







1 项目背景
在今天产品高度同质化的阶段,市场竞争不断加剧,企业与企业之间的竞争,主要集中在对客户的争夺上。“用户就是上帝”促使众多企业不惜代价去争夺尽可能多的新客户。但是,在企业不惜代价发展新用户的过程中,往往会忽视老用户的流失情况,结果就导致出现新用户在源源不断的增加,辛苦找来的老用户却在悄无声息的流失的窘状。
如何处理客户流失的问题,成为一个非常重要的课题。那么,我们如何从数据汇总挖掘出有价值的信息,来防止客户流失呢?
2 项目目标
挖掘出影响用户流失的关键因素,预测客户的转化效果以及用K-means对用户进行画像,
并针对不同的用户类别,提出可行的营销建议
3 数据理解
1.数据概况
训练集userlostprob_train.txt 共689946条记录,测试集userlostprob_test.txt 共435076条记录,测试集不提供目标变量label,需自行预测。为保护客户隐私,不提供uid等信息。此外,数据经过了脱敏,和实际商品的订单量、浏览量、转化率等有一些差距,但是不会影响这个问题的可解性。
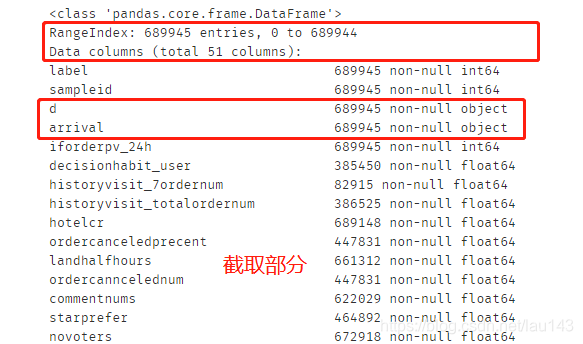
数据集包含51列变量信息,除去id列和目标变量label外,还有49列变量。
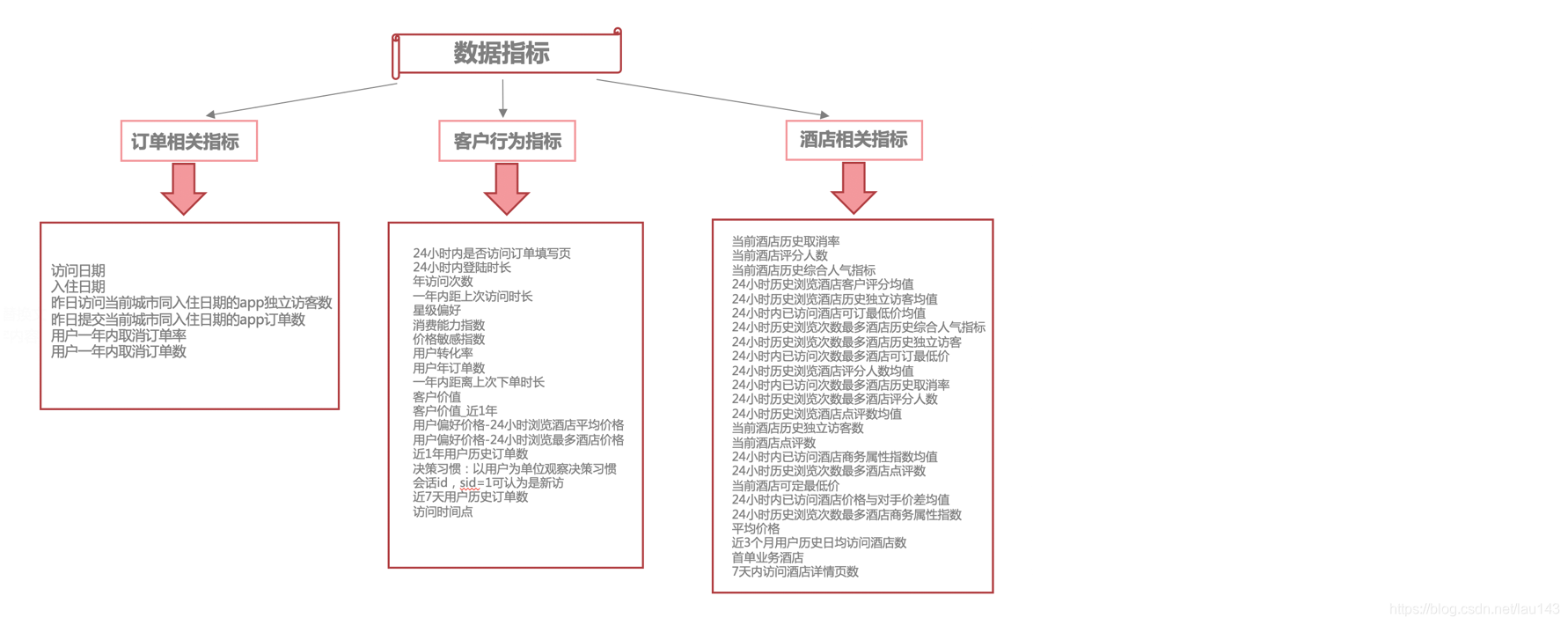
2.数据指标分析
观察数据集,并进行指标梳理。除去id和label外,数据指标可以分为三类,一类是订单相关的指标,如入住日期、订单数、取消率等,共10个指标;一类是与客户行为相关的指标,如星级偏好、用户偏好价格等。共17个指标;还有一类是与酒店相关的指标,如酒店评分均值、酒店评分人数、平均价格等,共22个指标。
4 数据处理
4.1 导入数据
#导入基础包
%matplotlib inline
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#读取数据
df = pd.read_csv('./data/userlostprob_train.txt',sep='\t')
df.head(2)
4.2 查看数据信息
df.info()
4.3 衍生变量
添加新列:提前预订 = 入住时间-访问时间
入住时间和访问时间数据格式为’object,需转换成日期型格式
# 转为日期型格式
df['arrival']=pd.to_datetime(df['arrival'])
df['d']=pd.to_datetime(df['d'])
# 相减得到“提前预定天数”列
df['day_advanced']=(df['arrival']-df['d']).dt.days
# 删除原有列
df=df.drop(['d','arrival'],axis=1)
4.4 异常值处理
# 查看数值型数据描述统计信息
df.describe()
通过描述统计观察发现,delta_price1、delta_price2、lowestprice、customer_value_profit、ctrip_profits这几个变量最小值为负值,需要对其处理。同时,结合四分位和极值,发现有极大或极小的异常值,如decisionhabit_user、historyvisit_avghotelnum等,较多字段都存在异常值,对所有字段一并进行处理。
for col in ['delta_price1','delta_price2','lowestprice']:
df.loc[df[col]<0,col]=df[col].median() # 填充中位数
for col in ['customer_value_profit','ctrip_profits']:
df.loc[df[col]<0,col]=0 # 填充0
#极值处理
for i in df.columns:
df.loc[df[i]<np.percentile(df[i],1),i]=np.percentile(df[i],1)
df.loc[df[i]>np.percentile(df[i],99),i]=np.percentile(df[i],99)
4.5 缺失值处理
#查看各列缺失情况,并统计
df_count = df.count()
na_count = len(df) - df_count
na_rate = na_count/len(df)
#按values正序排列,不放倒序是为了后边的图形展示排列
a = na_rate.sort_values(ascending=True)
a1 = pd.DataFrame(a)
#绘图查看缺失情况
#用来正常展示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
x = df.shape[1]
fig = plt.figure(figsize=(8,12)) #图形大小
plt.barh(range(x),a1[0],color='steelblue',alpha=1)
plt.tick_params(axis='both',labelsize=14)
plt.xlabel('数据缺失占比') #添加轴标签
columns1 = a1.index.values.tolist() #列名称
plt.yticks(range(x),columns1)
plt.xlim([0,1]) #设置X轴的刻度范围
for x,y in enumerate(a1[0]):
plt.text(y,x,'%.3f' %y,va='bottom')
plt.show()
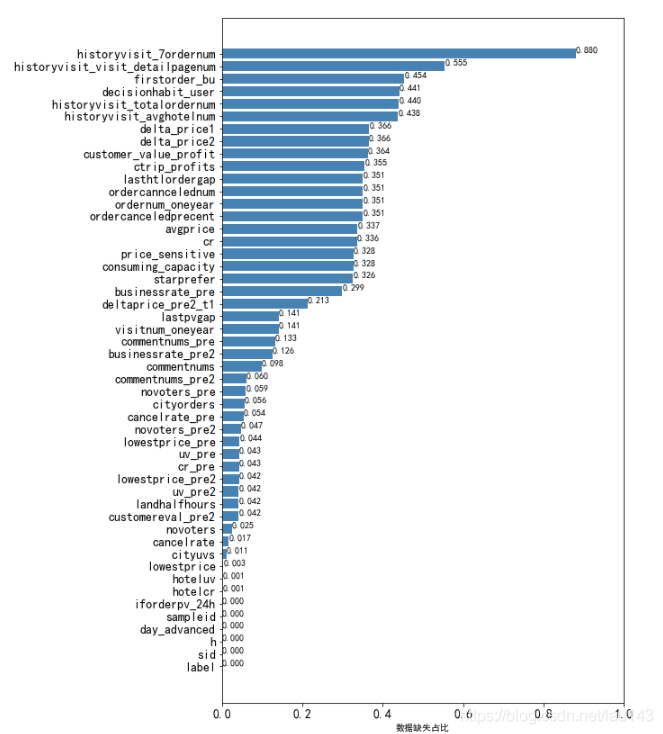
缺失值删除
特征值中只有iforderpv_24h、sid、h、day_advanced这四个是不存在缺失的,其他的44个特征都是存在缺失值的,并且大部分的缺失值都挺多的,因此需要对缺失值进行处理
利用dropna(thresh=n)过滤方式,删除行列缺失值大于80%的数据。
# 删除缺失值比例大于80%的行和列
print('删除空值前数据维度是:{}'.format(df.shape))
df.dropna(axis=0,thresh=df.shape[1]*0.2,inplace=True)
df.dropna(axis=1,thresh=df.shape[0]*0.2,inplace=True)
print('删除空值后数据维度是:{}'.format(df.shape))
'''
删除空值前数据维度是:(689945, 50)
删除空值后数据维度是:(689870, 49)
'''
缺失值补充
趋于正态分布的字段,使用均值填充:businessrate_pre2、cancelrate_pre、businessrate_pre;
偏态分布的字段,使用中位数填充.。
df.hist(figsize=(20,20))
plt.savefig('hist.png')
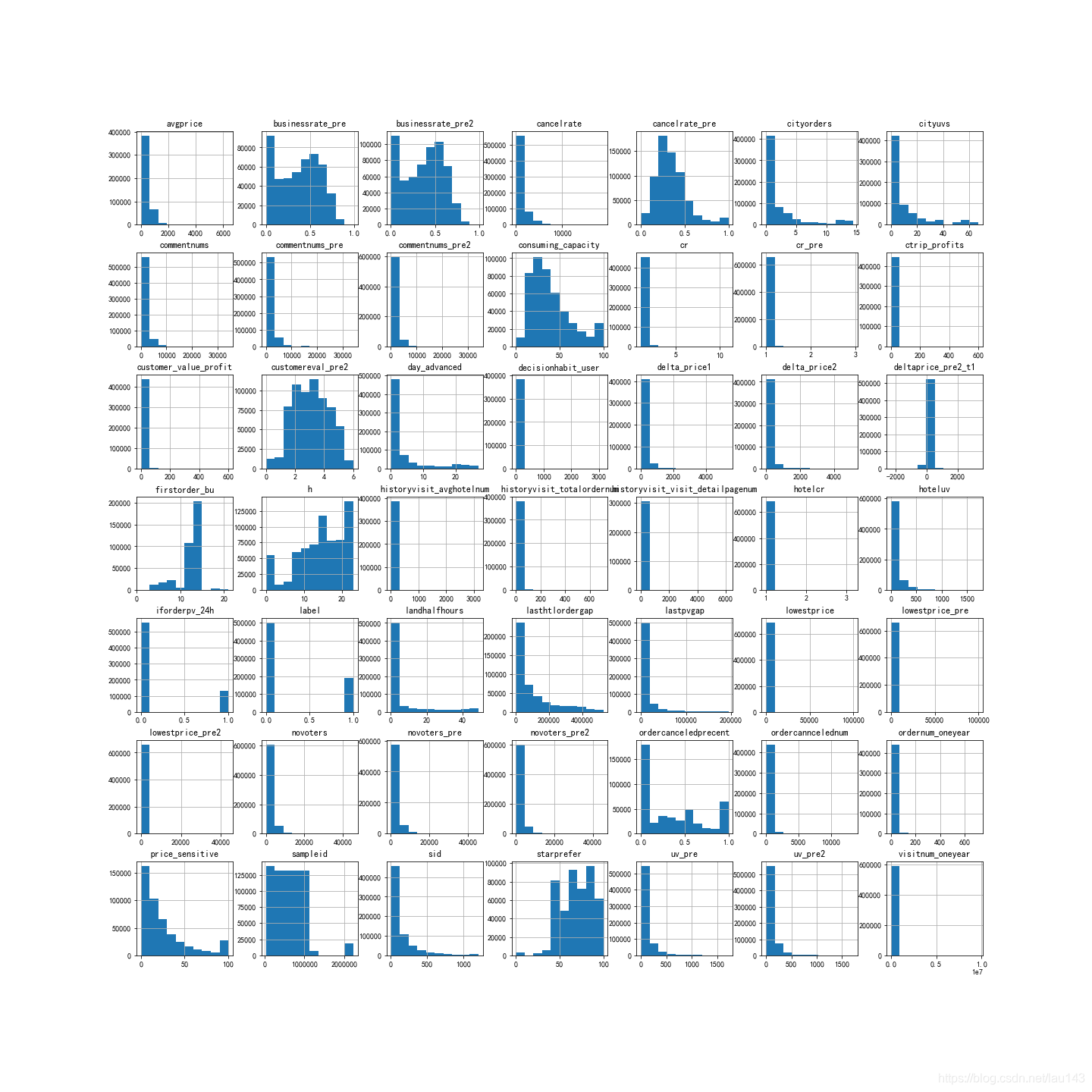
通过上图看出’businessrate_pre’,‘businessrate_pre2’,‘cancelrate_pre’,'customereval_pre2 '这些字段大体服从正态分布,可以用均值填充;其余字段大都呈右偏态分布,右偏分布就不可以用均值填充了,因为会受到极值的影响,但中位数不太受异常值或者极值的影响,使用中位数填充比较合适。
filter_mean=['businessrate_pre','businessrate_pre2','cancelrate_pre','customereval_pre2 ']
for i in df.columns:
if i in filter_mean:
df[i].fillna(df[i].mean(),inplace=True)
else:
df[i].fillna(df[i].median(),inplace=True)
4.6 极值处理
通过上面数据描述分析,数据集中还存在极值,过大或者过小的值会对模型分析造成影响,这里通过截断填充的方式,分别对极小值和极大值进行处理。
盖帽法:某连续变量6西格玛之外的记录用正负3西格玛值替代,一般正负3西格玛包含99%的数据,所以默认凡小于百分之一分位数和大于百分之九十九分位数的值用百分之一分位数和百分之九十九分位数代替,俗称盖帽法
# 盖帽法
for i in df.columns:
#小于1%分位数的用1%分位数填充
df.loc[df[i]<np.percentile(df[i],1),i]=np.percentile(df[i],1)
# 大于99%分位数的用99%分位数填充
df.loc[df[i]>np.percentile(df[i],99),i]=np.percentile(df[i],99)
5 特征工程
5.1 相关性分析
观察整个数据集可以大体分为两个类别:用户信息和酒店信息。
用户信息,即主体是用户,如consuming_capacity (消费能力指数)、price_sensitive(价格敏感指数)、starprefer(星级偏好)等,这些变量主要描述的是用户信息;
酒店信息,即主体是酒店,如hotelcr (当前酒店历史cr),commentnums (当前酒店点评数)、novoters (当前酒店评分人数)等,这些变量主要描述的酒店信息。
用户特征的相关性分析
# 用户特征提取
user_features=['visitnum_oneyear','starprefer','sid','price_sensitive','ordernum_oneyear','ordercanncelednum','ordercanceledprecent','lastpvgap',
'lasthtlordergap','landhalfhours','iforderpv_24h','historyvisit_totalordernum','historyvisit_avghotelnum','h',
'delta_price2','delta_price1','decisionhabit_user','customer_value_profit','ctrip_profits','cr','consuming_capacity','avgprice']
#生成用户特征的相关性矩阵
user_corr=df[user_features].corr()
#绘制用户特征的相关性矩阵热度图
fig,ax = plt.subplots(figsize=(18, 12))
sns.heatmap(user_corr,
xticklabels=True,
yticklabels=True,
square=False, linewidths=.5,
annot=True, cmap="YlGnBu")
plt.savefig('./用户特征的相关性分析.jpg',dpi=400, bbox_inches='tight')
plt.show()
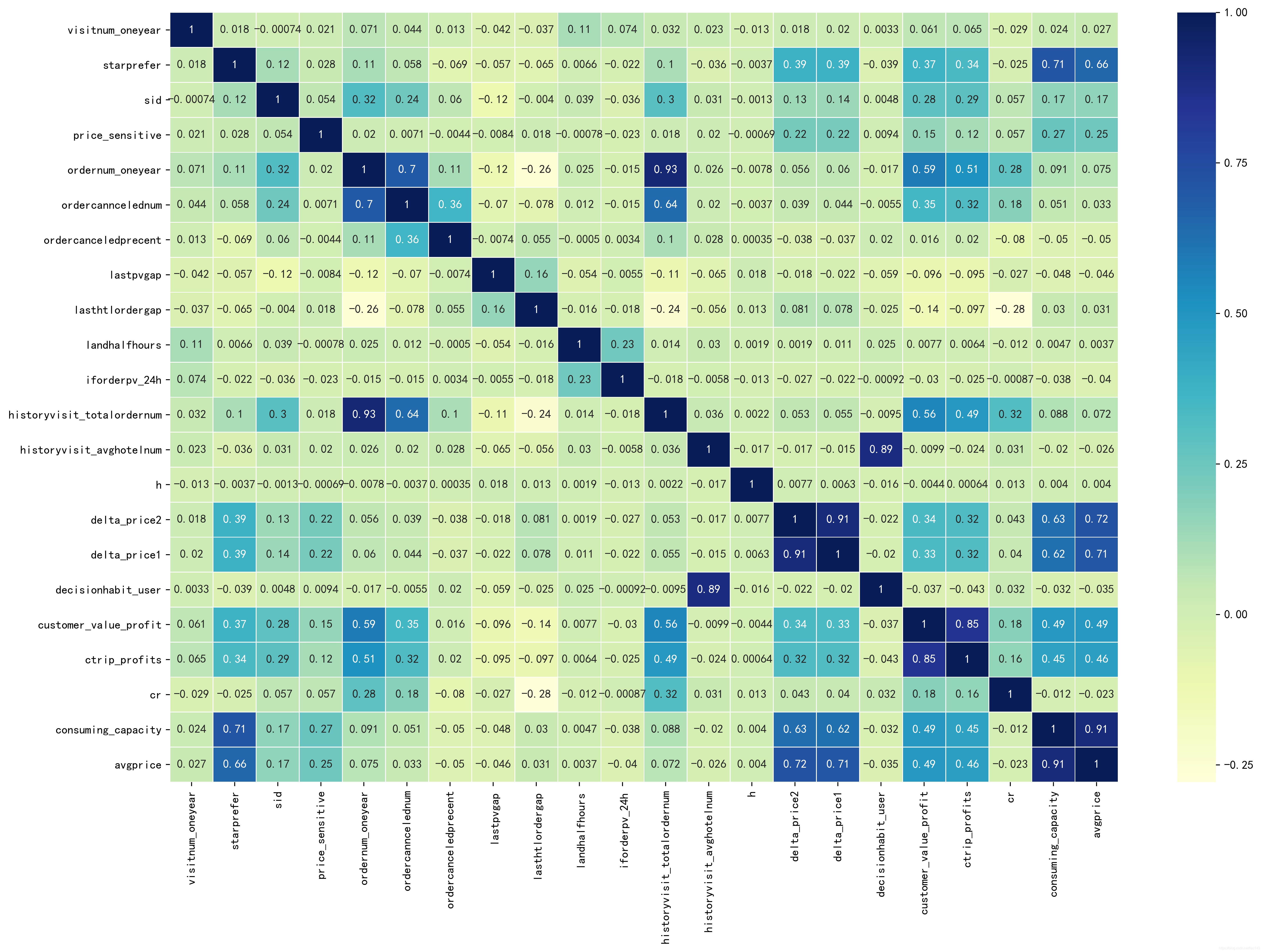
从热图中看出:
- ordernum_oneyear和historyvisit_totalordernum的相关性高达0.93,两者都是表示用户1年内订单数,特征选取时可以只选择其一,这里选择ordernum_oneyear作为用户年订单数的特征;
- delta_price1和delta_price2的相关性达到了0.91,前者表示用户偏好价格-24小时浏览最多酒店价格,后者表示用户偏好价格-24小时浏览酒店平均价格,一定程度上说明浏览最多的酒店价格影响着平均价格,可以理解为众数和平均数的关系,这里选择PCA提取一个主成分表示用户价格偏好;
- decisionhabit_user和historyvisit_avghotelnum相关性达到了0.89,前者表示用户决策习惯,后者表示近3个月用户历史日均访问酒店数,说明用户的决策习惯可能是基于用户近3个月的日均访问数判定的,这里选择用PCA提取一个主成分表示用户近期的日均访问量;
- customer_value_profit和ctrip_profits这两个特征之间相关性达到了0.85,前者表示用户近一年的价值,后者也表示用户价值,细分区别在于衡量的时间长度不同,这里也选择PCA提取一个主成分表示用户价值。
酒店信息特征的相关性分析
# 酒店信息特征的相关性分析
hotel_features=['hotelcr','hoteluv','commentnums','novoters','cancelrate','lowestprice','cr_pre','uv_pre','uv_pre2','businessrate_pre',
'businessrate_pre2','customereval_pre2','commentnums_pre','commentnums_pre2','cancelrate_pre','novoters_pre','novoters_pre2',
'deltaprice_pre2_t1','lowestprice_pre','lowestprice_pre2','firstorder_bu','historyvisit_visit_detailpagenum']
#生成酒店特征的相关性矩阵
user_corr1 = df[user_features].corr()
#绘制用户特征的相关性矩阵热度图
fig,ax = plt.subplots(figsize=(18, 12))
sns.heatmap(user_corr1,
xticklabels=True,
yticklabels=True,
square=False, linewidths=.5,
annot=True, cmap="YlGnBu")
plt.savefig('./酒店信息特征的相关性分析.jpg',dpi=400, bbox_inches='tight')
plt.show()
5.2 特征降维
在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
- 主成分分析
相关性大于80%的变量进行降维
# 用户价值
c_value=['customer_value_profit','ctrip_profits']
# 用户消费水平
consume_level=['avgprice','consuming_capacity']
# 用户偏好价格
price_prefer=['delta_price1','delta_price2']
# 酒店热度
hotel_hot=['commentnums','novoters']
# 24小时内浏览次数最多的酒店热度
hotel_hot_pre=['commentnums_pre','novoters_pre']
# 24小时内浏览酒店的平均热度
hotel_hot_pre2=['commentnums_pre2','novoters_pre2']
from sklearn.decomposition import PCA
pca=PCA(n_components=1)
df['c_value']=pca.fit_transform(df[c_value])
df['consume_level']=pca.fit_transform(df[consume_level])
df['price_prefer']=pca.fit_transform(df[price_prefer])
df['hotel_hot']=pca.fit_transform(df[hotel_hot])
df['hotel_hot_pre']=pca.fit_transform(df[hotel_hot_pre])
df['hotel_hot_pre2']=pca.fit_transform(df[hotel_hot_pre2])
df.drop(c_value,axis=1,inplace=True)
df.drop(consume_level,axis=1,inplace=True)
df.drop(price_prefer,axis=1,inplace=True)
df.drop(hotel_hot,axis=1,inplace=True)
df.drop(hotel_hot_pre,axis=1,inplace=True)
df.drop(hotel_hot_pre2,axis=1,inplace=True)
df.drop('historyvisit_totalordernum',axis=1,inplace=True) ###把重复的一列删了
print('PCA降维后数据维度是:{}'.format(df.shape))
'''
PCA降维后数据维度是:(689870, 42)
'''
5.3 特征预处理
- 标准化处理
数据标准化的目的是:处理不同规模和量纲的数据,使其缩放到相同的数据区间和范围
# 数据标准化
from sklearn.preprocessing import StandardScaler
y = df['label']
x = df.drop('label',axis=1)
scaler = StandardScaler()
X= scaler.fit_transform(x)
6 建模预测
from sklearn.model_selection import train_test_split, GridSearchCV
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size= 0.2,random_state=420)
6.1 逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn import metrics
# 实例化一个LR模型
lr = LogisticRegression()
# 训练模型
lr.fit(X_train,y_train)
# 预测1类的概率
y_prob = lr.predict_proba(X_test)[:,1]
# 模型对测试集的预测结果
y_pred = lr.predict(X_test)
# 获取真阳率、伪阳率、阈值
fpr_lr,tpr_lr,threshold_lr = metrics.roc_curve(y_test,y_prob)
# AUC得分
auc_lr = metrics.auc(fpr_lr,tpr_lr)
# 模型准确率
score_lr = metrics.accuracy_score(y_test,y_pred)
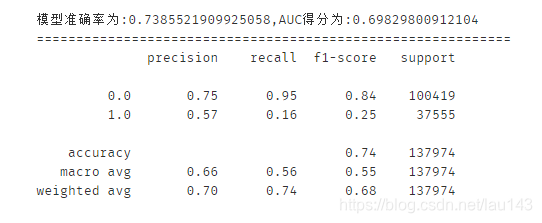
print('模型准确率为:{0},AUC得分为:{1}'.format(score_lr,auc_lr))
print('============================================================')
print(classification_report(y_test,y_pred,labels=None,target_names=None,sample_weight=None, digits=2))
6.2 朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB() # 实例化一个LR模型
gnb.fit(X_train,y_train) # 训练模型
y_prob = gnb.predict_proba(X_test)[:,1] # 预测1类的概率
y_pred = gnb.predict(X_test) # 模型对测试集的预测结果
fpr_gnb,tpr_gnb,threshold_gnb = metrics.roc_curve(y_test,y_prob) # 获取真阳率、伪阳率、阈值
auc_gnb = metrics.auc(fpr_gnb,tpr_gnb) # AUC得分
score_gnb = metrics.accuracy_score(y_test,y_pred) # 模型准确率
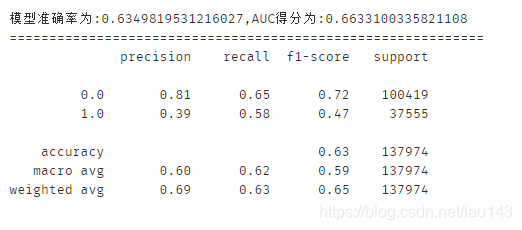
print('模型准确率为:{0},AUC得分为:{1}'.format(score_gnb,auc_gnb))
print('============================================================')
print(classification_report(y_test, y_pred, labels=None, target_names=None, sample_weight=None, digits=2))
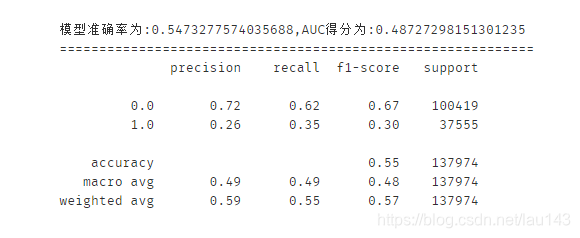
6.3 支持向量机
from sklearn.svm import SVC
svc = SVC(kernel='rbf',C=1,max_iter=100).fit(X_train,y_train)
y_prob = svc.decision_function(X_test) # 决策边界距离
y_pred = svc.predict(X_test) # 模型对测试集的预测结果
fpr_svc,tpr_svc,threshold_svc = metrics.roc_curve(y_test,y_prob) # 获取真阳率、伪阳率、阈值
auc_svc = metrics.auc(fpr_svc,tpr_svc) # 模型准确率
score_svc = metrics.accuracy_score(y_test,y_pred)
print('模型准确率为:{0},AUC得分为:{1}'.format(score_svc,auc_svc))
print('============================================================')
print(classification_report(y_test, y_pred, labels=None, target_names=None, sample_weight=None, digits=2))
6.4 决策树
from sklearn import tree
dtc = tree.DecisionTreeClassifier() # 建立决策树模型
dtc.fit(X_train,y_train) # 训练模型
y_prob = dtc.predict_proba(X_test)[:,1] # 预测1类的概率
y_pred = dtc.predict(X_test) # 模型对测试集的预测结果
fpr_dtc,tpr_dtc,threshod_dtc= metrics.roc_curve(y_test,y_prob) # 获取真阳率、伪阳率、阈值
score_dtc = metrics.accuracy_score(y_test,y_pred)
auc_dtc = metrics.auc(fpr_dtc,tpr_dtc)
print('模型准确率为:{0},AUC得分为:{1}'.format(score_dtc,auc_dtc))
print('============================================================')
print(classification_report(y_test,y_pred,labels=None,target_names=None,sample_weight=None, digits=2))
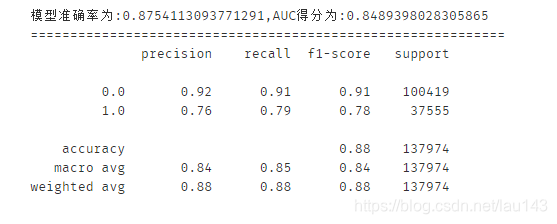
6.5 随机森林
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier() # 建立随机森林分类器
rfc.fit(X_train,y_train) # 训练随机森林模型
y_prob = rfc.predict_proba(X_test)[:,1] # 预测1类的概率
y_pred=rfc.predict(X_test) # 模型对测试集的预测结果
fpr_rfc,tpr_rfc,threshold_rfc = metrics.roc_curve(y_test,y_prob) # 获取真阳率、伪阳率、阈值
auc_rfc = metrics.auc(fpr_rfc,tpr_rfc) # AUC得分
score_rfc = metrics.accuracy_score(y_test,y_pred) # 模型准确率
print('模型准确率为:{0},AUC得分为:{1}'.format(score_rfc,auc_rfc))
print('============================================================')
print(classification_report(y_test,y_pred,labels=None,target_names=None,sample_weight=None, digits=2))
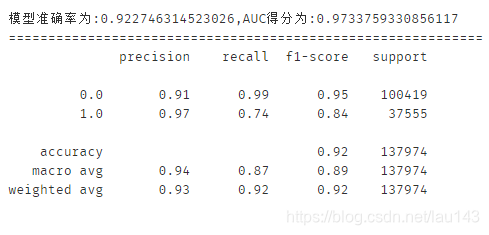
6.6 XGBoost
import xgboost as xgb
# 读入训练数据集和测试集
dtrain=xgb.DMatrix(X_train,y_train)
dtest=xgb.DMatrix(X_test)
# 设置xgboost建模参数
params={'booster':'gbtree','objective': 'binary:logistic','eval_metric': 'auc',
'max_depth':8,'gamma':0,'lambda':2,'subsample':0.7,'colsample_bytree':0.8,
'min_child_weight':3,'eta': 0.2,'nthread':8,'silent':1}
# 训练模型
watchlist = [(dtrain,'train')]
bst=xgb.train(params,dtrain,num_boost_round=500,evals=watchlist)
# 输入预测为正类的概率值
y_prob=bst.predict(dtest)
# 设置阈值为0.5,得到测试集的预测结果
y_pred = (y_prob >= 0.5)*1
# 获取真阳率、伪阳率、阈值
fpr_xgb,tpr_xgb,threshold_xgb = metrics.roc_curve(y_test,y_prob)
auc_xgb = metrics.auc(fpr_xgb,tpr_xgb) # AUC得分
score_xgb = metrics.accuracy_score(y_test,y_pred) # 模型准确率
print('模型准确率为:{0},AUC得分为:{1}'.format(score_xgb,auc_xgb))
print('============================================================')
print(classification_report(y_test,y_pred,labels=None,target_names=None,sample_weight=None, digits=2))
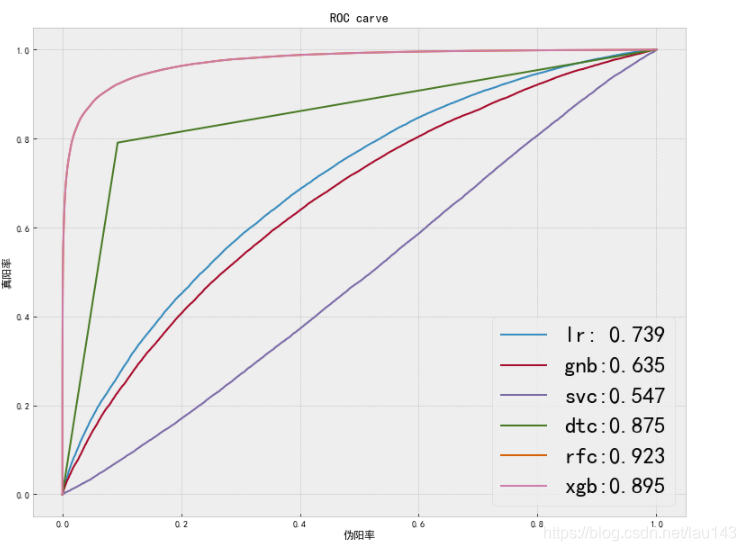
6.7 模型比较
plt.style.use('bmh')
plt.figure(figsize=(13,10))
plt.plot(fpr_lr,tpr_lr,label='lr: {0:.3f}'.format(score_lr)) # 逻辑回归
plt.plot(fpr_gnb,tpr_gnb,label='gnb:{0:.3f}'.format(score_gnb)) # 朴素贝叶斯
plt.plot(fpr_svc,tpr_svc,label='svc:{0:.3f}'.format(score_svc)) # 支持向量机
plt.plot(fpr_dtc,tpr_dtc,label='dtc:{0:.3f}'.format(score_dtc)) # 决策树
plt.plot(fpr_rfc,tpr_rfc,label='rfc:{0:.3f}'.format(score_rfc)) # 随机森林
plt.plot(fpr_rfc,tpr_rfc,label='xgb:{0:.3f}'.format(score_xgb)) # XGBoost
plt.legend(loc='lower right',prop={'size':25})
plt.xlabel('伪阳率')
plt.ylabel('真阳率')
plt.title('ROC carve')
plt.savefig('./模型比较图.jpg',dpi=400, bbox_inches='tight')
plt.show()
7 K-means用户画像
7.1 RFM分析
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,其有三个指标:最近一次消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary)。本数据集中三个指标并不都是直接给出,需要进行分析提取。
Recency:选用lasthtlordergap(距离上次下单时长)此字段。
Frequency:选用ordernum_oneyear(用户年订单数)此字段。
Monetary:选用avgprice(平均价格),consuming_capacity(消费能力指数)这两个字段作为消费金额指标,合并为consume_level。
#字段重名
rfm = df[['lasthtlordergap','ordernum_oneyear','consume_level']]
rfm.rename(columns={'lasthtlordergap':'recency','ordernum_oneyear':'frequency','consume_level':'monetary'},inplace=True)
#利用MinMaxScaler进行归一化处理
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(rfm)
rfm = pd.DataFrame(scaler.transform(rfm),columns=['recency','frequency','monetary'])
#分箱
rfm['R']=pd.qcut(rfm["recency"], 2)
rfm['F']=pd.qcut(rfm["frequency"], 2)
rfm['M']=pd.qcut(rfm["monetary"], 2)
# 根据分箱情况进行编码,二分类可以直接用标签编码方式
from sklearn.preprocessing import LabelEncoder
rfm['R']=LabelEncoder().fit(rfm['R']).transform(rfm['R'])
rfm['F']=LabelEncoder().fit(rfm['F']).transform(rfm['F'])
rfm['M']=LabelEncoder().fit(rfm['M']).transform(rfm['M'])
#定义RFM模型,需要特别注意的是,R值代表距离上次消费时间间隔,值越小客户价值越高,与F和M值正好相反。
def get_label(r,f,m):
if (r==0)&(f==1)&(m==1):
return '高价值客户'
if (r==1)&(f==1)&(m==1):
return '重点保持客户'
if((r==0)&(f==0)&(m==1)):
return '重点发展客户'
if (r==1)&(f==0)&(m==1):
return '重点挽留客户'
if (r==0)&(f==1)&(m==0):
return '一般价值客户'
if (r==1)&(f==1)&(m==0):
return '一般保持客户'
if (r==0)&(f==0)&(m==0):
return '一般发展客户'
if (r==1)&(f==0)&(m==0):
return '潜在客户'
def RFM_convert(df):
df['Label of Customer']=df.apply(lambda x:get_label(x['R'],x['F'],x['M']),axis=1)
df['R']=np.where(df['R']==0,'高','低')
df['F']=np.where(df['F']==1,'高','低')
df['M']=np.where(df['M']==1,'高','低')
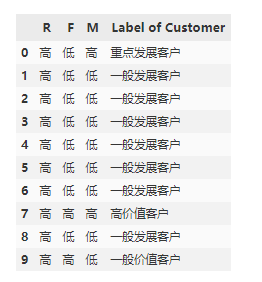
return df[['R','F','M','Label of Customer']]
rfm1=RFM_convert(rfm)
rfm1.head(10)
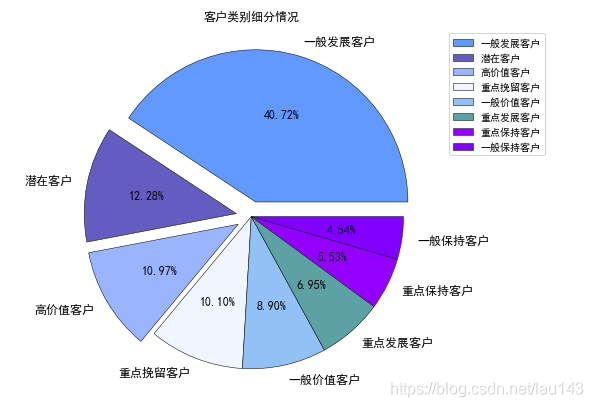
value_counts=rfm1["Label of Customer"].value_counts().values
labels=rfm1["Label of Customer"].value_counts().index
explode=[0.1,0.1,0.1,0,0,0,0,0]
color=['deepskyblue','steelblue','lightskyblue','aliceblue','skyblue','cadetblue','cornflowerblue','dodgerblue']
plt.figure(figsize=(10, 7))
plt.pie(x=value_counts,labels=labels,autopct='%.2f%%',explode=explode,colors=color,wedgeprops={'linewidth':0.5,'edgecolor':'black'},
textprops={'fontsize':12,'color':'black'})
plt.legend(labels,bbox_to_anchor=(1, 1), loc='best', borderaxespad=0.7)
plt.title('客户类别细分情况')
plt.show()
7.2 构建用户画像
重要性特征
由于携程数据集的特征较多,我们可以通过XGBoost的plot_importance来辨别哪些是重要性特征,其原理是F score方差分析法。
# 导入plot_importance
from xgboost import plot_importance
# 画柱状图
fig, ax = plt.subplots(figsize=(15, 15))
plot_importance(bst, height=0.5, ax=ax, max_num_features=40, color='chocolate')
plt.savefig('./重要性特征图.jpg', dpi=400, bbox_inches='tight')
plt.show()
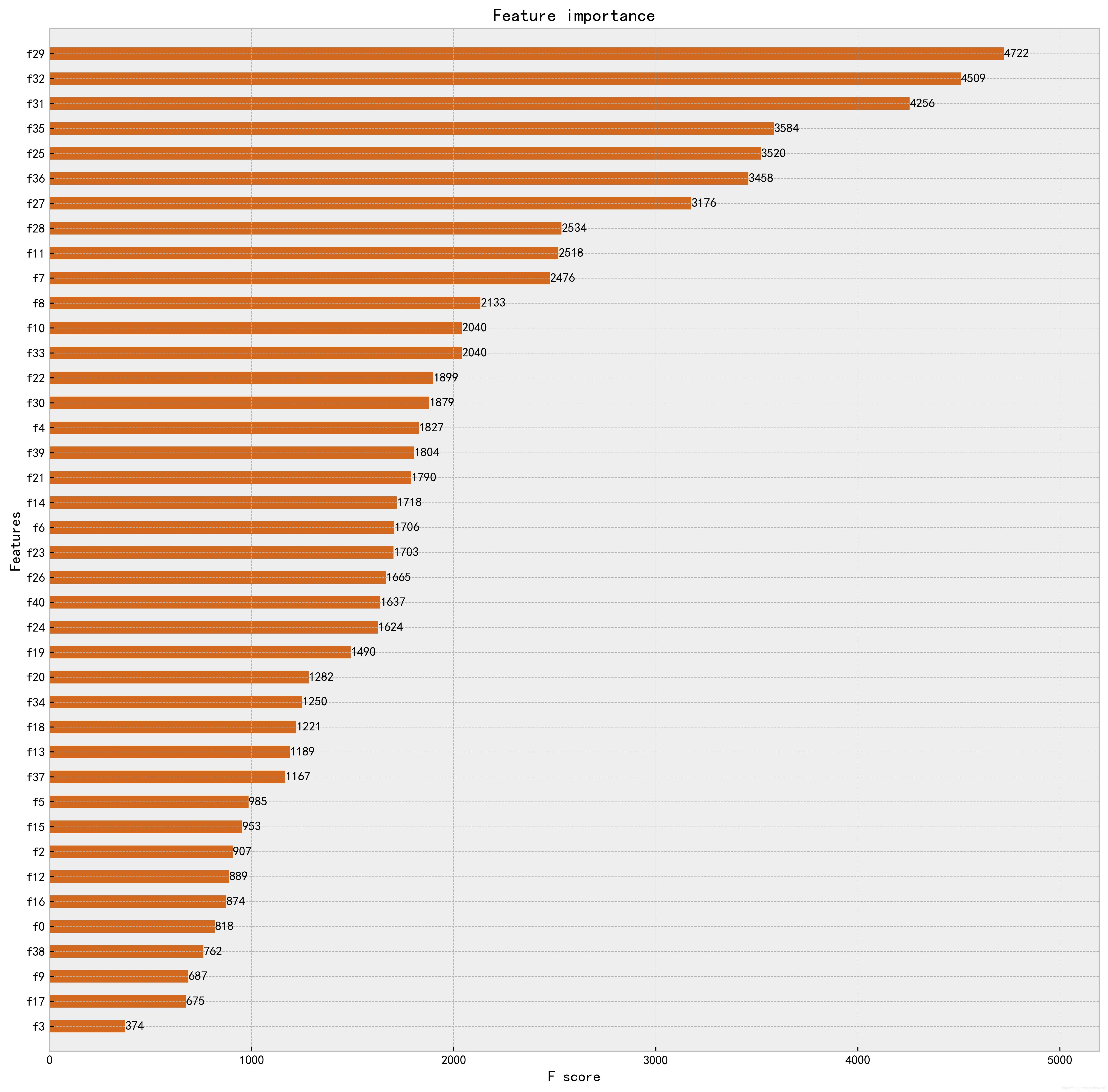
从上图可以看到,较为重要的特征为:24小时内是否访问订单填写页(24小时内是否访问订单填写页)、近3个月用户历史日均访问酒店数(historyvisit_avghotelnum)、当前酒店转换率(hotelcr)、当前酒店历史订单取消率(ordercanceledprecent)、星级偏好(starprefer)、用户历史取消率(cancelrate)、 7天内访问酒店详情页数(historyvisit_visit_detailpagenum)、价格敏感指数(price_sensitive)、当前酒店访客量(hoteluv)、浏览最多的酒店商务属性(businessrate_pre)。
聚类分析
K-Means算法是一种基于划分的无监督聚类算法,它以 k 为参数,把 n 个数据对象分成 k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。
# 选取刻画用户的重要指标
user_feature = ['decisionhabit_user','ordercanncelednum','ordercanceledprecent',
'consume_level','starprefer','lasthtlordergap','lastpvgap',
'h','sid','c_value','landhalfhours','price_sensitive',
'price_prefer','day_advanced','historyvisit_avghotelnum',
'ordernum_oneyear']
user_attributes = df[user_feature]
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(user_attributes)
user_attributes = scaler.transform(user_attributes)
#K-Means聚类
from sklearn.cluster import KMeans
Kmeans = KMeans(n_clusters=3,random_state=13) # 建立KMean模型
Kmeans.fit(user_attributes) # 训练模型
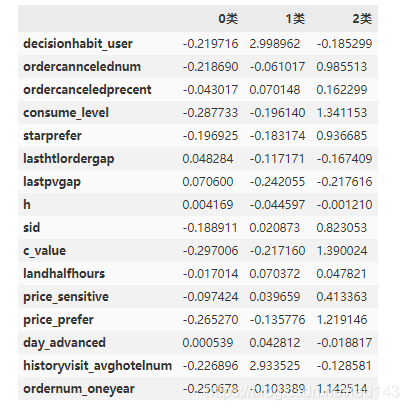
k_char = Kmeans.cluster_centers_ # 得到每个分类的质心
personas = pd.DataFrame(k_char.T,index=user_feature,columns=['0类','1类','2类']) # 用户画像表
personas
#绘制热力图
fig,ax = plt.subplots(figsize=(5, 10))
sns.heatmap(personas, xticklabels=True,
yticklabels=True, square=False,
linewidths=.5, annot=True, cmap="YlGnBu")
plt.tick_params(axis='both',labelsize=14)
plt.show()
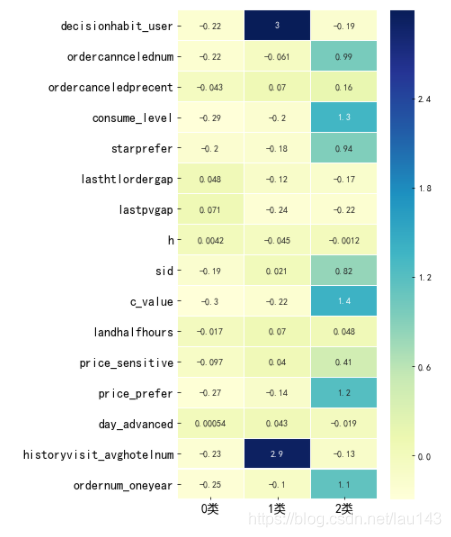
其中,2类用户的lasthtlordergap(代表RFM模型中的Recency)为0.048非常小(R越小代表客户价值越高),ordernum_oneyear(代表RFM模型中的Frequency)为1.1比较高,consume_level(代表RFM模型中的Monetary)为1.3也几乎是最高的。很明显,2类客户为我们的“高价值客户”;而0类中几乎都是白格子,无论是客户价值还是消费水平值都是最低的,很明显,这一类我们将其归为“低价值客户”;剩下的1类我们将其称为“中等群体”
plt.figure(figsize=(9,9))
class_k = list(Kmeans.labels_) # 每个类别的用户个数
percent = [class_k.count(1)/len(user_attributes),
class_k.count(0)/len(user_attributes),
class_k.count(2)/len(user_attributes)] # 每个类别用户个数占比
fig, ax = plt.subplots(figsize=(10, 10))
colors = ['chocolate', 'sandybrown', 'peachpuff']
types = ['中等群体', '低价值用户', '高价值用户']
ax.pie(percent, radius=1, autopct='%.2f%%', pctdistance=0.75,
colors=colors, labels=types)
ax.pie([1], radius=0.6, colors='w')
plt.savefig('./用户画像.jpg', dpi=400, bbox_inches='tight')
plt.show()
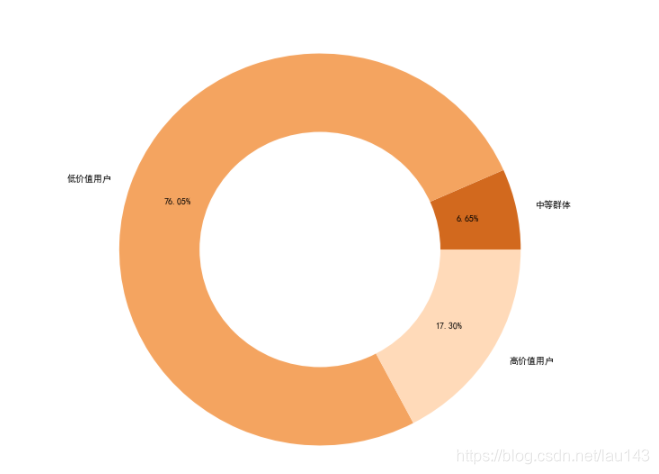
7.3 用户画像分析
从三类客户的占比图得知,中等价值用户占所有用户人数的6.65%,可结合该群体流失情况分析流失客户因素,进行该群体市场的开拓。
低价值用户是潜在客户群体,占比最高,占总用户人数的76.65%,可对该部分用户实施一些营销策略,进而刺激消费。
高价值用户,能给我们带来较优的收益,可对这类群体实施个性化营销策略。

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









