







 本文深入探讨了广义零样本学习(GZSL)的各个方面,这是一种旨在在可见和不可见类别之间进行分类的技术。它依赖于语义信息,如属性向量或词向量,来建立两类别的联系。文章指出了GZSL面临的挑战,如维度灾难、领域迁移问题和过拟合到可见类别。作者还对各种方法进行了分类,包括基于嵌入和生成式方法,并分析了他们的优缺点。此外,文章讨论了性能指标,如AUSUC和HM,以及未来的研究方向。
本文深入探讨了广义零样本学习(GZSL)的各个方面,这是一种旨在在可见和不可见类别之间进行分类的技术。它依赖于语义信息,如属性向量或词向量,来建立两类别的联系。文章指出了GZSL面临的挑战,如维度灾难、领域迁移问题和过拟合到可见类别。作者还对各种方法进行了分类,包括基于嵌入和生成式方法,并分析了他们的优缺点。此外,文章讨论了性能指标,如AUSUC和HM,以及未来的研究方向。
摘要
生成式零样本目的是训练一个模型,监督学习下,输出类别不可知条件下,该模型对数据样本进行分类。为了解决这个任务,生成式零样本利用可见的语义信息和不可见类别在不可见和可见类别间构建桥梁,结论,许多的零样本模型都被确切的陈述,在这篇论文的概览中,我们提出一个关于零样本的全面性观点。首先,我们提出生成式零样本的概述,包括挑战和问题。其次,我们介绍了生成式零样本方法,并讨论了每一种类别的代表性方法,另外,我们讨论了在基准数据集上,生成式零样本方法的应用,联同讨论了研究不足和未来展望。
关键词:生成式零样本学习、深度学习、语义空间、生成式对抗网络、VAE。
介绍
随着近年来,随着图像处理和计算机视觉的快速发展。深度学习模型非常受欢迎,由于它们有能力提供端到端的解决方案从特征提取到分类。虽然这些成功了,传统深度学习模型要求为每个类别训练大规模的标签数据,连同大规模的样本。在这方面,收集大规模的有标签的样本是一个挑战性问题。作为一个案例,ImageNet是一个大规模的数据集,包含14百万张图片,21814类别,许多的类别包含仅有少量的图片。另外,标准的深度学习模型能够识别样本属于哪一个类别,这些类别在整个训练阶段是可见的,但是,其并不能够去处理不可见的类别。然而,在许多真实世界应用的场景中,并不是对所有类别都有足够多数量的标签样本。一方面**,标注大量细粒度的样本是费力的,其要求一个领域的专家知识**。
另一方面,许多类别缺乏足够的标签样本。比如:endangered bird。不断完善的,比如:COvID-19。或者在训练阶段未涵盖,但是出现在测试阶段。
多种学习技术已经开发出来,零样本和少样本学习技术能够使用一些少量的学习样本来学习类别。这些技术从其他类别数据样本中获取知识,和训练处理少量样本类别的分类模型。开集识别学习OSR技术能够识别测试样本是否属于不可见类别。它们无能力去预测一个精确的类别。Out-of-distribution技术试图去识别测试样本, 测试样本是不同于训练样本的,然而,以上提及的技术都不能分类不见类样本,相反,人类能够识别大约30000万张类别,我们并不需要提前学习所有类别。一个案例,一个儿童能够容易的识别zera,如果其在之前已经看过马, 那么其将会有zebra的知识,看起来像黑色和白色条纹的horse。零样本技术对类似的挑战是一个很好的解决方案。
零样本技术目的是在语义信息的帮助下训练一个模型能够分类不可间类别实体(目标域)从可见类别(source main)哪里获得知识。语义信息在高维向量中嵌入了可见类别和不可见类别的名称。语义信息的获得方式有手动定义属性向量,自动提取词向量、上下文嵌入、或者其他的组合方法。换句话说,零样本学习使用语义信息来构建可见类别和不可见类别的桥梁。这种学习范式能够与人类相比较,在识别新物体的时候,通过其描述和以前习得的观念来测度其可能性。
在传统的零样本技术中,测试集仅包含不可见类别是不现实的,其并不能反应真实世界的应用场景。实际上,与不可见类别相比,可见类别的样本数据是更普遍的。同时识别两类的样本数据是重要的,而不是仅识别不可见类别的样本数据。
这种方法称为生成式零样本方法,确实,生成式零样本方法是零样本方法的实用版本。生成式零样本方法的主要动机是模仿人类识别能力,其能够识别来自可见类别和不可见类别的样本,

上图代表一个广义零样本和零样本类别的示意图。
Socher在2013年,首次提出了广义零样本的概念。离群点检测方法被整合进模型去决定被测试样本是否属于可见类别。如果其来自可见类别,标准的分类其能够被使用,否则,通过计算不可见类别的可能性可以为图像分配一个类别。
在同一年,Frome et al 试图去学习标签间语义关系,通过利用文本数据和将图片数据集映射进语义嵌入空间。
Norouzi et al :使用一个类标签嵌入向量凸组合将图片映射进语义嵌入空间。试图去识别可见类别和不可见类别的样本。
然而直到2016年,广义零样本并没有得到重视,
Chao et al:富有经验性的显示在生成式零样本技术,零样本技术的效果并不是很好,这是因为零样本技术容易在可见类别上过拟合。比如,将不可见类别的测试样本作为可见类别的一个类。后来,
Xian et al和Liu et al. 在图像和web-scale video data上有类似的发现。同时,这主要由于已经存在的技术大部分都是针对可见类别的,几乎所有测试样本都属于不可见类别。可以被分为可见类别的一类。
为了解决这个问题。
Chao et al。提出了一种有效的精准技术,称为calilbrated stacking。
为了评估两股力量,识别样本中的可见类别和不可见类别。因此,广义零样本的技术根本性的越来越多。
Contributions
广义零样本技术已经受到许多研究者的关注,虽然零样本技术的概览在一些文献中能够被找到,我们的论文和以往零样本调查的文献在于以下方面:
- 聚焦于零样本学习,仅有少量的广义零样本方法被复查,
- 在不同案例中进行调查了多种零样本技术和广义零样本技术的影响,
- Several SOTA ZSL and GZSL methods已经被选择和使用不同的数据集进行评估。
然而,这些工作更聚焦于实证研究,而不是零样本和广义零样本的综述性文章。研究聚焦于零样本技术,少部分的讨论广义零样本方法。 - Rezaei and Shahidi使用新冠肺炎诊断数据集研究了零样本方法的重要性,与上面综述性文章不同的是,在这篇文章中,我们更加关注广义零样本,而不是零样本技术。然而,几乎没有一个对广义零样本进行深入调查和分析的。为了弥补这方面的不足。我们目的是在这篇文章中,我们提出了一个广义零样本的全面性概览,包括:问题描述、挑战性问题、层次分类和应用。
我们浏览出版文章、会议论文、文章篇章和高质量的预印本。这些资料与广义零样本相关。从2016年到2021年都相当流行。然而,我们可能回缺失一些近年来的研究,这是不可避免的,这篇文章的主要贡献包括如下: - 广义零样本方法的全面性概览,据我们所知,第一篇论文中,试图提供一个深入分析的广义零样本的方法。
- 广义零样本方法的层次类别,连通与其对应的具有代表性的model与真实场景的应用。
- 阐明研究空白和未来研究展望。
Organization
这篇文章包含六个部分,
- 给出一个广义零样本技术的概览:问题描述、语义信息、嵌入空间、挑战性问题。
- 归纳推导和语义推导的广义零样本方法,这是广义零样本方法提供的一个层次分类。
每个类别都被进一步分为几种成分。 - 聚焦于直推式广义零样本方法,
- 将广义零样本技术应用到多个领域:计算机视觉和自然语言处理。
- 研究不足和未来展望,连通结束语。
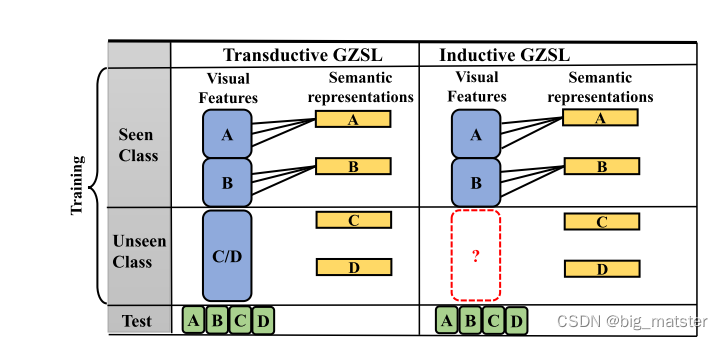
上图是直推式和归纳式示意图。在归纳式中,仅有视觉特征和可见类别的(A和B)的语义表示,然而,直导式系列中,可见类信息有权访问不可见类别的无标签视觉样本。
广义零样本学习的概览
问题描述
{ S = ( x i s , a i s , y i s ) i = 1 N s ∣ x i s ∈ X s . a i s ∈ A s . y i s ∈ Y s S = (x^s_i,a^s_i,y^s_i)^{N_s}_{i = 1} | x^s_i \in X^s.a^s_i \in A^s.y^s_i \in Y^s S=(xis,ais,yis)i=1Ns∣xis∈Xs.ais∈As.yis∈Ys}
{ U = ( X j u , a j u , y j u ) j = 1 N s ∣ x j s ∈ X s , a j s ∈ A s , y j s ∈ Y s U = {(X^u_j,a^u_j,y^u_j)^{N_s}_{j = 1} | x^s_j \in X^s,a^s_j \in A^s,y^s_j \in Y^s} U=(Xju,aju,yju)j=1Ns∣xjs∈Xs,ajs∈As,y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











