







摘要
图Transformer是机器学习领域最近取得的一项进展,它为图结构数据提供了一种新的神经网络模型。 Transformer与图学习的协同作用在各种与图相关的任务中展现出强大的性能和多功能性。 本综述深入回顾了图Transformer研究的最新进展和挑战。 我们从图和Transformer的基础概念开始。 然后,我们探讨了图Transformer的设计视角,重点关注它们如何将图归纳偏差和图注意机制整合到Transformer架构中。 此外,我们提出了一个分类法,根据深度、可扩展性和预训练策略对图Transformer进行分类,总结了有效开发图Transformer模型的关键原则。 除了技术分析,我们还讨论了图Transformer模型在节点级、边级和图级任务中的应用,探讨了它们在其他应用场景中的潜力。 最后,我们确定了该领域中存在的挑战,例如可扩展性和效率、泛化性和鲁棒性、可解释性和可解释性、动态和复杂图,以及数据质量和多样性,为图Transformer研究指明了未来的方向。
关键词:
图Transformer,注意机制,图神经网络,表示学习,图学习,网络嵌入
I介绍
图作为一种具有高度表达能力的数据结构,被广泛用于表示各种领域中的复杂数据,例如社交媒体、知识图谱、生物学、化学和交通网络[1]。 它们捕获了数据中的结构和语义信息,促进了各种任务,例如推荐[2],问答[3],异常检测[4],情感分析[5],文本生成[6]和信息检索[7]。 为了有效地处理图结构数据,研究人员开发了各种图学习模型,例如图神经网络(GNNs),学习节点、边和图的有效表示[8]。 特别是,遵循消息传递框架的 GNNs 迭代地聚合邻近信息并更新节点表示,从而在各种基于图的任务上取得了令人印象深刻的性能 [9]。 从信息提取到推荐系统等各种应用都受益于 GNN 对知识图的建模 [10]。
最近,图 Transformer 作为一种新兴的强大图学习方法,在学术界和工业界引起了极大的关注 [11, 12]。 图 Transformer 研究受到 Transformer 在自然语言处理 (NLP) [13] 和计算机视觉 (CV) [14] 中取得成功的启发,并结合了 GNN 的价值。 图 Transformer 结合了图归纳偏差(例如,关于图属性的先验知识或假设)以有效地处理图数据 [15]。 此外,它们可以适应动态和异构图,利用节点和边缘特征以及属性。 [16]。 各种图 Transformer 的改编和扩展已证明了它们在解决图学习的各种挑战(例如大规模图处理)方面的优越性 [17]。 此外,图 Transformer 已成功应用于各个领域和应用,证明了其有效性和多功能性。
现有的调查没有充分涵盖图 Transformer 的最新进展和综合应用。 此外,大多数调查没有提供图 Transformer 模型的系统分类。 例如,Chen 等人 [18] 主要关注 GNN 和图 Transformer 在 CV 中的应用,但他们未能总结图 Transformer 模型的分类,并且忽略了其他领域,例如 NLP。 同样,Müller 等人 [12] 对图 Transformer 及其理论属性进行了概述,但他们没有提供对现有方法的全面综述或评估它们在各种任务上的性能。 最后,Min 等人 [19] 专注于图 Transformer 的架构设计方面,对不同组件在不同图基准上的性能进行了系统评估,但他们没有包括图 Transformer 的重要应用,也没有讨论该领域的开放性问题。
为了填补这些空白,本调查旨在从设计和应用角度对图 Transformer 研究的最新进展和挑战进行全面而系统的综述。 与现有的调查相比,我们的主要贡献如下:
- 1.
我们对图 Transformer 的设计视角进行了全面的综述,包括图归纳偏差和图注意机制。 我们将这些技术分类为不同的类型,并讨论了它们的优点和局限性。
- 2.
我们提出了一种新颖的图Transformer分类法,其基于其深度、可扩展性和预训练策略。 我们还提供了一份指南,以帮助选择针对不同任务和场景的有效图Transformer架构。
- 3.
我们回顾了图Transformer在各种图学习任务中的应用视角,以及在NLP和CV等其他领域的应用场景。
- 4.
我们确定了图Transformer研究的关键开放性问题和未来方向,例如模型的可扩展性、泛化性、可解释性和可解释性、高效的时间图学习以及数据相关问题。
本文概述如图1所示。 随后的调查结构如下:第II节介绍了与图和Transformer相关的符号和预备知识。 第III节深入探讨了图Transformer的设计视角,涵盖了图归纳偏差和图注意力机制。 第IV节介绍了图Transformer的分类法,根据其深度、可扩展性和预训练策略对其进行分类。 此外,还提供了一份指南,用于为不同的任务和领域选择合适的图Transformer模型。 第V节探讨了图Transformer在各种节点级、边级和图级任务上的应用视角,以及其他应用场景。 第VI节确定了图Transformer研究的开放性问题和未来方向。 最后,第VII节总结了本文并强调了其主要贡献。
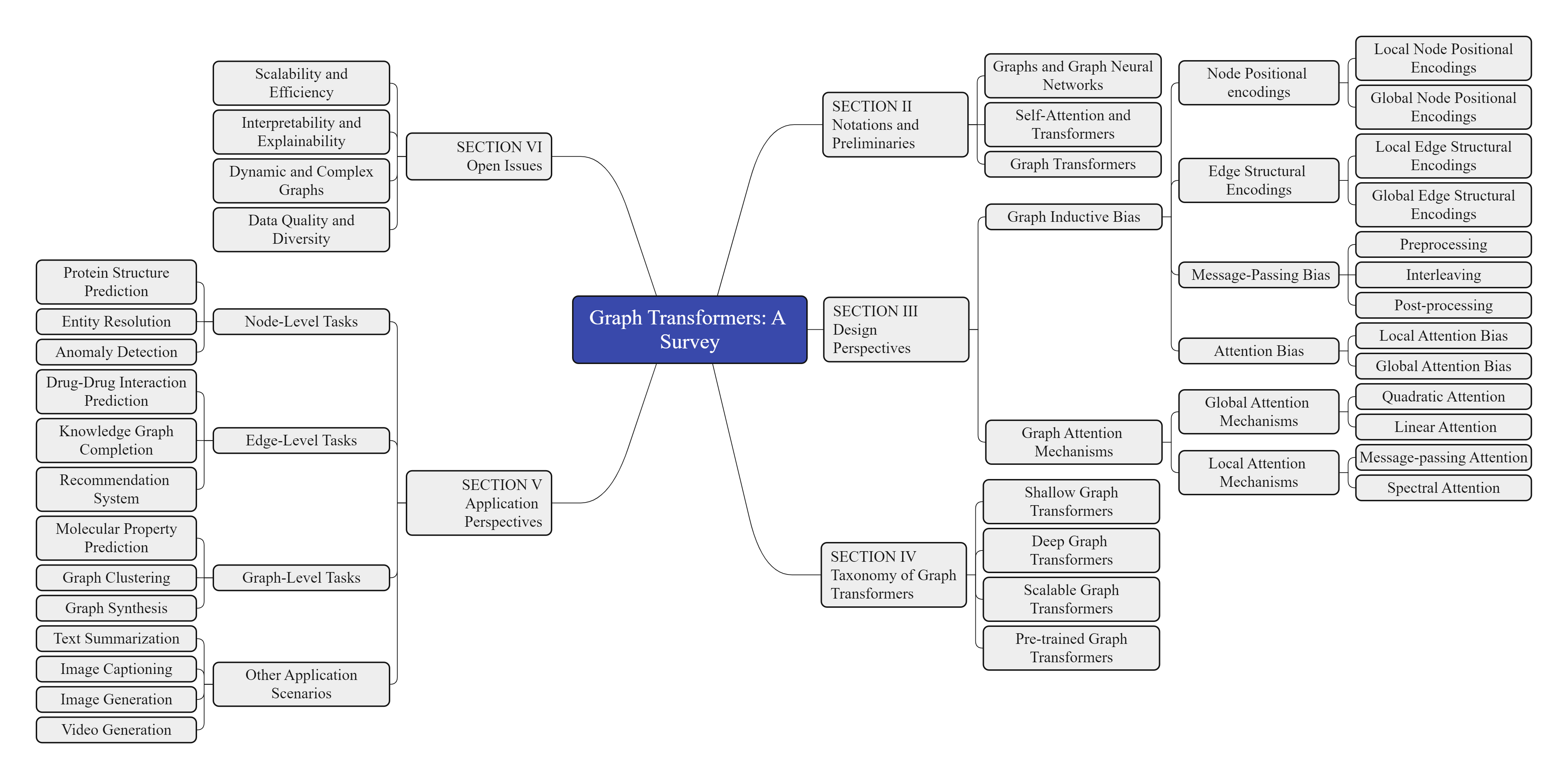
图 1: 本文组织结构
II符号和预备知识
本节将介绍本综述论文中使用的基本符号和概念。 此外,我们将简要概述当前图学习和自注意力机制的方法,这些方法是图 Transformer 的基础。 表 I 包含本文中使用的数学符号。
表 I: 本文中的符号
| Notation | Definition |
|---|---|
| G=(V,E) | A graph with node set V and edge set E |
| N | Number of nodes |
| M | Number of edges |
| A∈ℝN×N | Adjacency matrix of graph G |
| X∈ℝN×dn | Node feature matrix, xi∈X |
| F∈ℝM×de | Edge feature matrix |
| hv(l) | Hidden state of node v at layer l |
| ϕ | An update function for node states |
| ⊕ | An aggregation function for neighbor states |
| N(v) | Neighbor set of node v |
| f | A message function for the node and edge states |
| Q,K,V | Query, key and value matrices for self-attention |
| dk | Dimension of query and key matrices |
| pi | Positional encoding of node vi |
| d(i,j) | The shortest path distance between node vi and node vj |
| eij | Edge feature between node vi and node vj |
| aij | Attention score between node vi and node vj |
| W,b | Learnable parameters for the self-attention layer |
| L=IN−D−1/2AD−1/2 | Normalized graph Laplacian matrix |
| U | Eigenvectors matrix of L |
II-A Graphs and Graph Neural Networks
图是一种数据结构,它由一组节点(或顶点) V 和一组边(或链接) E 组成,这些边连接节点对。 形式上,图可以定义为 G=(V,E),其中 V={v1,v2,…,vN} 是具有 N 个节点的节点集, E={e1,e2,…,eM} 是具有 M 个边的边集。 边 ek=(vi,vj) 表示节点 vi 和节点 vj 之间的连接,其中 i,j∈{1,2,…,N} 和 k∈{1,2,…,M}。 图可以用邻接矩阵 A∈ℝN×N 表示,其中 Aij 表示节点 vi 和节点 vj 之间是否存在边。 或者,图可以用边列表 E∈ℝM×2 表示,其中 E 的每一行都包含由边连接的两个节点的索引。 图还可以具有节点特征和边特征,分别描述节点和边的属性或特性。 节点的特征可以用特征矩阵 X∈ℝN×dn 表示,其中 dn 是节点特征的维度。 边特征可以用特征张量 F∈ℝM×de 表示,其中 de 是边特征的维度 [20]。
图学习是指获取低维向量表示(也称为嵌入)的任务,这些表示用于节点、边或整个图。 这些嵌入旨在捕获图的结构和语义信息。 图神经网络 (GNN) 是一种神经网络模型,它擅长从图结构数据中学习。 它们通过沿着边传播信息和聚合来自相邻节点的信息来实现这一点 [21]。 GNN 可以分为两大类:谱方法和空间方法。
谱方法基于图信号处理和图傅里叶变换,在频域上对图进行卷积操作 [22]。 图傅里叶变换定义为 𝐗^=UTXU,其中 𝐗^ 是节点特征矩阵 X 的谱表示,U 是归一化图拉普拉斯矩阵 L=IN−D−1/2AD−1/2 的特征向量矩阵,其中 IN 是单位矩阵,D 是对角度矩阵,其中 Dii=∑j=1NAij。 谱方法可以捕获图的全局信息,但它们存在计算复杂度高、可扩展性差以及无法泛化到未见图的缺点 [23]。
空间方法基于消息传递和邻域聚合,在空间域上对图进行卷积操作 [24]。 消息传递框架定义为:
| hv(l+1)=ϕ(hv(l),⨁u∈𝒩(v)f(hu(l),hv(l),euv)), | (1) |
其中 hv(l) 是节点 v 在层 l 的隐藏状态, ϕ 是一个更新函数,⊕ 是一个聚合函数。 𝒩(v) 是节点 v 的邻居集,f 是一个依赖于节点状态和边特征的消息函数。 euv 是节点 u 和 v 之间边的特征向量。 空间方法可以捕获图的局部信息,但它们在建模长距离依赖关系、复杂交互和异构结构方面存在局限性 [25]。
II-B Self-attention and transformers
自注意力是一种机制,它使模型能够学习关注输入或输出序列的相关部分 [26]。 它计算序列中所有元素的加权和,权重由每个元素与查询向量之间的相似性决定。 形式上,自注意力定义为:
| Attention(Q,K,V)=softmax(QKTdk)V, | (2) |
其中 Q、K 和 V 分别是查询、键和值矩阵。 dk 是查询和键矩阵的维度。 自注意力机制可以捕获长距离依赖关系、全局上下文和可变长度序列,而无需使用循环或卷积。
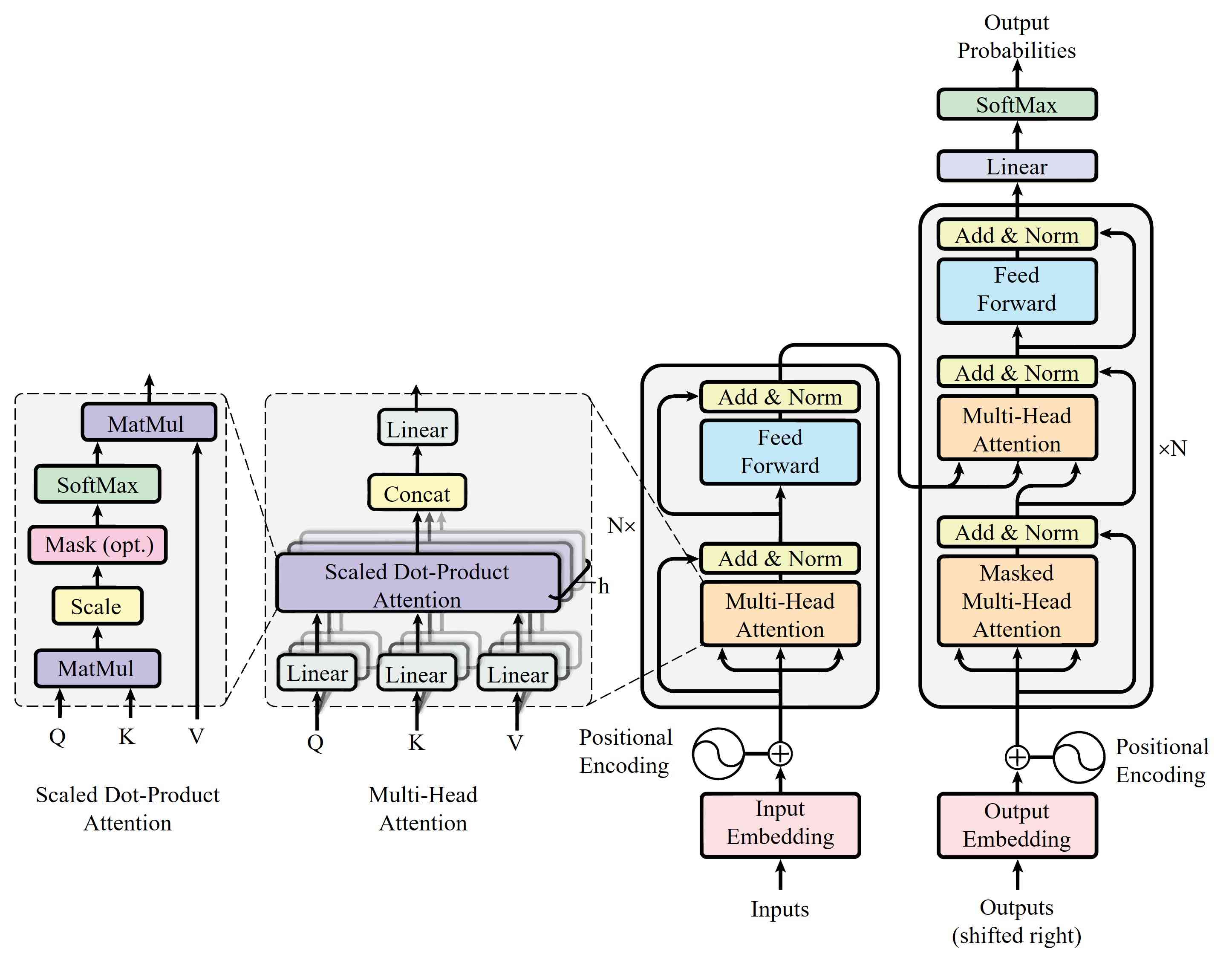
图 2: Transformer 架构的示意图 [13]。
Transformer 是神经网络模型,使用自注意力作为主要构建块 [13]。 Transformer 由两个主要组成部分组成:编码器和解码器。 编码器接收一个输入序列 X={x1,x2,…,xN} 并生成一个隐藏状态序列 Z={z1,z2,…,zN}。 解码器接收一个输出序列 Y={y1,y2,…,yN} 并生成一个隐藏状态序列 S={s1,s2,…,sN}。 解码器还使用注意力机制来关注编码器的隐藏状态。 形式上,编码器和解码器定义如下:
| zi | =EncoderLayer(xi,Z<i), | (3) | ||
| sj | =DecoderLayer(yj,S<j,Z). |
这里,EncoderLayer 和 DecoderLayer 由多个自注意力和前馈子层组成。 Transformer 在各种任务上可以取得最先进的结果,例如机器翻译 [27]、文本挖掘 [28, 29]、文档理解 [30, 31]、图像检索 [32]、视觉问答 [3]、图像生成 [33] 和推荐系统 [34, 35]。 图 2 显示了 vanilla transformer 的概述。
图 Transformer 将图归纳偏差集成到 Transformer 中,以从图结构数据中获取知识 [36]。 通过对节点和边采用自注意力机制,图 Transformer 可以有效地捕获图的局部和全局信息。 特别地,图 Transformer 表现出处理包含不同类型节点和边的异构图以及具有更高阶结构的复杂图的能力 [12, 37]。
III图 Transformer 的设计视角
本节将讨论图 Transformer 的主要架构,旨在深入探讨其设计视角。 特别地,我们将重点关注两个关键组成部分:图归纳偏差和图注意力机制,以了解这些元素如何塑造图 Transformer 模型的能力。
III-A 图归纳偏差
与文本和图像等欧几里得数据不同,图数据是非欧几里得数据,具有复杂的结构,缺乏固定的顺序和维度,这给直接在图数据上应用标准 Transformer 带来了困难 [16]。 为了解决这个问题,图 Transformer 结合了图归纳偏差来编码图的结构信息,并在新任务和领域实现 Transformer 的有效泛化。 本节将通过图归纳偏差的视角,探讨图 Transformer 的设计视角。 我们将图归纳偏差分为四类:节点位置偏差、边结构偏差、消息传递偏差和注意力偏差(见图 3)。
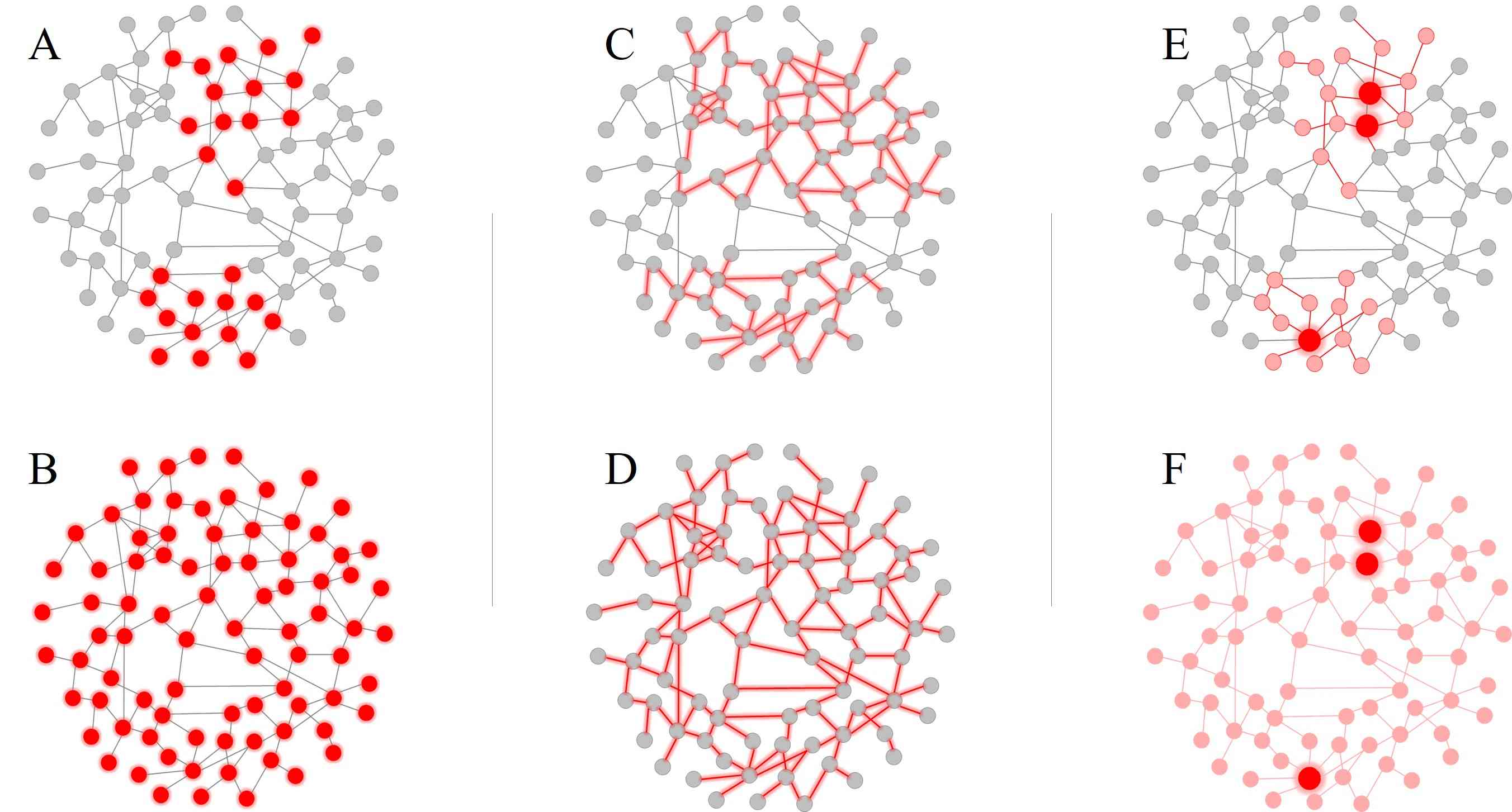
图 3: 图归纳偏差: (A) 和 (B) 分别是局部和全局节点位置偏差。 (C) 和 (D) 分别是局部和全局边结构偏差。 (E) 和 (F) 分别是局部和全局注意力偏差。 值得注意的是,消息传递偏差是一种局部注意力偏差。
III-A1 节点位置偏差
节点位置偏差是图 Transformer 的一个重要归纳偏差,因为它提供了有关图中节点的相对或绝对位置的信息 [38]。 形式上,给定一个图 G=(V,E),其中有 N 个节点和 M 条边,每个节点 vi∈V 都有一个特征向量 xi∈ℝnd。 图 Transformer 的目标是通过应用一系列自注意力层来学习每个节点的新特征向量 hi∈ℝkd。 自注意力层可以定义为:
| hi=∑j=1naijWxj+b, | (4) |
其中 aij 是节点 vi 和 vj 之间的注意力分数,衡量其特征的相关性或相似度。 W 和 b 是可学习的参数。 但是,这种自注意力机制没有考虑节点的结构和位置信息,而这对于捕获图语义和归纳偏差至关重要 [39]。 节点位置编码通过为节点提供额外的位置特征来解决此问题,这些特征反映了它们在图中的相对或绝对位置。
局部节点位置编码。 基于 NLP 中相对位置编码的成功,图 Transformer 利用类似的概念进行局部节点位置编码。 在 NLP 中,每个词元都会收到一个特征向量,该向量捕获其相对位置和与序列中其他词的关系 [40]。 同样,图 Transformer 根据节点在图中的距离和与其他节点的关系为节点分配特征向量 [41]。 这种编码技术旨在保留节点的局部连通性和邻域信息,这对于节点分类、链接预测和图生成等任务至关重要。
一种有效的集成局部节点位置信息的方法是利用独热向量。 这些向量表示节点与其相邻节点之间的跳跃距离 [11]:
| pi=[I(d(i,j)=1),I(d(i,j)=2),…,I(d(i,j)=max)]. | (5) |
在该等式中,d(i,j) 表示节点 vi 和节点 vj 之间的最短路径距离,而 I 则是一个指示函数,如果其参数为真,则返回 1,否则返回 0。 最大跳跃距离用 max 表示。 Velickovic 等人 [42] 利用这种编码技术,通过相对位置感知的自注意力机制来增强他们的图注意力网络 (GAT)。 在图中合并局部节点位置编码的另一种方法是使用可学习的嵌入,这些嵌入捕捉两个节点之间的关系 [43, 44]。 当一个节点具有多个具有不同边类型或标签的邻居时,这种方法特别有用。 在这种情况下,可以根据这些边特征学习局部节点位置编码:
| pi=[f(eij1),f(eij2),…,f(eijl)], | (6) |
其中 eij 是节点 vi 和节点 vj 之间的边特征,f 是一个可学习的函数,它将边特征映射到嵌入,而 l 是所考虑的邻居数量。
为了在更广泛的背景下增强局部节点位置编码的实现,一个可行的策略是利用图核或相似性函数来评估图中两个节点之间的结构相似性 [45, 37]。 例如,当一个节点在它的邻域中表现出三个具有独特子图模式或基序的邻居时,它的局部节点位置编码可以计算为节点与其相邻节点之间的核值的向量:
| pi=[K(Gi,Gj1),K(Gi,Gj2),…,K(Gi,Gjl)]. | (7) |
在该等式中,Gi 指的是由节点 vi 及其邻居形成的子图。 函数 K 是一个图核函数,用于测量两个子图之间的相似性。 Mialon 等人 [46] 在他们的 GraphiT 模型中利用了这种方法,该模型将图上的正定核作为图变换器的相对位置编码。
局部节点位置编码通过整合节点的结构和拓扑信息来增强图变换器的自注意力机制。 这种编码方法具有保留图结构的稀疏性和局部性的优势,从而提高了效率和可解释性。 但是,这种方法的一个局限性在于它有限的能力,无法捕捉到图的远程依赖关系或全局属性,而这些属性对于图匹配或对齐等任务至关重要。
全局节点位置编码。 全局节点位置编码的概念受 NLP 中使用绝对位置编码的启发 [47]。 在 NLP 中,如前所述,每个符元都会收到一个特征向量,指示其在序列中的位置。 将此想法扩展到图 Transformer,每个节点可以被分配一个特征向量,代表其在图的嵌入空间中的位置 [48]。 这种编码技术的目的是封装图的整体几何形状和频谱,从而揭示其内在属性和特征。
一种获得全局节点位置编码的方法是利用矩阵表示的特征向量或特征值,例如邻接矩阵或拉普拉斯矩阵 [39]。 例如,如果一个节点的坐标位于图拉普拉斯的前 k 个特征向量内,则其全局节点位置编码可以用坐标向量表示:
| pi=[ui1,ui2,…,uik], | (8) |
其中 uij 是图拉普拉斯矩阵的第 j 个特征向量的第 i 个分量。 将全局节点位置编码纳入的一种替代方法是利用扩散或随机游走技术,例如个性化 PageRank 或热核 [49]。 例如,如果一个节点在图中所有其他节点上拥有一个概率分布,遵循随机游走 [50],则其全局节点位置编码可以用此概率向量表示:
| pi=[πi1,πi2,…,πiN], | (9) |
其中 πij 是在图上执行随机游走后从节点 vi 到达节点 vj 的概率。
实现全局节点位置编码的一种更普遍的方法是利用图嵌入或降维技术,将节点映射到低维空间,同时保持相似度或距离感 [51]。 例如,如果一个节点在通过对图应用多维标度或图神经网络而得出的空间中拥有坐标,则其全局节点位置编码可以用该坐标向量表示:
| pi=[yi1,yi2,…,yik], | (10) |
其中 yij 是 k 维空间中第 i 个节点嵌入的第 j 个分量,它可以通过最小化保留图结构的目标函数来获得:
| minY∑i,j=1Nwij‖yi−yj‖2. | (11) |
这里,wij 是一个权重矩阵,反映了节点 vi 和节点 vj 之间的相似性或距离,Y 是节点嵌入矩阵。
全局节点位置编码的主要目标是通过将图的几何和光谱信息纳入图 Transformer,来改进节点属性的表示。 这种编码方法的优势在于能够捕获长距离依赖关系和整体图特征,从而有利于图匹配和对齐等任务。 但是,这种编码方法的一个缺点是,它可能会破坏图结构的稀疏性和局部性,从而可能影响效率和可解释性。
III-A2 边缘结构偏差
在图 Transformer 的领域中,边缘结构偏差对于从图结构中提取和理解复杂信息至关重要 [52]。 边缘结构偏差用途广泛,可以表示图结构的各个方面,包括节点距离、边类型、边方向和局部子结构。 实证证据表明,边缘结构编码可以提高图 Transformer 的有效性 [53, 54, 55]。
局部边缘结构编码。 局部边缘结构编码通过对两个节点之间的相对位置或距离进行编码来捕获图的局部结构 [52]。 这些编码借鉴了 NLP 和 CV 中使用的相对位置编码的思想,其中它们用于对标记或像素的顺序或空间顺序进行建模 [56]。 但是,在图的背景下,由于存在多个具有不同长度或权重的连接路径,节点之间的相对位置或距离的概念变得模棱两可。 因此,科学界提出了各种方法来专门针对图结构定义和编码此信息。
GraphiT [46] 将局部边缘结构编码引入图 Transformer。 它促进了对图上使用正定核来衡量节点相似性,同时考虑它们之间的最短路径距离。 核函数定义如下:
| k(u,v)=exp(−αd(u,v)), | (12) |
其中 u 和 v 是图中的两个节点,d(u,v) 是它们的 最短路径距离,α 是控制 衰减率的超参数。 然后使用核函数来修改 两个节点之间的自注意力分数:
| Attention(Q,K,V)=softmax(QKTdk+k(Q,K))V, | (13) |
其中 k(Q,K) 是为每对节点计算的内核值矩阵。 EdgeBERT [57] 建议使用边缘特征作为图 Transformer 的额外输入符元。 这些边缘特征是通过对每条边的源节点和目标节点特征应用可学习函数获得的。 然后将生成的边缘特征与节点特征连接起来,并馈送到标准的 Transformer 编码器中。
最近,增强边缘的图 Transformer (EGT) [58] 引入了残差边缘通道,作为一种直接处理和输出结构和节点信息的机制。 残差边缘通道是矩阵,用于存储每对节点的边缘信息。 它们初始化为邻接矩阵或最短路径矩阵,并在每个 Transformer 层通过应用残差连接进行更新。 然后,这些通道用于调整两个节点之间的自注意力得分
| Attention(Q,K,V,Re)=softmax(QKTdk+Re)V, | (14) |
其中 Re 是残差边缘通道矩阵。
尽管局部边缘结构编码可以捕获详细的结构信息,但它们在捕获整体结构信息方面可能存在局限性。 这会导致计算复杂度或内存使用量增加,因为需要计算和存储成对信息。 此外,这些编码的有效性可能会因针对不同图和任务的编码或内核函数的选择和优化而异。
全局边缘结构编码。 全局边缘结构编码旨在捕获图的整体结构。 与 NLP 和 CV 领域不同,节点在图中的确切位置没有明确定义,因为没有自然的顺序或坐标系 [59]。 已经提出了一些方法来解决这个问题。
GPT-GNN [60] 是一项早期工作,它利用图池化和反池化操作来编码图的层次结构。 它通过对相似节点进行分组来减少图的大小,然后通过将聚类特征分配给单个节点来恢复原始大小。 这种方法可以生成图的多尺度表示,并在各种任务中展现出增强的性能。 Graphormer [11] 使用谱图论来编码全局结构。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











