模块
现有的基于RGB-D的SOD方法通常使用提取的特征同等地对待所有的区域,而忽略了不同区域对最终预测图的贡献不同的事实。这些方法很容易受到杂乱背景的影响。此外,一些方法要么将RGB图像和深度图视为具有相同的状态,要么过度依赖深度信息。这使得他们无法考虑不同领域(RGB图像或深度线索的重要性)。为了克服这个问题,一些方法引入了注意力机制来衡量不同区域或领域的重要性。
ASIF-Net使用交织融合从RGB图像和深度线索中捕获互补信息,并通过深度监督的注意力机制来加权显著区域。
AttNet引入用于区分显著对象和背景区域的注意力图,以减少一些低质量深度线索的负面影响。
TANet使用自上而下和自下而上试图中的RGB图像和深度图构建多模态融合框架。然后,引入了一个通道式注意力模块,以有效地融合来自不同模式和层次的补充信息。
RGB-D数据集
下表总结了九个流行的RGB-D数据集
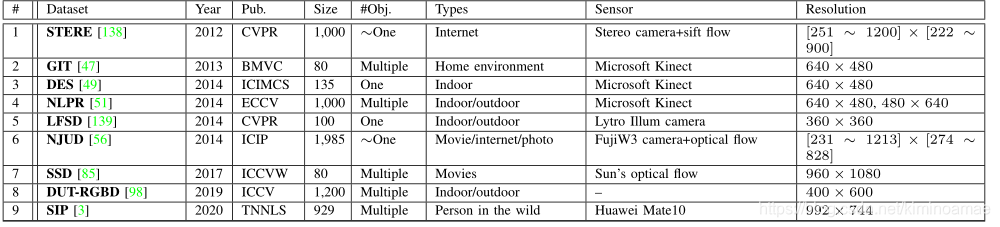
STERE收集了1260幅立体图像,每幅图像中最显著的对象由三个用户标记,然后根据重叠的显著区域对所有带标记的图像进行分类,并选择前1000幅图像来构建最终的数据集。这是这个领域第一个立体图像的集合。
GIT由80幅彩色和深度图组成,这些图像是在真实的家庭环境中使用移动机械手收集的。此外,基于对象的像素级分割对每个图像进行注释。
DES尺寸为640x640的室内抓拍的135张图,每幅图像中最显著的对象由三个用户标记,然后将标记为对象的重叠区域视为ground truth.
NLPR由1000幅RGB图像及其相应的深度图组成,这些图像是由标准的微软Kinect获得的。该数据集包括一系列室外和室内位置,例如办公室、超市、校园、街道等。
LFSD包括使用Lytro光场相机收集的100个光场,由60个室内场景和40个室外场景组成。为了标记该数据集,要求三个人手动分割显著区域,然后当三个结果的重叠超过90%时,分割结果被认为是基本真实的。
LFSD包括使用Lytro光场相机收集的100个光场,由60个室内场景和40个室外场景组成。为了标记该数据集,要求三个人手动分割显著区域,然后当三个结果的重叠超过90%时,分割结果被认为是基本真实的。
NJUD由1985个立体图像对组成,这些图像是从互联网、3D电影和富士W3立体相机拍摄的照片中收集的。
SSD使用三部立体电影构建,包括室内和室外场景。该数据集包括80个样本,每个图像的大小为960 × 1080。
DUT-RGBD由800个室内和400个室外带有相应深度图像的场景组成。该数据集包括几个具有挑战性的因素,即多个或透明物体、复杂背景、相似前景和背景以及低强度环境。
SIP由929幅带注释的高分辨率图像组成,每幅图像中有多个重要人物。在这个数据集中,深度图是使用真正的智能手机(即华为Mate10)捕获的。此外,值得注意的是,该数据集涵盖了各种场景和各种挑战性因素,并以像素级的地面真相进行了注释。
光场显著性检测
光场显著性模型
即使深度图提供了RGB图一定的布局信息,但是不准确或低质量的深度图通常会降低性能。为了克服这个问题,已经提出了光场SOD,利用光场来捕获丰富信息。
光场数据集包括:一个全聚焦图像,一个聚焦堆栈和一个粗略的深度图。
基于细化的模型
如今,已使用集中细化策略来加强相邻约束或降低SOD的多种形式的同质性。比如,采用两阶段显著细化策略来产生最终预测图,这使得相邻的超像素能够获得相似的显著性值。此外,LFNet提出了一个有效的细化模块,以减少不同模态之间的同质性,并细化他们的差异。
光场SOD的数据集
LFSD由100个不同场景的光场组成,空间分辨率为360 × 360,使用Lytro光场相机拍摄。该数据集包含60个室内场景和40个室外场景,大多数场景仅由一个显著对象组成。此外,要求三个人手动分割每幅图像中的显著区域,然后当三个分割结果都有超过90%的重叠时,确定背景真实度。
HFUT由255个光场组成,使用Lytro相机拍摄。在这个数据集中,大多数场景包含在复杂背景杂波下出现在不同位置和比例的多个对象。
DUTLF-FS由1465个样本组成,其中1000个样本用作训练集,其余465幅图像组成测试集。每幅图像的分辨率为600 × 400。该数据集包含几个挑战,包括显著对象和杂乱背景之间的较低对比度、多个不连续的显著对象以及黑暗或强光条件。
DUTLF-MV包括1,580个样本,其中1,100个用于培训,其余用于测试。图像是由利特罗伊鲁姆相机拍摄的,每个光场由多视角图像和相应的地面真相组成。
Lytro Illum由640个光场和相应的每像素地面真实显著图组成。它包括几个具有挑战性的因素,例如,不一致的照明条件,以及存在于相似或杂乱背景中的小突出物体。
模型评估和分析
对于模型评估指标主要有一下几个方面:
预测召回率(PR),F-measure,绝对平均误差(MAE),结构测量(S-measure),增强校准测量(E-measure)
PR
显著图S,其转化成的一个二进制掩码M,通过M和ground truth G来计算PR
Precision = ∣ M ∩ G ∣ ∣ M ∣ , Recall = ∣ M ∩ G ∣ ∣ G ∣ \text { Precision }=\frac{|M \cap G|}{|M|}, \text { Recall }=\frac{|M \cap G|}{|G|} Precision =∣M∣∣M∩G∣, Recall =∣G∣∣M∩G∣
F-measure( F β F_{\beta} Fβ)
weight综合考虑查准率和查全率,通过计算加权调和均值提出了
f
f
f测度:
F
β
=
(
1
+
β
2
)
P
∗
R
β
2
P
+
R
F_{\beta}=\left(1+\beta^{2}\right) \frac{P * R}{\beta^{2} P+R}
Fβ=(1+β2)β2P+RP∗R
其中
β
2
{\beta}^2
β2设置为0.3,强调精度,我们使用不同的固定[0,255]阈值来计算
f
f
f度量。这产生了一组我们报告的最大或平均
F
β
F_{\beta}
Fβ的
f
f
f测量度
MAE
这测量所有像素的预测显著图S和ground truth G之间平均像素绝对误差
M
A
E
=
1
W
∗
H
∑
i
=
1
W
∑
i
=
1
H
∣
S
i
,
j
−
G
i
,
j
∣
M A E=\frac{1}{W * H} \sum_{i=1}^{W} \sum_{i=1}^{H}\left|S_{i, j}-G_{i, j}\right|
MAE=W∗H1i=1∑Wi=1∑H∣Si,j−Gi,j∣
W
和
H
W和H
W和H分别表示特征图的宽和高
S-measure ( S α S_\alpha Sα)
为了捕捉图像中结构信息的重要性,
α
\alpha
α用于评估区域感知和对象感知之间的结构相似性,因此,
α
\alpha
α可以定义为:
S
α
=
α
∗
S
o
+
(
1
−
α
)
∗
S
r
S_{\alpha}=\alpha * S_{o}+(1-\alpha) * S_{r}
Sα=α∗So+(1−α)∗Sr
其中
α
\alpha
α是一个0~1之间的一个权重参数,这里默认
α
\alpha
α为0.5
E-measure( E ϕ E_{\phi} Eϕ)
E
ϕ
E_{\phi}
Eϕ是在认知视觉研究的基础上提出的,用于捕捉图像级统计及其局部限速的匹配信息。因此
E
ϕ
E_{\phi}
Eϕ可以定义为:
E
ϕ
=
1
W
∗
H
∑
i
=
1
W
∑
i
=
1
H
ϕ
F
M
(
i
,
j
)
E_{\phi}=\frac{1}{W * H} \sum_{i=1}^{W} \sum_{i=1}^{H} \phi_{F M}(i, j)
Eϕ=W∗H1i=1∑Wi=1∑HϕFM(i,j)
其中
ϕ
F
M
\phi_{FM}
ϕFM是增强对称矩阵

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









