







 ViT通过将图像转换为序列并应用Transformer架构,在大量数据上预训练后,展现出超越CNN的效果。尽管在小数据集上表现不及CNN,但Transformer在处理复杂关联和多模态任务时表现出优势,开启了视觉与NLP领域融合的新篇章。
ViT通过将图像转换为序列并应用Transformer架构,在大量数据上预训练后,展现出超越CNN的效果。尽管在小数据集上表现不及CNN,但Transformer在处理复杂关联和多模态任务时表现出优势,开启了视觉与NLP领域融合的新篇章。
1视频链接
视频如下:
ViT论文精读
ViT的出现,撼动了2012年以来AlexNet的统治地位。
2总结
将NLP领域的transformer转到视觉领域,通过将图像分割成多个patch的方法将图片序列化,其他与transformer一样。取得了很好的效果。但是在小数据集上没有CNN好。扩大数据集后效果超过CNN。
3正文
他的结论是:
如果在足够多的数据上做预训练,也可以不需要卷积神经网络,直接用从NLP领域搬过来的transformer也能把视觉问题解决的很好。不只是视觉领域,在多模态领域也给大家留下了无限想象。(transofrmer本来是NLP领域,现在在视觉领域也效果很好,打破类视觉与NLP的壁垒)
paperwithcode.com可以看ViT效果
先来看一篇论文:
Intriguing Properties of Vision Transformers
有对这篇论文的解析:
Intriguing Properties of Vision Transformers论文解析
论文中提到对于遮挡、Distribution shift、Adversarial patch、permuration,transformer都比CNN好。

3.1 论文链接
下面开始论文精读,论文链接如下:
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
3.2 论文题目
16X16意思是把图片切成16X16的patch
3.3 transformer用于视觉的问题

transformer考虑了两两之间的关联,复杂度是
O
(
n
2
)
O(n^2)
O(n2),n是序列长度。目前的硬件也就支持到几百上千。BERT的序列长度n=512.
首先遇到的问题:将2D的图片转变成1D的序列
如果是每个像素看作是一个序列元素,这个复杂度就太高了。比如
224
∗
224
=
50176
224*224=50176
224∗224=50176,50176的序列长度比512大100倍。transformer的做法是,把图片分成不同的patch,每个patch是
16
∗
16
16*16
16∗16,这样长可宽都有224/16=14个patch。也就是序列长度是14*14=196.这个长度是可以接受的长度。

| 原文 | 翻译 |
|---|---|
| Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion. | 受NLP中Transformer缩放成功的启发,我们尝试将标准Transformer直接应用于图像,并进行最少的修改。为此,我们将图像分割为多个补丁,并将这些补丁的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像补丁的处理方式与标记(单词)相同。我们以监督的方式训练模型进行图像分类。 |
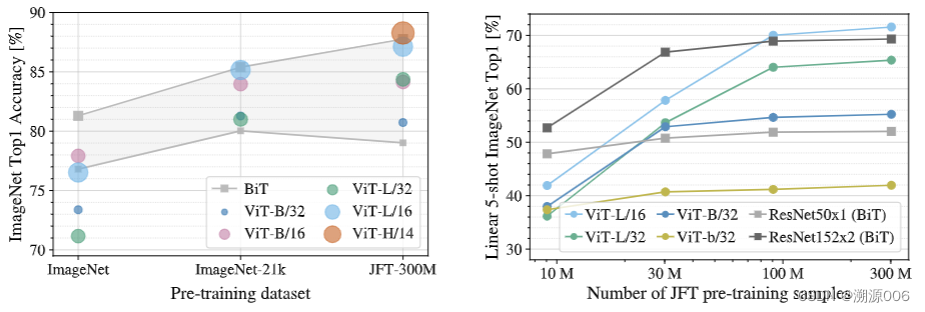
| When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. This seemingly discouraging outcome may be expected: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data. | 当在没有强正则化的中型数据集(如ImageNet)上训练时,这些模型产生的适度精度比可比大小的ResNets低几个百分点。这种看似令人沮丧的结果可能是意料之中的:Transformers缺乏CNN固有的一些归纳偏置,如translation equivariance和locality,因此在数据量不足的情况下训练时得不到很好的泛化能力。 |
| However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias. Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT approaches or beats state of the art on multiple image recognition benchmarks. In particular, the best model reaches the accuracy of 88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55% on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks. | 然而,如果模型在更大的数据集(14M-300M图像)上训练,情况就会发生变化。我们发现大规模训练优于归纳偏置。我们的 Vision Transformer (ViT)在足够规模的预训练和转移到数据点更少的任务时获得了出色的结果。当在公共ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViT在多个图像识别基准测试中接近或超过了最先进的水平。其中,最佳模型在ImageNet上的准确率为88.55%,在ImageNet- real上的准确率为90.72%,在CIFAR-100上的准确率为94.55%,在VTAB套件的19个任务上的准确率为77.63%。 |
3.4 模型总览
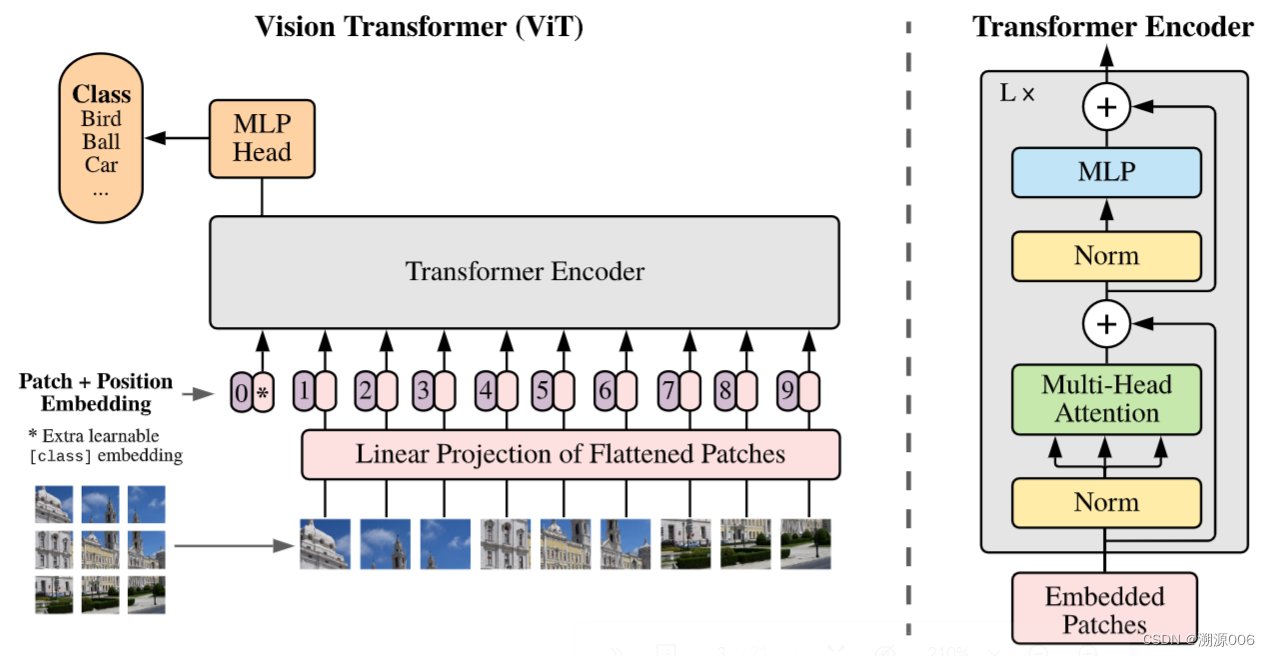
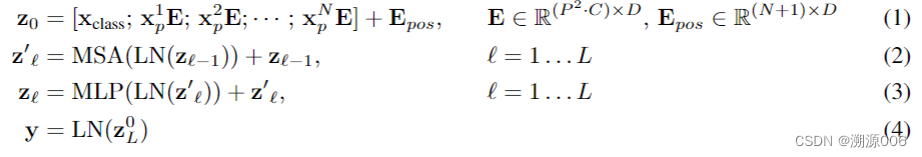
步骤:
- 进入transformer前的预处理
1)图片---->序列:比如是 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3的图像,patch size是 16 ∗ 16 ∗ 3 16*16*3 16∗16∗3,那么一个图像就会有 ( 224 / 16 ) 2 = 1 4 2 = 196 (224/16)^2=14^2=196 (224/16)2=142=196个patch,每个patch((1)式中的 x p i x_p^i xpi)展开成向量是 16 ∗ 16 ∗ 3 = 768 16*16*3=768 16∗16∗3=768维。总共是 196 ∗ 768 196*768 196∗768
2)线性投射层((1)式中的E)就是一个全连接层,是768*768,经过线性投射层得到patch embedding.还是 196 ∗ 768 196*768 196∗768,意思是有196个token,每个token的维度是768
3)要加一个特殊的[class] token(可以学习的,(1)式中的 x c l a s s x_{class} xclass),所以最终的是 197 ∗ 768 197*768 197∗768
4)还要加位置编码的信息((1)式中的 E p o s E_{pos} Epos),每个位置信息也是768的向量,是可以学习的,然后加到patch embedding上(不是拼接,是加)。所以还是 197 ∗ 768 197*768 197∗768 - 进入transformer
1)过layer Norm(LN)还是 197 ∗ 768 197*768 197∗768
2)做多头自注意力(MSA),出来还是 197 ∗ 768 197*768 197∗768
3)过layer Norm还是 197 ∗ 768 197*768 197∗768
4)MLP,先扩大 197 ∗ 3072 197*3072 197∗3072,再还原 197 ∗ 768 197*768 197∗768
transformer可以叠加
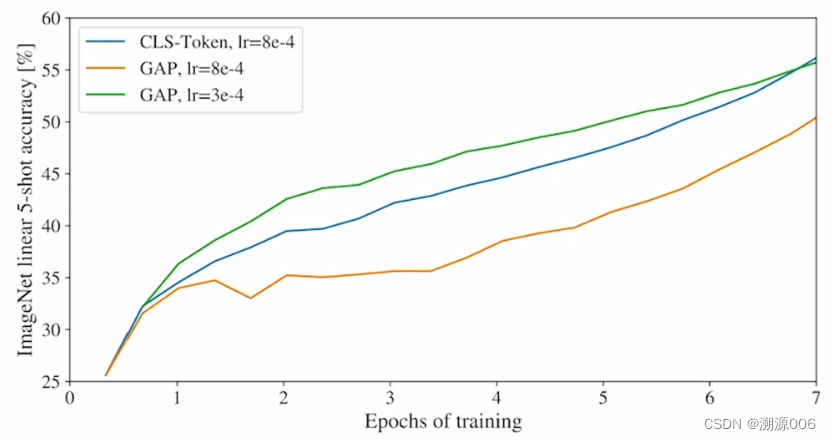
3.5 [class] token
[class] token作为图像的整体特征.传统的RES网络是在最后的特征图加GAP(全局平均池化)。ViT也可以这么做,从实验来看效果差不多(lr不一样,所以需要调整超参,炼丹技术要过硬),但是为了与NLP的transformer保持一致,就沿用了[class] token
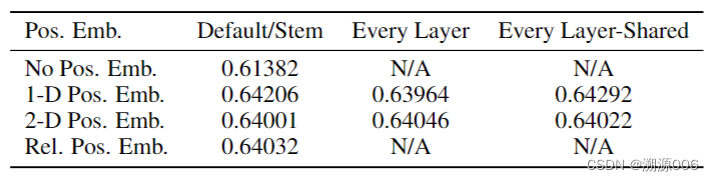
3.6 position embedding
有位置编码比没有位置编码好,1D还是2D效果差不多
3.7 小数据用CNN,大数据用Transformer效果更好
3.8 自监督
自监督的效果不是很好,与对比学习的结合作为未来的工作。MOCO v3,DINO都是运用对比学习去训练visual transformer
3.9 后记
ViT挖了一个大坑,你可以从任何一个角度去提高他。
1)分类----->检测------>分割
2)改tokenlization的方式
3)改tansformer block(有人把self-attention换成MLP还是可以工作的很好)
4)mataformer认为tansformer work的原因是其架构,直接把self-attention换成池化,也可以取得很好的效果
5)目标函数:有监督、无监督、对比学习
6)打开了多模态的坑,视频、音频、多模态
名词解释
- inductive biases(归纳偏置):可以理解为一些针对特定任务的预先的知识或者操作

















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









