







Abstract
自动驾驶中的场景仿真因其在生成定制数据方面的巨大潜力而备受关注。然而,现有的可编辑场景仿真方法在用户交互效率、多摄像头逼真渲染和外部数字资产集成方面存在局限性。为了应对这些挑战,本文介绍了ChatSim,这是第一个通过自然语言命令和外部数字资产实现可编辑逼真3D驾驶场景仿真的系统。为了实现高命令灵活性的编辑,ChatSim利用了一个大语言模型(LLM)代理协作框架。为了生成逼真的结果,ChatSim采用了一种新颖的多摄像头神经辐射场方法。此外,为了释放高质量数字资产的潜力,ChatSim采用了一种新颖的多摄像头光照估计方法,以实现场景一致的资产渲染。我们在Waymo Open Dataset上的实验表明,ChatSim可以处理复杂的语言命令并生成相应的逼真场景视频。代码地址:
https://github.com/yifanlu0227/ChatSim
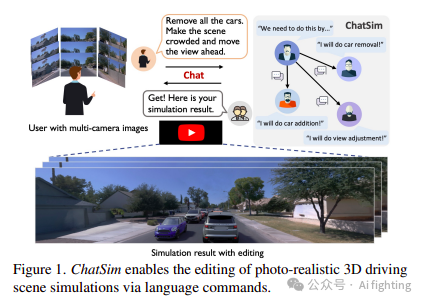
Introduction
为了有效地模拟定制的驾驶场景,我们确定了三个关键属性是基本的。首先,仿真应该能够遵循复杂或抽象的需求,从而促进生产。其次,仿真应该生成逼真、视图一致的结果,这样可以最接近车辆在真实世界场景中的观察。第三,它应该允许集成外部数字资产,并保持逼真的纹理和材料,同时适应照明条件。这种能力将通过引入各种外部数字资产来解锁数据扩展的潜力,满足定制需求。
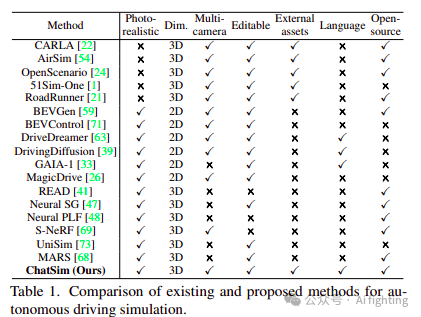
虽然已经提出了大量重要的工作用于场景仿真,但它们未能满足所有三个要求。传统的图形引擎,如CARLA和UE,提供了可编辑的虚拟环境和外部数字资产,但数据真实性受限于资产建模和渲染质量。图像生成方法,如BEVControl、DriveDreamer、MagicDrive,可以基于各种控制信号生成逼真的场景图像,包括鸟瞰视图地图、边界框和相机姿态。然而,由于缺乏3D空间建模,它们难以保持视图一致性,并且在导入外部数字资产方面面临挑战。基于渲染的方法已被提出以获得逼真且视图一致的场景仿真。著名的例子如UniSim和MARS配备了一套场景编辑工具。然而,这些系统在每一步编辑中都需要大量的用户参与,通过代码实现每个细节步骤,这在执行编辑时效率低下。此外,虽然它们在处理观测到的场景中的车辆时效果显著,但它们不支持外部数字资产,限制了数据扩展和定制的机会。
协作LLM代理进行编辑
ChatSim系统分析具体的用户命令并返回符合定制需求的视频。由于用户命令可能是抽象和复杂的,要求系统具有灵活的任务处理能力。直接应用单个LLM代理难以处理多步骤推理和交叉引用。为了解决这个问题,我们设计了一系列协作LLM代理,每个代理负责编辑任务的独特方面。
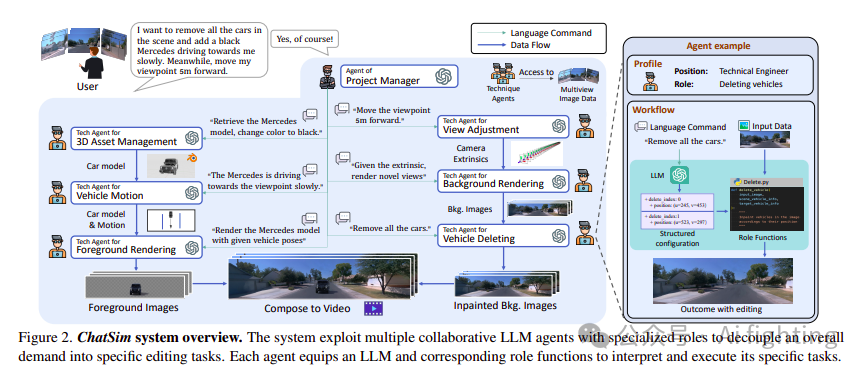
1.具体代理
C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









