







DAP和IAP
DAP模型:通过训练样本学习一组属性分类器直接预测测试样本的属性。
IAP模型:通过训练样本的类别,(多分类器)间接预测测试样本的属性。
两者之间的区别:属性分类器的学习方式,DAP是一组分类器,IAP是多类别分类器。
相同之处:都是通过属性预测实现已知类(模式)向未知类(模式)的知识迁移。
IAP的训练和测试过程。

DAP训练和测试过程。

属性分类器训练过程。

对DAP模型测试数据类预测公式的具体化理解:
P
(
z
∣
x
)
=
∑
α
∈
(
0
,
1
)
M
p
(
z
∣
a
)
p
(
a
∣
x
)
=
p
(
z
)
p
(
a
z
)
∏
m
=
1
M
p
(
a
m
z
∣
x
)
P(z|x) = \sum_{\alpha \in (0,1)M}p(z|a)p(a|x) = \frac{p(z)}{p(a^z)} \prod^M_{m = 1}p(a^z_m|x)
P(z∣x)=α∈(0,1)M∑p(z∣a)p(a∣x)=p(az)p(z)m=1∏Mp(amz∣x)
等于以中间语义辅助信息为纽带。
利用上面这个公式,可以利用测试数据通过贝叶斯公式反求出该数据的类标签,但是我对这个公式进行推导过程,式中对式子中的求和符号和连乘符合变化无法理解,后来才发现,可能使自己太过注重整体,而忽略了单一属性的原因。为了便于理解公式(1),我们可以将输入的测试数据看成
z
z
z,尽管
z
z
z表示类标签,但实际上
z
z
z和训练数据
x
x
x一样,本质上在属性分类器中所利用的信息都是底层数据特征,进而根据与获取的正负样本的底层特征进行对比,(求向量之间的距离)得到属性,设测试数据的属性集为:
a
n
z
=
(
a
1
z
,
a
2
z
,
a
3
z
.
.
.
.
,
a
n
z
)
a^z_n = (a^z_1,a^z_2,a^z_3....,a^z_n)
anz=(a1z,a2z,a3z....,anz)
设训练数据的属性集合为:
a
m
=
(
a
1
,
a
2
,
a
3
,
.
.
.
a
m
)
a_m = (a_1,a_2,a_3,...a_m)
am=(a1,a2,a3,...am)
我们要求测试集合中只有第一个数据(a1z),与训练数据属性相同,(可以是a1,也可以是a2,a3等等)这种情况下,对于文献中的公式为:
p
(
a
∣
z
)
=
[
a
=
a
z
]
p(a|z) = [a = a^z]
p(a∣z)=[a=az]
我们可以更好地理解这个表示了训练数据属性和测试数据属性之间的对应关系,换句话说,在我的属性一对一的假设中,有以下式子成立:
[
[
a
1
=
a
1
z
]
]
=
1
[[a_1 = a^z_1]] = 1
[[a1=a1z]]=1
[
[
a
m
=
a
n
z
]
]
=
0
[[a_m = a^z_n]] = 0
[[am=anz]]=0
(
m
≠
1
且
n
≠
1
)
(m \not = 1 且 n \not = 1)
(m=1且n=1)
在这种条件下,我们推导以下公式:

标签分配问题(都是利用最大后验证方法)
DAP的分配时unseen和seen标签。

IAP分配的时unseen标签。

通过模型学习一个语义属性,利用语义属性作为视觉样本类别标签间的桥梁,通过构建一个基于属性的分类器,进而对视觉样本所属的类别进行估计。
DAP模型直接学习建立视觉数据与属性特征中每一种属性之间关系的模型,并利用所学习到的模型预测测试样本的属性特征。
IAP模型首先将测试样本分到可见类别中,然后利用可见类别**
y
y
y和未见类别
z
z
z之间的语义关系**对测试样本进行预测。

关键、构建可见类与不可见类之间的关联的语义信息。
DAP模型
DAP模型可以理解为一个三层模型,第一层时原始输入层,例如一张电子图片,(可以用像素的方式进行描述)第二层是
p
p
p维特征空间,每一维代表一个特征,(例如是否有尾巴,是否有毛等等),第三层是输出层,输出模型对输出样本类别的判断。在第一层和第二层中间,训练
p
p
p个分类器,用于对一张图片判断是否符合
p
p
p维特征空间各个维度所对应的特征。在第二层和第三层之间有一个知识语料库。用于保存
p
p
p维特征空间和输出
y
y
y的对应关系。
简单来讲,就是对输入的每个属性训练一个分类器,然后将训练得出的模型用于属性预测,测试时,对测试样本属性进行预测,再从属性空间里面找到和测试样本最接近的类别。
直接属性预测方法有固定的类别-属性关系,通过样本与类别间的训练,蕴含了对属性值的训练,从而取得了相关的类别分类器参数。在测试阶段,测试样本的属性值可直接获取,从而可以推知样本所属的类别,这个类别也可以是一种训练阶段未见样本的类别。
可见类别样本
y
1
,
y
2
,
.
.
.
,
y
k
y_1,y_2,...,y_k
y1,y2,...,yk和未见样本的目标类别
z
1
,
z
2
,
.
.
.
z
l
z_1,z_2,...z_l
z1,z2,...zl,以及它们的属性
a
1
,
a
2
,
.
.
.
,
a
m
a_1,a_2,...,a_m
a1,a2,...,am之间的关系通过一个二值矩阵给出,矩阵中的值a_my,a_mz形成的编码表示了对于一个给定的类y或者z,属性a_m对于分类是有效还是无效。这个二值矩阵编码是通过人工有监督的给出,属性分类器的训练通过那些可见样本
x
x
x,和类别标号
y
y
y进行训练,在测试阶段,图像有效属性
a
m
a_m
am可以通过其后验概率
P
(
a
m
∣
x
)
P(a_m|x)
P(am∣x)表征,这个值可以通过之前训练的分类器给出,并且这些属性可以与待测试类别
z
z
z的后验概率建立联系,在识别阶段,同样利用
f
(
x
)
f(x)
f(x)来获得最大似然输出类,这个类别可能来自具有训练样本
y
y
y的类别空间,也可能来自未见训练样本
z
z
z的类别空间。
- 对已知类别样本训练 → \rightarrow → P ( a m ∣ x ) P(a_m|x) P(am∣x)
- 结合作者,主题模型, → \rightarrow → P ( a ) P(a) P(a)
- 样本与类别z的关系.
- 样本与类别z的关系:
P ( z ∣ x ) = P ( z ) P ( a z ) ∏ m = 1 M P ( a m z ∣ x ) P(z|x) = \frac{P(z)}{P(a^z)}\prod^M_{m= 1}P(a^z_m|x) P(z∣x)=P(az)P(z)m=1∏MP(amz∣x) - 极大似然输出类
f ( x ) = a r g m a x ∏ m = 1 M P ( a m z ∣ x ) P ( a m z l ) f(x) = argmax\prod^M_{m = 1}\frac{P(a^z_m|x)}{P(a^{z_l}_m)} f(x)=argmaxm=1∏MP(amzl)P(amz∣x)

另一个版本IAP模型
使用属性字类之间传递知识,但是属性形成了两层标签之间的连接层,一层用于训练是已知的类,另一层用于训练时未知的类,IAP的训练阶段是普通的多类别分类。在测试时,对多有的训练课程的预测都会对属性层进行标记,从而可以推测出测试课程的标记。
算法流程
首先通过训练样本x 获得每类
y
1
,
…
,
y
k
y_1,…,y_k
y1,…,yk的概率
p
(
y
k
|
x
)
p(y_k|x)
p(yk|x),由类别与属性间的依赖关系
p
(
a
m
|
y
)
p(a_m|y)
p(am|y)即可获得
p
(
a
m
|
x
)
p(a_m|x)
p(am|x)=
∑
k
=
1
K
▒
P
(
a
m
|
y
k
)
p
(
y
k
|
x
)
\sum_{k=1}^K▒P(a_m|y_k)p(y_k|x)
∑k=1K▒P(am|yk)p(yk|x),在测试阶段,通过类别-属性关系来实现从训练类别标签的后验分布来推知未见样本类标签的概率分布,即f(x)。具体流程如下图所示:
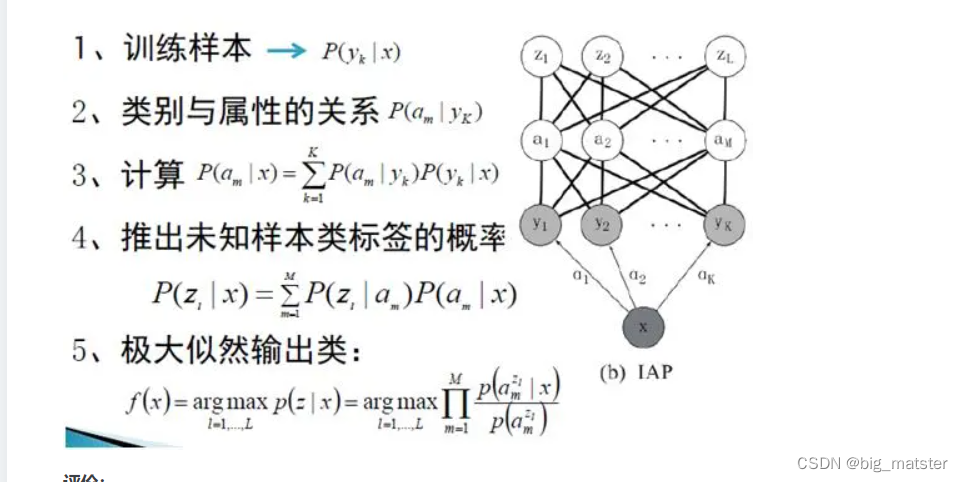
第一步:使用贝叶斯公式估计
第二步:第二步在使用多个贝叶斯估计,推断类别与属性之间的关系。
第三步:使用乘积来计算特征x到属性值之间的关系。
第四步:推出未知类样本标签的概率。
第五步:极大似然输出类。
关键思想:多次运用贝叶斯估计,来统计
明天把贝叶斯估计,统一 的好好研究下,然后开始看文献,零样本的文献,基本上的啥都搞懂啦。
学习心得
明天将贝叶斯公式全部都搞透澈,全部都研究彻底,然后开始读文献,好好的研究一波文献综述。将其研究彻底。


















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











