







多分类loss
多分类用到的loss:
-
NLLLoss :Negative Log Likelihood Loss
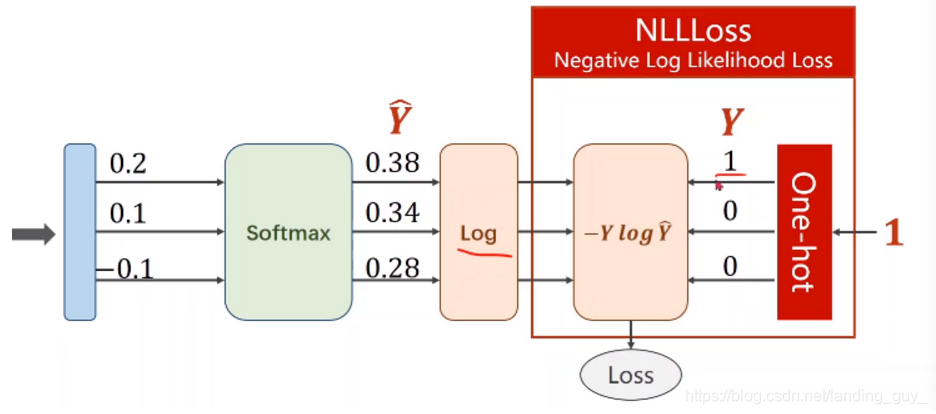
输入端是softmax经过log之后的值,不过这里要注意,y可以是one-hot形式,也可以是是单纯的数像[2, 3, 4]这种 -
CrossEntropyLoss就是把以上Softmax–Log–NLLLoss合并成一步
例子
- 这里以Mnist数据集为例
# 加载库
import torch # 这是总的
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms # 这三句是对数据集相关的
import torch.nn as nn
import torch.nn.functional as F # 这两句是对神经网络的
# 设置参数
batch_size = 64
num_workers = 2
# 先对数据相关的数据进行设置
learning_rate = 0.001
num_epoches = 20
device = "cuda" if torch.cuda.is_available() else "cpu"
# 对训练过程参数进行设置
# 处理数据集
train_data = datasets.MNIST(root='./dataset/mnist', train=True, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_data = datasets.MNIST(root='./dataset/mnist', train=False, download=True, transform=transforms.ToTensor())
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
# 搭建模型
class NN(nn.Module):
def __init__(self, input_dim, output_dim):
super(NN, self).__init__()
self.fc1 = nn.Linear(input_dim, 50)
self.fc2 = nn.Linear(50, output_dim)
def forward(self, x):
x = x.reshape(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 在正式处理数据前可以简单验证一下维度, 一个好习惯
"""
model = NN(28*28, 10)
x = torch.rand(64, 1, 28, 28)
print(model(x).shape)
>>
torch.Size([64, 10])
"""
# 实例化模型,设置损失函数
model = NN(784, 10).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 定义检查正确率函数
def check_accuracy(epoch, loader, model):
num_correct = 0
num_samples = 0
model.eval() # 这句很重要,在model(test_datasets)之前,需要加上model.eval().
# 否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有batch normalization层所带来的的性质。
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device)
scores = model(x)
_, preds = scores.max(1) # max函数pred里面是索引
num_correct += (preds==y).sum()
num_samples += preds.size(0)
print(f'Got Batch:{epoch+1}, {num_correct} / {num_samples} with accuracy {float(num_correct)/float(num_samples)*100:.2f}')
model.train() # 再把模型返回
# 开始训练
if __name__ == "__main__": # 不加会出一些错误
for epoch in range(num_epoches):
for index, (images, labels) in enumerate(train_loader): # 这里注意括号
images = images.to(device)
labels = labels.to(device)
scores = model(images)
loss = criterion(scores, labels) # 这里注意有个坑,如果是labels在前就会报错,是因为维度的原因
optimizer.zero_grad() # 因为训练的过程通常使用mini-batch方法,所以如果不将梯度清零的话,
# 梯度会与上一个batch的数据相关,因此该函数要写在反向传播和梯度下降之前。
loss.backward()
optimizer.step()
check_accuracy(epoch, test_loader, model)
# 检查正确性
这里要注意的就是model.eval(), 以及训练时候损失函数数据传入的顺序
附录
一个相当简单的线性层的运用
import torch
x=torch.tensor([[2, 4, 6]], dtype=torch.float32).reshape(3,1)
y = torch.tensor([[4, 8, 12]], dtype=torch.float32).reshape(3, 1)
class Linear_layer(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(Linear_layer, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
learn_rate = 0.001
iters = 10000
Linear = Linear_layer(1, 1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(Linear.parameters(), lr=learn_rate)
def train(iters):
for i in range(iters):
y_pred = Linear(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=', Linear.linear.weight)
print('b=', Linear.linear.bias)
if __name__ == "__main__":
train(iters)
















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











