






20220511
https://www.sohu.com/a/484168640_420744
https://jingyan.baidu.com/article/4853e1e55e55511909f726c0.html
https://blog.csdn.net/weixin_39797381/article/details/112682407
概率密度曲线的画法和意义
坐标和面积的意义 :面积是区间上的上的概率,横坐标是某个取值的意义?
曲线越尖,说明左右两边稀缺值的取值概率变高,也就是取离群值的概率变高
数据越分散,反之数据越集中
正太分布曲线绘制
https://blog.csdn.net/weixin_42081390/article/details/124267073
https://blog.csdn.net/weixin_45288557/article/details/119494862
https://www.jianshu.com/p/75942cea098d
https://bbs.pinggu.org/forum.php?mod=viewthread&tid=3168636&ctid=2881
https://zhuanlan.zhihu.com/p/84614017
https://blog.csdn.net/weixin_39874269/article/details/112453431
峰度和偏度的意义
峰度值越大,越陡峭,说明离群值越多,投资风险高
偏度越大,数据不平衡越大
20220420
5种数据同分布的检测方法!
考察分布是否相同
https://blog.csdn.net/abcdefg90876/article/details/113930836
20211205

假设检验过去称为显著性检验(significance test)。它是利用小概率反证法思想,从问题的对立面( H0)出发间接判断要解决的问题(H1)是否成立。也就是说小概率事件是基本不可能发生的,在H0成立的条件下计算检验统计量(test statistic),利用H0当中的条件来进行计算,然后根据获取的P值来进行判断。
假设检验的步骤
原假设:想证实的假设
 方差齐性
方差齐性
白噪声序列,是指白噪声过程的样本实称,简称白噪声。白噪声序列的特点表现在任何两个时点的随机变量都不相关,序列中没有任何可以利用的动态规律,因此不能用历史数据对未来进行预测和推断。
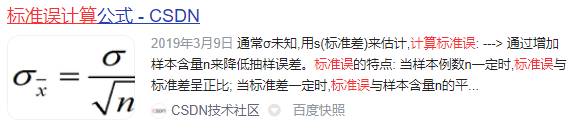
标准误(standard error),样本平均数的标准差。用SEx表示。描述样本均值对总体期望值的离散程度。
标准误
20211113
F检验(F-test),最常用的别名叫做联合假设检验(英语:joint hypotheses test),此外也称方差比率检验、方差齐性检验。它是一种在零假设(null hypothesis, H0)之下,统计值服从F-分布的检验。其通常是用来分析用了超过一个参数的统计模型,以判断该模型中的全部或一部分参数是否适合用来估计母体。
https://blog.csdn.net/haodawei123/article/details/99307098
r平方,拟合优度
20211103
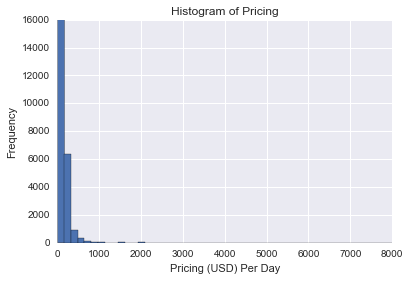
我们看到定价分布严重偏右。右偏
20211019
求平均数
x/n / y/n 不等于 (x/y)/n 当然 当两个分母不同的时候 n和n不相同的时候就只能用前面的计算了
20211015
https://www.jianshu.com/p/807b2c2bfd9b
卡方检验例子
https://www.zhihu.com/question/295284388
https://zhuanlan.zhihu.com/p/112338560
https://www.zhihu.com/question/476040943/answer/2031905564
https://zhuanlan.zhihu.com/p/98877686 重点 中心极限定理的图画解释
样本量最少达到多少才可以反应总体的特征?
推断统计和描述统计?

统计分析思路
统计两个核心问题
1.度量,分析,解释差异
2.考察相关性
20211007
如果是抽样的话,可视化探索就没有意义了
直接用量化的统计检验
20210925
两点分布就是伯努利分布
20210910
https://blog.csdn.net/guyu1003/article/details/109383918
ks的计算过程
20210729
https://blog.csdn.net/kyle1314608/article/details/119188392
数据分析方法_统计
20210714
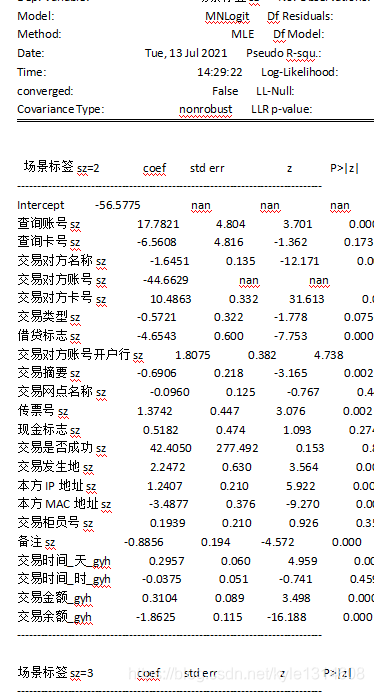
一共有三个分类,最后结果却显示两个分类 是因为第一个分类作为参照
20210713
https://zhidao.baidu.com/question/629746157856221484.html
例:P=a+bQ,表示价格与数量的关系,则a、b是参数,都是外生变量;P、Q是模型要决定的变量,所以是内生变量。除此之外,譬如相关商品的价格,人们的收入等其他与模型有关的变量,都是外生变量
一个模型的自变量、因变量都是内生变量,是“一种理论内所要解释的变量”,都是由模型决定的。
参数是外生变量
endog : ndarray
A reference to the endogenous response variable
exog : ndarray
A reference to the exogenous design.
endog:应变量
exog:自变量
相关性分析的时候肯定要去除离群值 会有影响的
https://mp.weixin.qq.com/s/mHxrxR0AEm51smS7pGpsLg
Logistic regression in Python statsmodels
https://mp.weixin.qq.com/s/vgXNVd0NK3WxukzLxywUPA
https://www.jianshu.com/p/08f710ca6bfe
上面两个是spss
https://zhuanlan.zhihu.com/p/242054998
这个是statsmodels
import statsmodels.formula.api as smf
result = smf.mnlogit(
formula = 'final_state ~ age +weight',
data = state[['age', 'final_state']],
).fit()
params = result.params
print result.summary()
final_state是因变量?
import statsmodels.api as sm
#Define X and Y
X = df[['Male','Business','Punish','Explain']]
X = sm.add_constant(X)
Y = df['Wallet']
#Fit model
model = sm.MNLogit(Y,X).fit()
model.summary()
因变量无序多分类资料的logistic回归
probit是符合高斯分布的,而Logit是符合logistics分布的,mnlogit是logistics多分类的情况,
std err: 反映了系数的精度水平。它越低,准确度就越高。
20210704
大数指的次数足够多是频率和概率近似相等 大叔赶驴(概率)
中心极限定理用的时候:抽n次样本集(一个集合) ?其均值服从正态分布 中心(真空胎)正态分布
阿尔法:弃真,显著性水平
1-阿尔法是显著性水平
显著性水平加置信水平等于1,都是小于1的值
置信区间是真实的参数值不一定小于1
显著性水平就是变量落在置信区间以外的可能性,“显著”就是与设想的置信区间不一样,用α表示。显然,显著性水平与置信水平的和为1。显著性水平为0.05时,α=0.05,1-α=0.95如果置信区间为(-1,1),即代表变量x在(-1,1)之间的可能性为0.95。0.05和0.01是比较常用的,但换个数也是可以的,计算方法还是不变。
p<阿尔法(小概率发生了):拒绝原假设 (承认有差异) 原假设:通常假设为没有差异
p值是0.1,这意味着观察到的t统计数据归因于偶然性的概率是10%(非小概率事件)。p值很高。
p值意义
https://blog.csdn.net/kyle1314608/article/details/116454428
20210531
https://www.jb51.net/article/180654.htm
https://blog.csdn.net/yfl_jybq/article/details/100114952
源码 重点
求波峰
20210529
https://zhidao.baidu.com/question/691497957462534884.html
峰宽
https://www.zealseeker.com/archives/find-peak/
波峰识别算法 重点
prominences 突出的寻找算法
波峰和两边最近的波谷高度求差 得到最小的高度差就是突出值
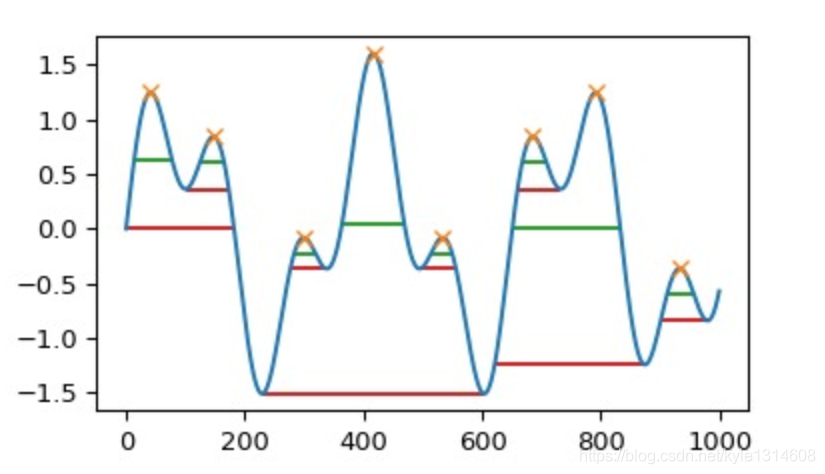
https://vimsky.com/examples/usage/python-scipy.signal.peak_widths.html
绿线是一般的峰宽
红线是完整的峰宽?
https://vimsky.com/examples/usage/python-scipy.signal.peak_prominences.html
python scipy signal.peak_prominences用法及代码示例

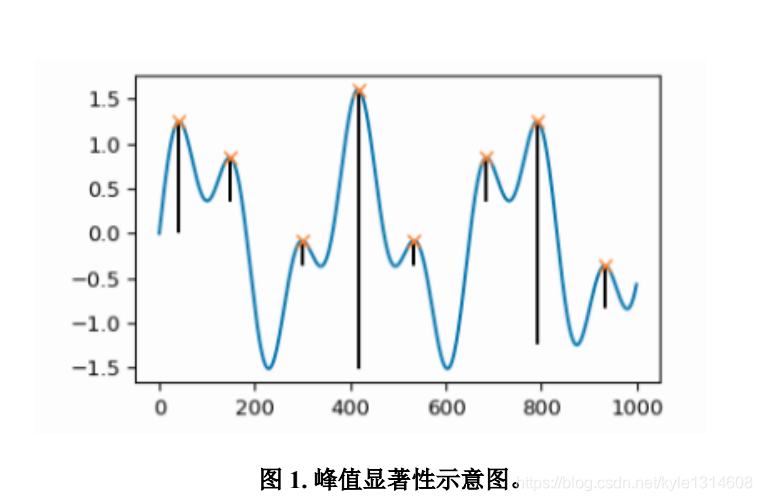
横轴是索引 纵轴是值?
峰顶和起点或这和前面一个峰谷的垂直距离
scipy.signal.find_peaks()
https://www.cnblogs.com/WindyZ/p/11426530.html
重点
distance: 相邻峰之间的最小水平距离, 先移除较小的峰,直到所有剩余峰的条件都满足为止。
波峰是指 波在一个波长的范围内,波幅的最大值,与之相对的最小值则被称为 波谷。以 横波为例,突起的最高点就是波峰,陷下的最低点就是波谷
https://vimsky.com/examples/usage/python-scipy.signal.peak_widths.html
https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.peak_widths.html#scipy.signal.peak_widths
波峰宽度
序列数据波峰识别以及波峰形状识别
https://www.cnblogs.com/bethansy/p/10560341.html
滤波过滤一些峰值点
滤波的方式:移动平均
https://blog.csdn.net/qq_33331451/article/details/104264352
savgol_filter 滤波
https://blog.csdn.net/liyuanbhu/article/details/9094945
https://blog.csdn.net/kaever/article/details/105520941
https://blog.csdn.net/liyuanbhu/article/details/9094945 重点
https://blog.csdn.net/ISE_numberone/article/details/116331118
实际使用效果
Savitzky-Golay 滤波器
在前面我们提到的吃橘子的案例里,世界上有 50% 的人爱吃橘子是我们的原假设。由于一次实验得出的置信区间 [80%±1.96*0.04] 不包含 0.5,并且我们 95% 确信这个区间包含真值,只有 5% 的概率出错,5% 概率非常小,小到我们可以接受,所以拒绝原假设。
置信区间:假设真值包含在置信区间之中
p-value只说明两个样本有没有显著性差异,并不说明差异的大小
https://cloud.tencent.com/developer/article/1759391
https://blog.csdn.net/kyle1314608/article/details/116454428
ABTEST:
20210420
在考察连续型自变量和因变量的统计检验的时候,检验模型已经自动把
连续性自变量通过减均值除方差得到(0,1)正态分布
当要确定所得到的统计量的相对大小的时候,需要查看所对应的分布表
比如卡方分布表,T分布表等
统计检验的时候一定要先归一化!!很重要
自变量是连续,因变量是二分类
可以因变量的两个值单独画直方图来看相关性
20210419
https://blog.csdn.net/qimaoryan/article/details/72824766
卡方检验
输出为:
(7.6919413561281065,
0.021365652322337315,
2,
array([[ 48.99759615, 39.04086538, 20.96153846],
[ 138.00240385, 109.95913462, 59.03846154]]))
https://zhuanlan.zhihu.com/p/128905132
卡方检验
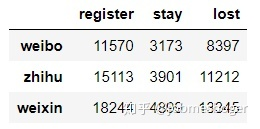
observed = df[[‘stay’,‘lost’]]
stats.chi2_contingency(observed=observed)
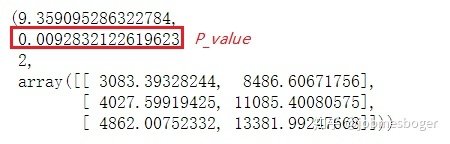
可以看出P值要小于我们原先定的显著性水平α,所以我们有理由拒绝原假设,即用户渠道的确影响了留存情况,两者并不是相互独立的。
先分组统计每个组对于因变量各值的频数
卡方检验
https://www.statsmodels.org/
模型源码
逐步回归的目的:
当模型显示大部分变量都不太显著的时候,就要用逐步回归逐个去掉不相关的变量
考察剩下的变量是否显著
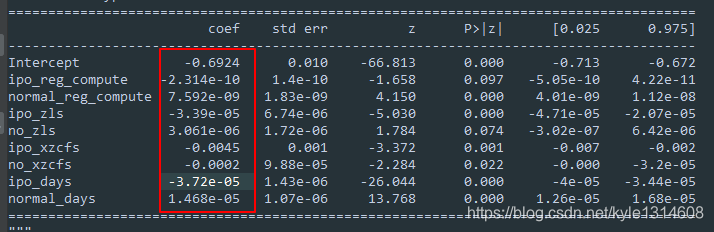
连续型自变量和离散型因变量的解读 仍然是1比0 大 把其作为回归问题来解读就好
比如ipo_days 的值为负 成立时间越长 越不匹配 越不需要上下游
如果把阈值放大 比如为0.1 则所有变量都可用
虽然大部分都显著
系数非常小 可能是因为没有归一化所致,比如注册资金本来数值范围就很大
但是统计量值小,其实相关性也很小
各个变量的系数相对大小也能说明其对模型的贡献度大小的关系?
https://www.w3cschool.cn/doc_statsmodels/statsmodels-generated-statsmodels-stats-mediation-mediation.html
stats.model
stats代码示例
>>> import statsmodels.api as sm
>>> import statsmodels.genmod.families.links as links
>>> probit = links.probit
>>> outcome_model = sm.GLM.from_formula("cong_mesg ~ emo + treat + age + educ + gender + income",
... data, family=sm.families.Binomial(link=probit))
>>> mediator_model = sm.OLS.from_formula("emo ~ treat + age + educ + gender + income", data)
>>> med = Mediation(outcome_model, mediator_model, "treat", "emo").fit()
>>> med.summary()
统计检验总体规则
1.最好是逐步回归 全部连续的放进去 再一个一个减
2.离散的就分开检验?
https://blog.csdn.net/kyle1314608/article/details/115866097
什么是p值
https://blog.csdn.net/kyle1314608/article/details/115865290
置信区间
https://www.sohu.com/a/437666151_617676
假设检验
所有的原假设都是系数为零
python 统计包
https://blog.csdn.net/weixin_39625782/article/details/111581376
https://blog.csdn.net/weixin_26713521/article/details/108134303
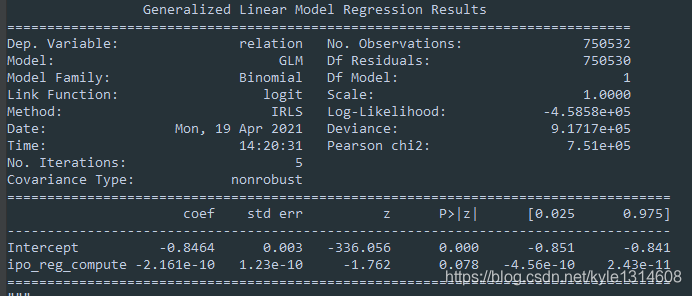
p值小于0.05 拒绝原假设,ipo_reg_compute的系数 应该是零
实际出来的值也基本为零了
coef:为负值 则表示负相关
Z:就是我们常用的t统计量,这个值越大越能拒绝原假设。
在统计量分布表上面体现的很明显 自由度不变的情况下
越往右走 统计量值越大 所对应的 p值越小
P>|t|:统计检验中的P值,这个值越小越能拒绝原假设。
不止要看p值,还要看coef的方向是否符合实际情况
自变量:连续 因变量:二分 解读
stats.model
https://blog.csdn.net/BF02jgtRS00XKtCx/article/details/108687817
回归分析结果解读
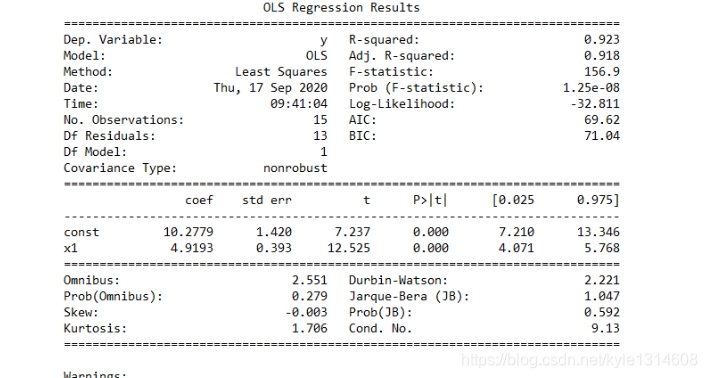
Dep.Variable: 就是因变量,dependent variable,也就是咱们输入的y1,不过这里statsmodels用y来表示模型的结果。
Model:就是最小二乘模型,这里就是OLS。
Method:系统给出的结果是Least Squares,和上面的Model差不多一个意思。
Date:模型生成的日期。
Time:模型生成的具体时间。
No. Observations:样本量,就是输入的数据量,本例中是15个数据,就是前面distance与loss中包含的数据个数。
Df Residuals:残差自由度,即degree of freedom of residuals,其值= No.Observations - Df Model - 1,本例中结果为15-1-1=13。
Df Model:模型自由度,degree of freedom of model,其值=X的维度,本例中X是一个一维数据,所以值为1。
Covariance Type:协方差阵的稳健性,在本例中是nonrobust,这个参数的原理过于复杂,想详细了解的朋友可以自行查询相关资料。不过在大多数回归模型中,我们完全可以不考虑这个参数。
R-squared:决定系数,其值=SSR/SST,SSR是Sum of Squares for Regression,SST是Sum of Squares for Total,这个值范围在[0, 1],其值越接近1,说明回归效果越好,本例中该值为0.923,说明回归效果非常好。
Adj. R-squared:利用奥卡姆剃刀原理,对R-squared进行修正,内容有些复杂,具体方法可自行查询。
F-statistic:这就是我们经常用到的F检验,这个值越大越能推翻原假设,本例中其值为156.9,这个值过大,说明我们的模型是线性模型,原假设是“我们的模型不是线性模型”(这部分不会的人要去复习一下数理统计了)。(问题
和下面的t统计量)
Prob (F-statistic):这就是上面F-statistic的概率,这个值越小越能拒绝原假设,本例中为1.25e-08,该值非常小了,足以证明我们的模型是线性显著的。
Log likelihood:对数似然。对数函数和似然函数具有同一个最大值点。取对数是为了方便计算极大似然估计,通常先取对数再求导,找到极值点。这个参数很少使用,可以不考虑。
AIC:其用来衡量拟合的好坏程度,一般选择AIC较小的模型,其原理比较复杂,可以咨询查找资料。该参数一般不使用。
BIC:贝叶斯信息准则,其比AIC在大数据量时,对模型参数惩罚得更多,所以BIC更倾向于选择参数少的简单模型。该参数一般不使用。
coef:指自变量和常数项的系数,本例中自变量系数是4.9193,常数项是10.2779。
std err:系数估计的标准误差。
t:就是我们常用的t统计量,这个值越大越能拒绝原假设。
P>|t|:统计检验中的P值,这个值越小越能拒绝原假设。
[0.025, 0.975]:这个是置信度为95%的置信区间的下限和上限。
Omnibus:基于峰度和偏度进行数据正态性的检验,其常和Jarque-Bera检验一起使用,关于这两个检验,笔者之前给咱们公众号写过一篇名为《用Python讲解偏度和峰度》的文章,想要深入了解的读者可以去看一下。
Prob(Omnibus):上述检验的概率。
Durbin-Watson:检验残差中是否存在自相关,其主要通过确定两个相邻误差项的相关性是否为零来检验回归残差是否存在自相关。
Skewness:偏度,参考文章《用Python讲解偏度和峰度》。
Kurtosis:峰度,参考文章《用Python讲解偏度和峰度》。
Jarque-Bera(JB):同样是基于峰度和偏度进行数据正态性的检验,可参考文章《用Python讲解偏度和峰度》。
Prob(JB):JB检验的概率。
Cond. No.:多重共线性的检验,即检验变量之间是否存在精确相关关系或高度相关关系。
20210416
即使没有负样本,负样本是自己构建的
也可以基于目前自己标注的数据 检查自变量和目标变量的相关性分析
判定在现有数据上各自变量是否与目标变量相关
20210416
1.行业,省,市 与是否上下游匹配的相关性(0,1)分析 不是等级关系的属性
可以利用方差分析,直方图,或者假设检验来判断是否相关
不一定非要像回归分析一样 具有明显的相关性数值表示
2.判定两个行业之间是否有相关性 应该把两个行业合成一个字段 然后统计
其在 相关性标签 0,1 上的表现情况 而不是统计单单一个行业0,1标签数的关系
20210127
考察两列相关性 如果两列都是文字的话
可以利用模型打标为0,1 来预测考察二者是否有相关性
20210122
如果能检验出不同行业下的产品服务是显著相关的,就证明行业和产品服务是相关的
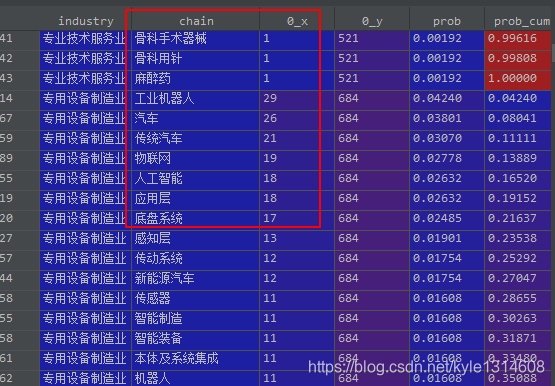
每个行业下的 不同的产品服务之间不能根据 频率来做 卡方分析
而是要根据产品服务下面的属性值 或者 属性发生的频数已经 其每组之间的均值来
判定产品服务之间是否有显著性差异
比如一个班级有几个组 每个组的人员之间同一科目有不同的得分 判定每组是否有
显著差异
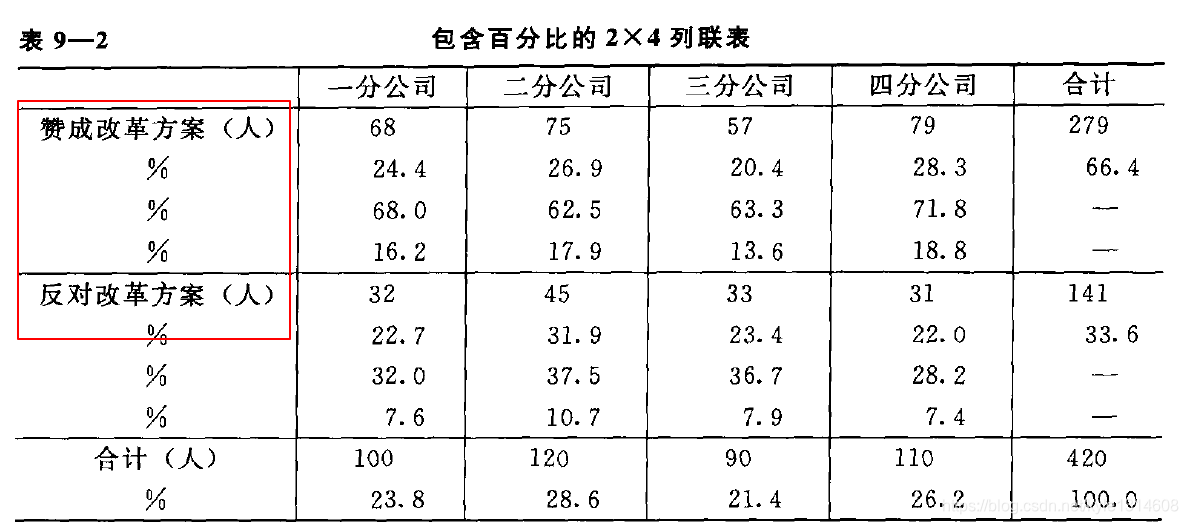
这里分组为分公司 属性为 赞成改革方案的人 根据频数来构建统计量
判定是否有显著性差异:一种是根据属性值 比如第一种,一种是根据 是否的 频数统计量
来判定
https://www.douban.com/group/topic/183750955/
首先,置信水平和置信度应该是一样的,就是变量落在置信区间的可能性,“置信水平”就是相信变量在设定的置信区间的程度,是个0~1的数,用1-α表示。
置信区间,就是变量的一个范围,变量落在这个范围的可能性是就是1-α。
显著性水平就是变量落在置信区间以外的可能性,“显著”就是与设想的置信区间不一样,用α表示。显然,显著性水平与置信水平的和为1。显著性水平为0.05时,α=0.05,1-α=0.95如果置信区间为(-1,1),即代表变量x在(-1,1)之间的可能性为0.95。0.05和0.01是比较常用的,但换个数也是可以的,计算方法还是不变。
https://blog.csdn.net/kyle1314608/article/details/112989987
假设检验总结
https://blog.csdn.net/wqhlmark64/article/details/78339622
person
spearman
kendall
三种相关系数区别
https://www.zhihu.com/question/41120789/answer/474222214
主成分分析















 7469
7469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









