







Abstract
从图像-文本对中,大规模视觉-语言模型(VLMs)学习将图像区域与词语隐式关联,这在视觉问答等任务中表现出色。然而,利用这种学习关联进行开放词汇语义分割仍然是一个挑战。本文提出了一种简单但极其有效的无需训练的技术,即即插即用的开放词汇语义分割(PnP-OVSS)。PnP-OVSS利用VLM进行直接的文本到图像交叉注意和图像-文本匹配损失。为了在过度分割和欠分割之间取得平衡,我们引入了显著性丢弃,通过迭代地丢弃模型最关注的图像块,我们能够更好地解决分割掩码的整体范围。PnP-OVSS不需要任何神经网络训练,也无需任何分割注释进行超参数调整,包括验证集。PnP-OVSS在多个基准测试中表现出了显著的改进(在Pascal VOC上+29.4%的mIoU,Pascal Context上+13.2%的mIoU,MS COCO上+14.0%的mIoU,COCO Stuff上+2.4%的mIoU),甚至超过了大多数在预训练VLM基础上进行额外网络训练的基线。
代码地址:
https://github.com/letitiabanana/PnP-OVSS


Introduction
大规模视觉-语言模型(VLMs)在图像-文本对上的预训练,在多模态任务中取得了前所未有的性能,例如描述任意图像和回答关于它们的自由形式、开放性问题(无论是否进行微调)。这些任务显然涉及某种对象定位能力。例如,要回答“桌子上有什么物体?”这个问题,模型首先必须定位图像中的桌子并识别其上的物体。因此,可以合理地推测,VLM网络从图像-文本预训练中学会了开放词汇定位能力。然而,从VLM中提取这种定位能力仍然是一个开放的问题。
大多数现有的从VLM进行开放词汇语义分割(OVSS)的方法通常分别获取视觉和文本输入的单个向量编码。然而,将每个标记池化为单个向量可能会丢失关于对象和词语详细位置的信息。我们研究了预训练的交叉注意层在OVSS中的使用,这些层保留了文本和图像块之间更细粒度的对应关系。

Method
PnP-OVSS 包含四个主要步骤:
-
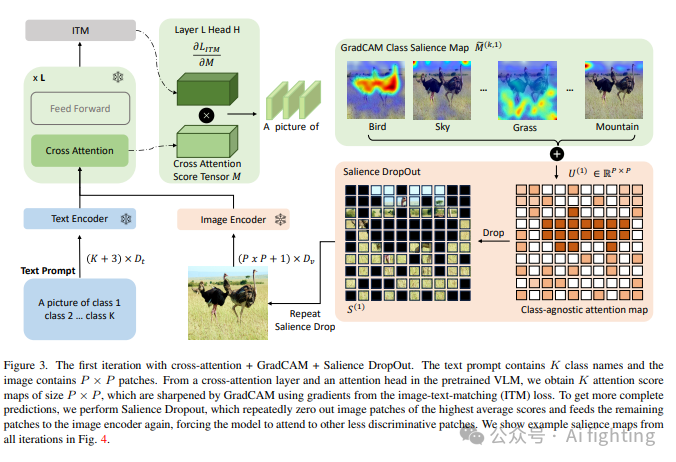
提取交叉注意力显著性图:将图像和文本提示输入预训练的视觉-语言模型(VLM),提取交叉注意力图。文本提示包括数据集中所有类别的名称,图像被划分为P×P块,分别通过特定模态的编码器,然后通过交叉注意力融合模块,生成大小为K×P×P的注意力张量。
-
GradCAM进行显著性图清晰化:通过使用类似GradCAM的图像文本匹配(ITM)梯度对显著性图进行加权,提高其清晰度。具体来说,计算ITM损失的梯度,并将其与注意力图进行逐元素乘积运算。
-
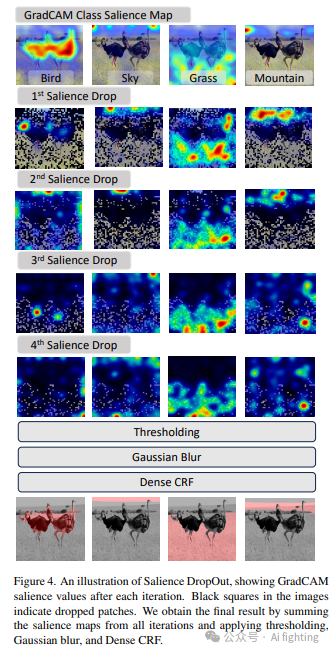
显著性DropOut:通过迭代方式完成显著性图。首先,将所有类的显著性图相加得到类无关的显著性图,然后将其中50%显著性最高的图像块置零。在剩余图像上再次计算GradCAM显著性图,并重复上述过程四轮,最终输出每个类的聚合显著性图。
-
Dense CRF进行细粒度调整:对生成的连续值显著性图应用阈值操作,获得二值分割掩码。为了避免二值化带来的分割边缘不精确问题,通过高斯模糊平滑二值掩码,并使用Dense CRF进行细粒度调整。
1. 使用GradCAM锐化图
现成的注意力图往往也覆盖许多与类名无关的块(见图2(b))。之前的工作,进一步锐化注意力图,并使用GradCAM的变体将它们聚焦在类区分区域,该方法最初为卷积网络提出,但也适用于注意力图。值得注意的是,使用该技术用于其他目的,而非语义分割。
GradCAM方法需要一个梯度。这里我们利用图像-文本匹配(ITM)损失,该损失训练VLM来分类图像-文本对是否匹配。计算ITM损失需要一个标签。我们使用“匹配”(相对于“不匹配”)作为标签,并计算损失相对于注意力分数的梯度。这相当于问:哪些注意力分数对图像-文本对匹配的决策贡献最大?形式上,我们将类k的P×P注意力图表示为M(k)和ITM损失表示为LITM。GradCAM类显著性图计算如下:
![]()
其中⊗表示分量乘法,max(·)也应用于分量。
2. 显著性DropOut
如图2©所示,通过GradCAM风格的交叉注意力重新加权生成的分割通常集中在给定类别的最具区分性的区域。然而,较不具区分性的区域对于掩码的完整性仍然重要。为了迫使VLM关注这些区域,我们提出了一种称为显著性DropOut的迭代技术。
由于我们的任务是零样本和开放词汇,我们没有关于图像中存在类别的先验知识。因此,我们对所有类k的显著性图Mf(k)求和,得到t次显著性DropOut迭代的无类别显著性图U(t),
![]()
其中Mf(k,t)是第t次迭代后类k的GradCAM显著性图。
接下来,我们将U(t)中值最高的50%图像块置零。
在剩余图像上,我们计算GradCAM显著性图Mf(k,t+1)及其和U(t+1)。
任何先前置零的图像块在以后的迭代中始终会收到零显著性。
形式上,第t次DropOut迭代后的剩余图像块集S(t) ⊆ {1, …, P}²定义如下:
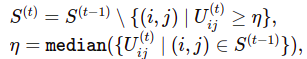
其中U(t)i,j表示第t次迭代中第i行第j列的图像块的聚合显著性值。此外,第一次DropOut迭代的输入S0 = {1, …, P}²是所有图像块的集合。
我们在四轮DropOut时停止,因为此时几乎所有(93.75%)块都被删除。每个类k的最终输出是四次DropOut迭代中所有显著性图的总和,
![]()
3. 高斯模糊和Dense CRF
显著性DropOut过程生成k个连续值的显著性图,每个对象类一个。为了过滤显著性值中的小随机噪声,我们随后对显著性值应用简单的阈值操作,并获得二值分割掩码。然而,硬阈值创建的分割具有锐利边缘,通常不与对象边界一致。一种常见的零样本分割策略是应用Dense Conditional Random Field(CRF)[29],该方法通过在颜色相似的附近像素之间实施一致性来对估计的掩码进行细粒度调整。
然而,我们发现二值掩码中的硬0/1标签不适合作为Dense CRF的像素一元势。因此,我们使用具有预设方差σ的高斯核平滑它们,这导致了一种更好的初始化一元项,并解释了沿图像块边界的精确分割边界的不确定性。
4. 超参数调整
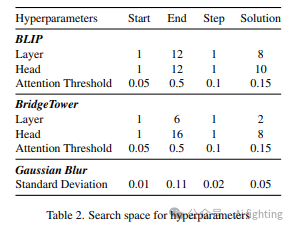
PnP-OVSS中三个超参数对结果有最强的影响,即交叉注意力层L、注意力头H和二值阈值T。传统上,调整这些超参数需要一个具有像素级标签的验证集。然而,由于我们的目标是执行零样本开放词汇语义分割,这种要求可能会限制该技术的适用性。相反,我们提出了一种弱监督奖励函数进行超参数调整,只需要一组图像和每个图像中出现的类名称。
图像I的奖励计算如下。我们从图像中存在的一组类开始,表示为K(I)。对于每个类k ∈ K(I),我们获得一个分割掩码M(k)(可以是GradCAM掩码、显著性DropOut掩码或Dense CRF掩码)。接下来,我们将掩码应用于图像I,并将提取的区域M(k) ⊗ I输入到一个预训练的神经网络f中,该网络接收图像和文本类名称作为输入并生成相似度分数。我们计算掩码图像M(k) ⊗ I属于真实类k的归一化概率,并与完全黑色图像0进行对比。
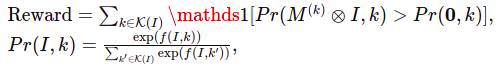
其中1(·)是指示函数。
直观地说,如果并且只有在估计的类k掩码图像特征与类名称k的相似度高于黑色图像时,奖励为1(可以解释为类k的先验概率)。
我们将所有验证图像的奖励求和作为总奖励。最佳超参数,包括交叉注意力层、注意力头、阈值T和高斯模糊核的方差,通过简单的随机搜索确定。
Experiments
1.主要的结果
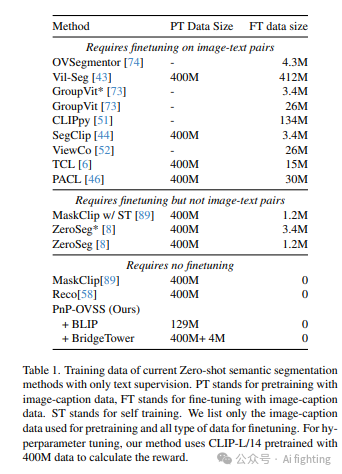
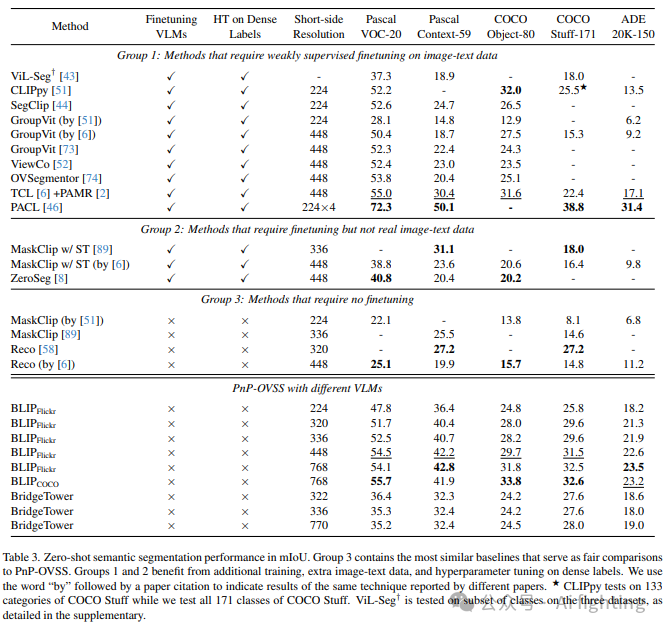
表3中展示了主要结果,PnP-OVSS展现了出色的性能。与MaskClip 和Reco 这两种无需额外训练和超参数调优的地面真值方法相比,在相同分辨率下,我们在Pascal VOC上获得了+29.4%的mIoU,在Pascal Context上获得了+13.2%的mIoU,在COCO Object上获得了+14.0%的mIoU,并在ADE-20K上获得了+11.4%的mIoU。在表4中报告了与监督方法的比较。PnP-OVSS + BLIPFlickr在Pascal VOC上超过了7种方法中的5种,并且在Pascal Context和COCO stuff上超过了除MaskCLIP+外的所有基准。由于这些基准受益于密集的监督,这些结果进一步证明了PnP-OVSS的优势。
2.消融研究
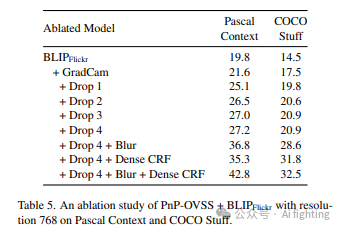
我们在BLIPFlickr上逐步消融PnP-OVSS的各个组件,并在表5中报告结果。每个组件,包括GradCAM、所有的Salience DropOut迭代、高斯模糊和Dense CRF,都对最终性能有正面贡献。特别是Salience DropOut的第一次迭代影响最大(+3.5/2.3),而第二次迭代(+1.4/0.8)比后续迭代更为重要。有趣的是,高斯模糊本身就能取得不错的表现(+9.6/7.7),而Dense CRF只有与模糊结合时效果较好。仅使用Dense CRF比仅使用高斯模糊在Pascal Context上低1.5%的mIoU。这可能是因为硬0/1标签的阈值化结果不是CRF可以有效利用的信息丰富的单势。
3.超参数敏感性
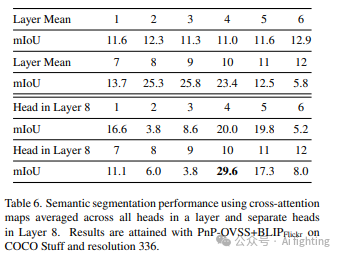
超参数的选择通常对分割性能有显著影响。这里我们定量地研究了交叉注意层和注意头的选择可能如何改变COCO Stuff上的分割mIoU。表6显示了在每一层所有头的平均交叉注意图和不同注意头获得的结果。
总结:
本文的主要贡献如下:
-
PnP-OVSS框架:提出了一种无需训练的框架,使用CLIP奖励函数和随机搜索来调整超参数,实现高性能的语义分割,无需像素级注释。
-
技术贡献:结合了文本到图像的交叉注意、GradCAM以及显著性丢弃技术,以迭代方式从预训练的VLM中提取任意类别的准确分割。
-
性能与优势:PnP-OVSS在多个数据集上显著提高了分割性能,击败了无需训练的基线,并在某些情况下超过了需要广泛微调的最新技术。此外,它简单易用,无需额外微调,为利用大型VLM进行开放词汇分割任务提供了新方向。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









