







Abstract
近年来,扩散模型在合成驾驶场景中的LiDAR点云或摄像头图像数据方面取得了进展。尽管这些模型在单一模态数据的边际分布建模方面取得成功,但对不同模态之间互相依赖关系的探索仍然不足,而这种依赖关系能够更好地描述复杂的驾驶场景。为了解决这一问题,我们提出了一个新框架,称为X-DRIVE,通过双分支潜在扩散模型架构来建模点云和多视角图像的联合分布。考虑到两种模态的几何空间差异,X-DRIVE在合成每种模态时都基于另一模态的对应局部区域,以确保更好的对齐和真实感。为了解决去噪过程中的空间模糊问题,我们设计了基于极线的跨模态条件模块,以自适应学习跨模态局部对应关系。此外,X-DRIVE通过多层次输入条件(包括文本、边界框、图像和点云)实现可控生成。广泛的实验结果表明,X-DRIVE能够生成高保真的点云和多视角图像,既符合输入条件又保证了可靠的跨模态一致性。
代码获取:https://github.com/yichen928/X-Drive
欢迎加入自动驾驶实战群
Introduction
自动驾驶车辆依靠多种传感器感知环境,其中LiDAR和摄像头通过捕获点云和多视角图像发挥了关键作用。这些传感器提供了关于周围环境的几何测量和语义信息,对于目标检测、运动规划、场景重建和自监督表示学习等任务具有重要价值。然而,这些进步依赖于大量对齐的多模态数据,尤其是同一场景下经过良好校准的LiDAR和多视角摄像头输入。
收集此类高质量多模态数据的成本高昂且复杂,因而难以大规模扩展。高质量传感器价格昂贵,校准过程需要大量人工操作。此外,真实驾驶数据存在严重的长尾分布问题,极端天气条件等罕见场景的采集困难。因此,提出了一个自然问题:我们是否可以使用可控的方式合成对齐的多模态数据?
得益于在其他领域的成功,生成模型提供了一种有前景的解决方案。目前的研究集中在合成点云或多视角图像,但对多模态数据的生成关注较少。将这些单模态算法简单组合会导致合成场景中严重的跨模态不匹配,造成输入矛盾,从而影响下游任务的表现。跨模态一致性是多模态数据生成的关键,但生成一致的LiDAR和摄像头数据面临以下挑战:
(1)合成的点云和多视角图像必须在局部区域上对齐,描述相同的驾驶场景。
(2)与2D像素级任务不同,点云和多视角图像具有不同的几何空间和数据格式。
(3)去噪过程中缺乏可靠的点位或像素深度,导致3D空间信息模糊。
为了解决这一问题,我们提出X-DRIVE框架用于LiDAR和摄像头数据的联合生成。该框架设计了一个双分支架构,其中两个潜在扩散模型分别致力于点云和多视角图像的合成,同时一个跨模态条件模块增强了它们之间的模态一致性。
3 初步知识
潜在扩散模型。扩散模型通过迭代地对随机高斯噪声进行T步去噪来学习逼近数据分布
![]()
。通常,扩散模型通过一个前向过程来构造扩散输入,该过程根据方差计划
![]()
逐步向数据添加高斯噪声:
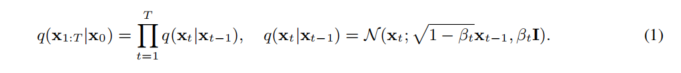
然后,反向过程通过拟合
![]()
来学习恢复原始输入:
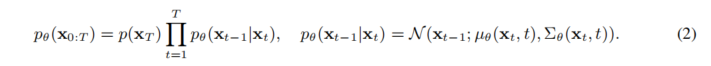
潜在扩散模型在潜在空间中而非输入空间上执行扩散过程,以处理高维数据。具体来说,它通过编码器E将输入x映射到潜在空间为
![]()
。潜在编码z可以通过解码器D重建为输入
![]()
。潜在扩散模型的前向和反向过程类似于原始扩散模型,只需在公式1和公式2中用潜在变量z替代输入变量x。
距离图像表示。与LiDAR传感器的采样过程相兼容,距离图像
![]()
是LiDAR点云的密集矩形表示形式,其中 和分别表示行数和列数,一个通道代表距离(range),另一个通道代表强度(intensity)。行反映激光束的位置,列则指示偏航角。对于具有笛卡尔坐标 (x,y,z)的每个点,可以通过以下投影将其转换为球坐标 (r,θ,ϕ):
![]()
其中 r 是距离,θ是仰角,ϕ 是方位角。距离图像通过使用因子 和对 θ和 ϕ进行量化得到。对于具有球坐标
![]()
的每个点,有
![]()
。距离 和强度 被归一化到 (0,1) 之间。
4 方法
本节中,我们提出了用于联合生成点云和多视角图像的创新框架X-DRIVE。整体架构如图2所示。我们在第4.1节扩展了基础扩散模型,以模拟多模态数据的联合分布。第4.2节介绍了我们的双分支扩散模型框架。为实现跨模态一致性,我们在第4.3节提出了基于极线的跨模态条件模块。第4.4节则展示了如何以零样本方式实现跨模态条件生成。
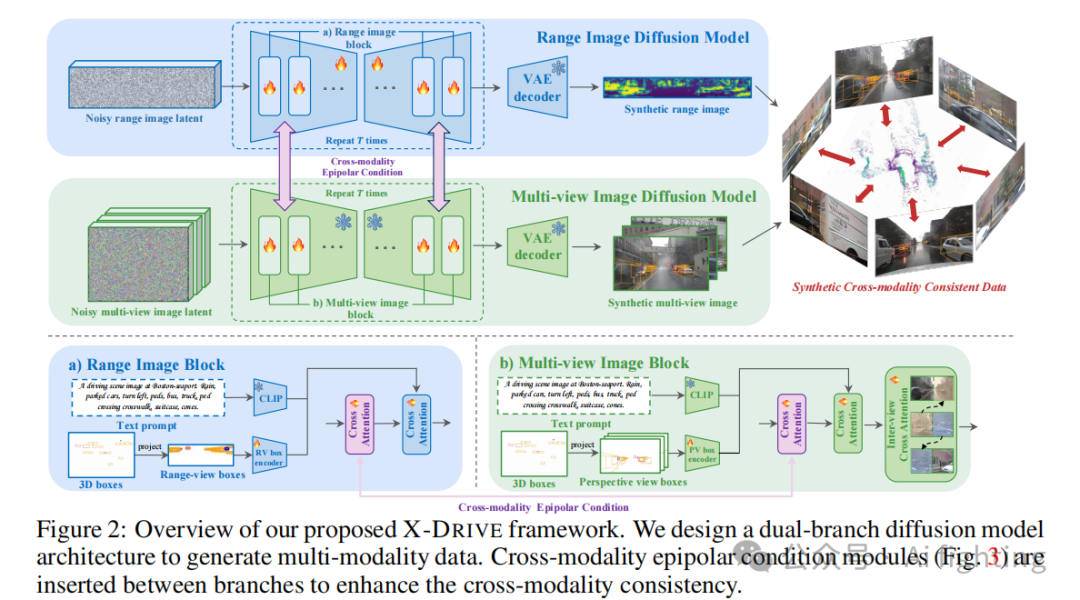
4.1 联合多模态生成
在第3节的单模态扩散模型基础上,我们为X-DRIVE的多模态数据生成提供了一个公式。其目的是逼近描述特定驾驶场景的成对数据 (r0,C0)的联合分布,其中 是点云的距离图表示,
![]()
表示从不同视角摄像头获得的多视角图像。
考虑到这两种模态的相似矩形潜在格式,我们为距离图和多视角图像设置了共享的噪声调度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









