







一、学习目标
1.了解非线性分类的作用与思想
2.掌握决策树建立方法
3.掌握最近邻方法
4.学习集成学习
5.学习非线性的SVM
二、概述
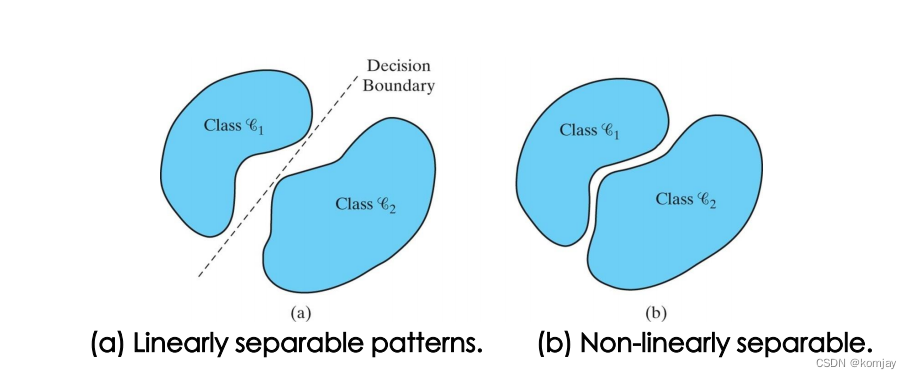
1.显然地,我们之前学习的线性分类法不可能将所有问题进行分类,而实际上,有许多问题是有明显的非线性的决策面进行分类,如下图:
2.于是乎,提出非线性分类方法,按思想原理,可分为两种:

线性拓展的方法实际上并不对原判别函数的参数进行变动,而是将输入x进行一定的变换,比如二次方化,幂函数化。而我们主要学习非线性思想的几种方法,且这几种方法并不是都是统一的思想原理。
三、决策树
1.决策树的思想,就是通过树节点的判断,将数据分类到不同的叶子节点后,就算完成了分类:
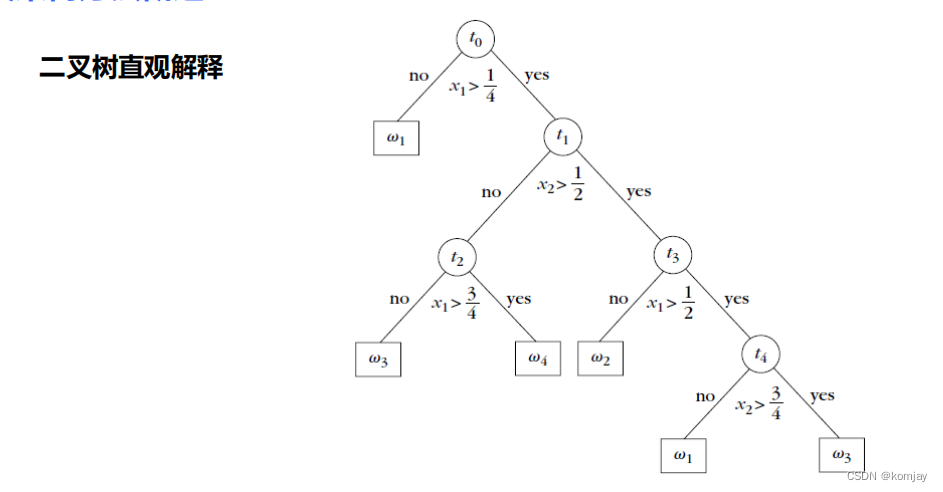
其几何解释就如下图所示:(每个矩形相当于一个叶子节点,边相当于树节点区分两个子树)
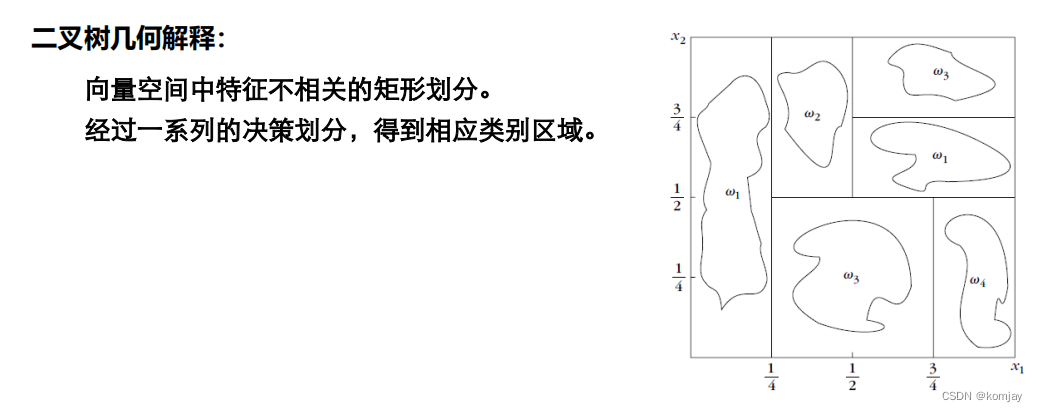
显而易见的,决策树的优点和问题都是存在的:(图中砍刀指的就是:上面图中我们将向量空间进行的划分)

所以,在确立一棵决策树时,我们要考虑4个问题:问题数(能有效地划分的分界数量),划分问题的选择(分界的优先顺序),决策树生成,剪枝处理(实际上,如果我们第一、二点做得好的话,不用考虑剪枝)。
2.问题数的确定:
(1)对于离散情况:

例如以西瓜的纹理为例:
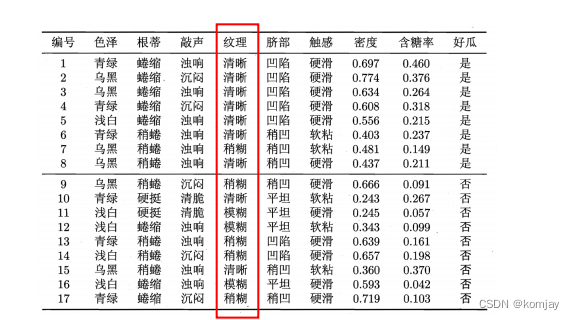
我们可以有两种确立分类的节点:
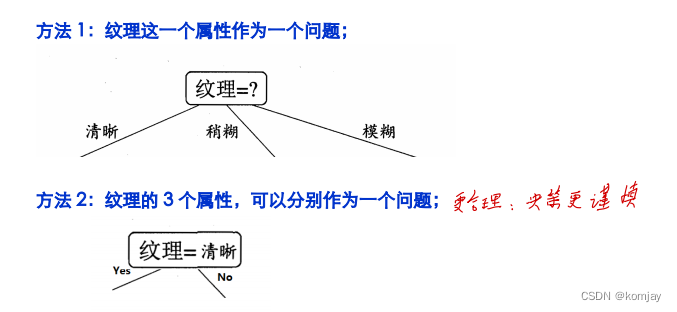
之所以说下面方法更好,除了其决策更谨慎外,其还有一个优点:保证了这是一棵二叉树。
(2)对于连续值的情况,我们就不能设置是否等于某个值来区分,而是使用“是否大于xxx"来区分:
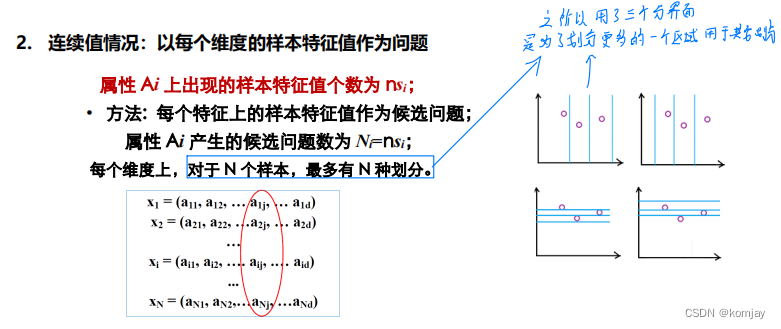
对于蓝色框部分,可能会有疑惑,有N个样本,我们有N-1个分界就能把他们划分开,为啥要N个。这是为了划分出一个不属于样本集合中的类别,从而使模型有一定的鲁棒性。
2.划分问题的选择
主要的任务是:确定分界的顺序。主要的思想是:按某个问题进行划分后,这个分界能最大程度地区分两类数据。而我们如何评判其是否分得很好呢?我们有三种评判标准:
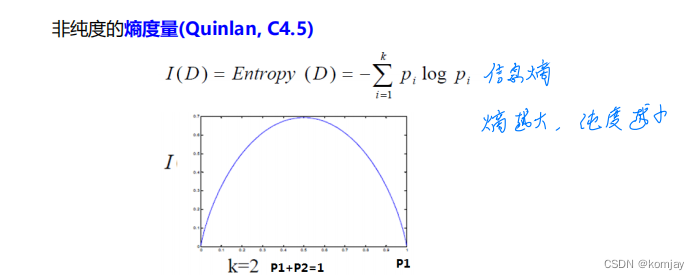


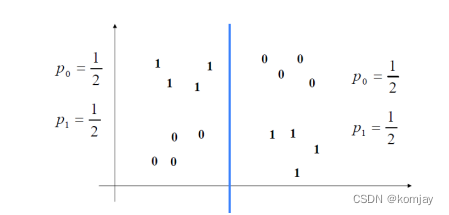
其中pi为概率,而在决策树中,是指我们划分数据后,各类别的占比,例如:
对于这三类评判标准,其中熵和信息增益是越大越好,基尼指数是越小越好,相关原理可以自行观察公式证实。其中信息增益是有一些问题的:

于是为了避免其选择分类太多的情况,对其进行改进(其中V就是分类总数):

分类节点(非叶子节点)确定好顺序后,还要确定叶子节点的分类:

四、最近邻方法
最近邻方法是一种无参数的方法,有点像聚类的想法,但是用在分类任务中,其主要思想就是一个点离哪一类更近,最划为哪一类。

1.最近邻法

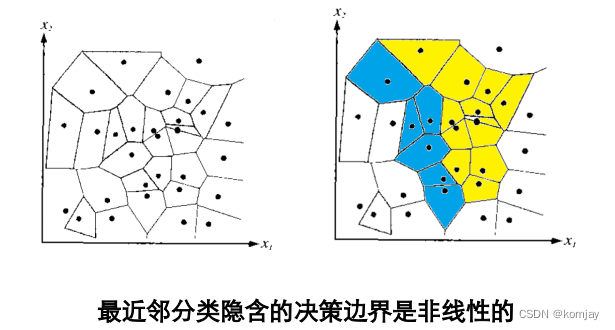
最后形成的决策边界是:
2.k近邻法
上面两种方法都存在着问题:

于是乎,提出了一些快速算法。
3.快速算法一:快速搜索近邻法
原理和过程如下:

主要工作有两个:(1)如何对样本进行分层,(2)对于一个新的点,如何划分到哪个集合中。
(1)分层主要有网格法、哈希或者构树法:

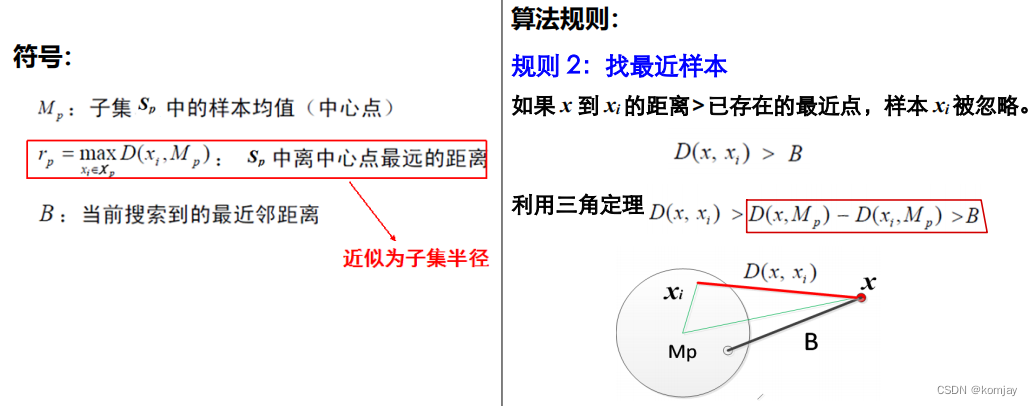
(2)如何找最近子集,有两种规则:
规则1,计算点到样本集边界的距离(图中,红色部分为其计算出的距离,由于大于B,故保留B对应的类为待归集到的类)

规则2,计算点到最近一些点的距离,这些点已经划进某类中了。
4.快速算法二:剪辑近邻法

由于删除掉分界面附近的点,其分界面周围会出现一些空白区域:

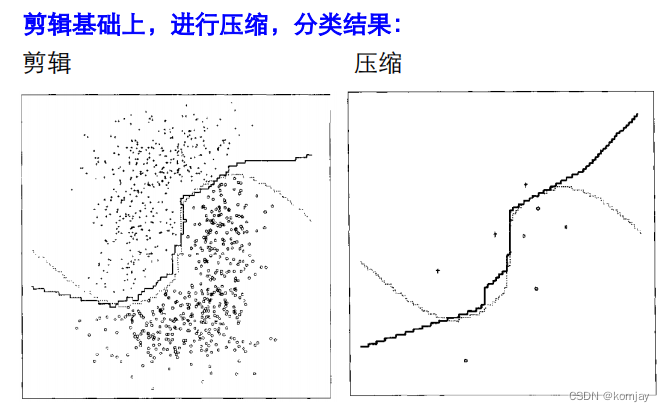
5.快速算法三:压缩近邻法
与剪辑近邻法相反,保留那些错误的样本后再作决策界(当然,做完后也会导致原本正分点变成错分点,也不管了)

由于错分的样本是少量的,所以,它的计算量会变得很小:
6.拒绝决策近邻法
其思想就是,那些不好分类的点,我就不分了。哈。

五、集成学习
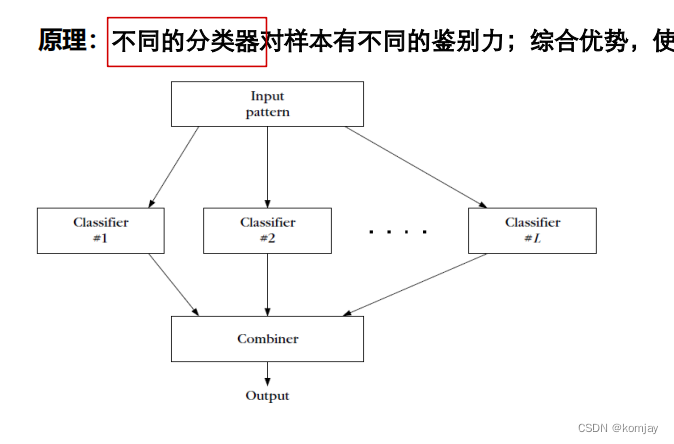
算法学习的主要目标就是各个分类器的权重的大小。权重的大小表明其对输出的影响力。
几种常见的学习准则:

这几种就不需要学习权重,而是汇总各方的结论进行总结。但这对分类器有要求:分类器之间要有多样性,且每个分类器性能都不错。
两个例子:Bagging和随机森林。
1.Bagging

2.随机森林

二者对比:

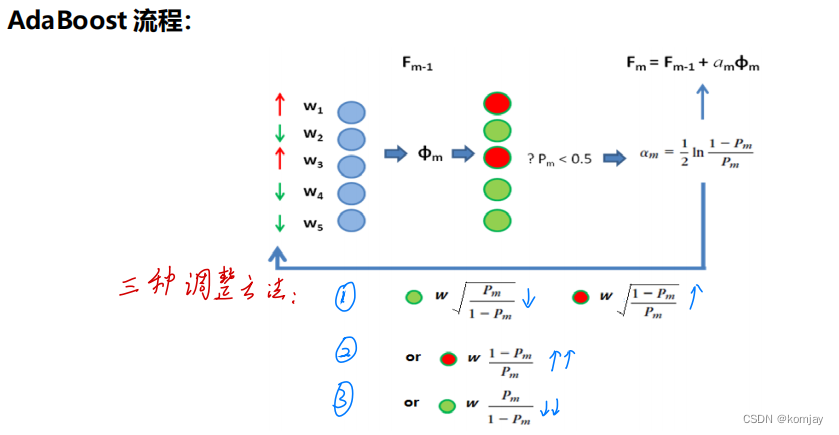
为了能够通过权重去衡量各个分类器对结果的影响度,我们使用Adaboost算法来实现。
3.Adaboost
Adaboost(adaptive boosting)算法是boosting原理的应用。boosting的思想就是设计一系列弱分类器,让其在不同的样本子集上学习,得到增强分类器。Adaboost就是解决我们上面说的,如何计算不同分类器的权重问题。当然,分类器自身的参数也一同计算得到。
目标函数如下:

分类器F的构成有两个:已经确定好θ的m个分类器模型和当前要优化的分类器:

优化的目标是当前要优化的分类器的参数西塔和重新计算新的权重α。损失函数如下:

先算θ:

再根据模型的优劣性能来确定α:

最后还有一个样本权重w。其作用是加重那些依旧错误的样本的权重,让后面的分类更器注重这些样本:

自此,Adaboost就能集成多个分类器作分类了:
六、非线性SVM
在上一张我们学习过线性SVM,那么非线性SVM与其唯一差别在于:线性SVM中,样本是x,我们的输入就是x,在非线性SVM中,我们通过变换函数Φ(·)将x转化后,再做线性区分。比较常见的思想就是“升维”,其在高维空间中的线性划分在低维空间中会变成非线性划分。
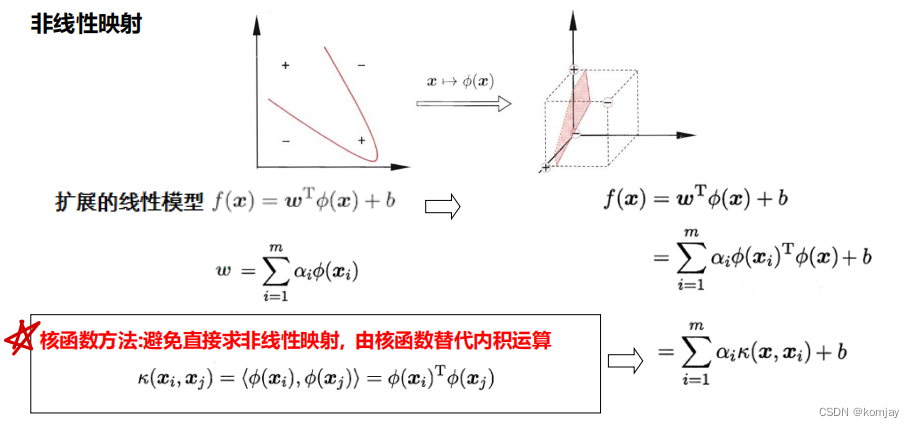
由于Φ(x)我们是不可知的,那么Φ(x)的内积我们更无法得知。所以我们使用核函数来取代其内积(核函数只能代替Φ(x)的内积,单独的Φ(x)我们没有别的模型可以去代替):
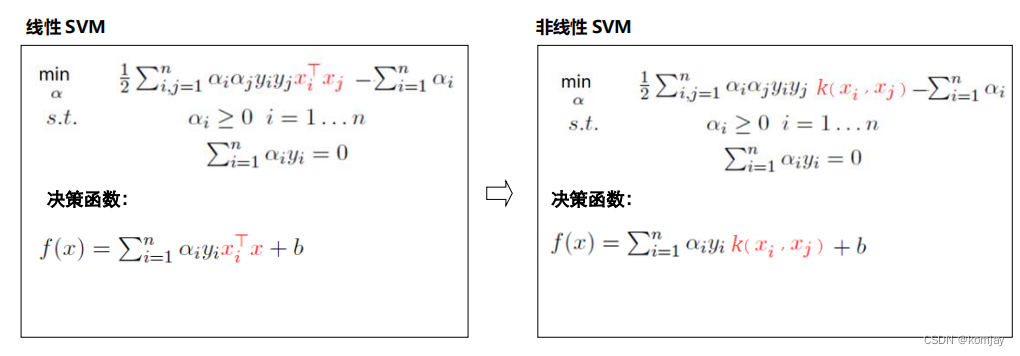
常见的核函数有:

之后便可根据线性划分的知识来计算超平面的w和b,有两种方案:
(1)硬间隔:

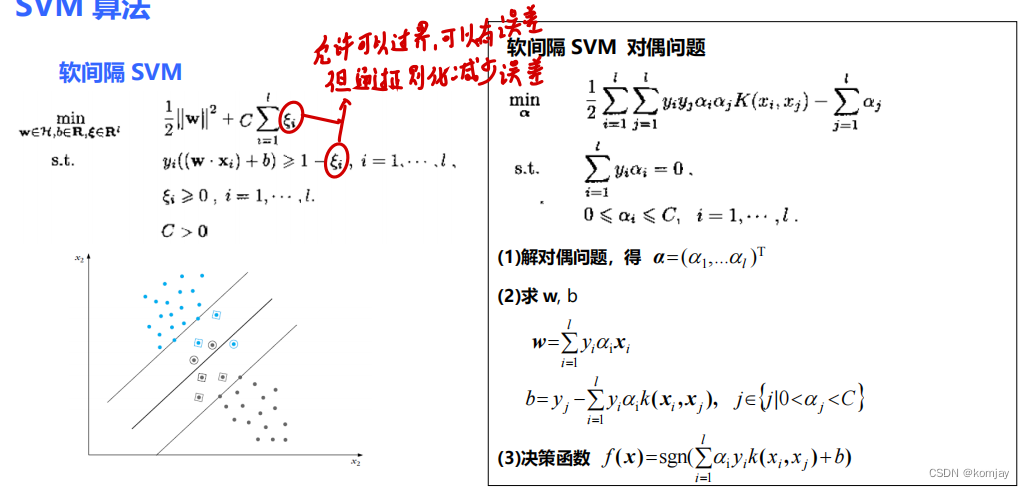
(2)软间隔:
七、本章小结
















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









