







简单介绍一下PAC今年的数据比赛:用结构数据预测年龄。组织者提供被试的结构数据 (n=3000+),参与者首先根据训练集(n=2000+)建立模型,随后预测测试集年龄(n=600+)。具体详见 photon-ai.com/pac2019
背景
大脑会随年龄的增长发生变化。这些变化与认知能力下降、神经退行性疾病和痴呆症有关。虽然大脑老化是普遍存在的,但大脑老化的速度明显不同;有些人在成年中后期出现认知能力下降,而有些人在100岁时认知仍然正常。大脑衰老的过程包括大脑的形态和功能变化。使用神经影像学进行评估,让测量大脑衰老不一致性成为可能。目前的研究已经开始关注开发脑老化的神经成像生物标志物,也就是所谓的“大脑年龄(brain-age)”。这类研究的思路是,如果基于神经影像学数据的统计模型可以准确预测健康人的实际年龄(chronical age),那么可以基于该模型计算(预测)新个体大脑年龄(apparent age)。如果某人的大脑年龄大于他们的实际年龄,那么这就反映了大脑的健康状况较差, 这与精神疾病和神经疾病有关,并有更高患痴呆症的风险,寿命更短。有更多体育锻炼,受过更多教育,冥想或演奏乐器的人表现出更年轻的大脑--大脑年龄低于实际年龄。大脑年龄能提供敏感的大脑健康测量,有很多实际的运用。比如,筛查具有较差认知老化风险的人群,以及从机制上提供对不同疾病后果的解释。
数据
训练集n=2640
测试集n=660
1)原始nifti数据
2)预处理的数据 (预处理和Cole, et al., Neuroimage 2017相同)
FYI
Cole, et al., Neuroimage 2017
https://spiral.imperial.ac.uk:8443/bitstream/10044/1/50281/2/Cole%202017%20NeuroImage_accepted_version.pdf
模型评估
Objective1-最佳模型:最小平均绝对误差的模型(MAE)
Objective2-最小偏差:MAE最小,predicted age difference和chronical age Spearman相关<.10
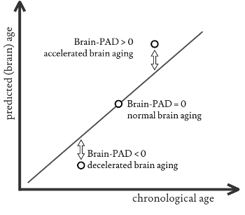
Objective 2 是这个领域中很常见的bias。如图,对于chronical age高的人,预测出来的大脑年龄会偏大,chronical age低的人,预测出来的大脑年龄偏小。有文章专门指出怎么降低这个bias, 比如 Liang et al., HBM 2019 (排名前十来自University of Pennsylvania的team很可能是他们)。第一名只是做了简单的回归,当然这可能得益于他们复杂的模型(也就是说模型本身的bias已经很小了)。
奖励
一篇open access杂志Frontiers in Psychiatry的版面费
对于不是直接奖钱的竞赛,就很难吸引到其他领域的人参与。一个吸引人的地方是颁奖会在OHBM上进行,影响力会很大。将来的导师从OHBM回来都说,可以试试大脑年龄。
结果
恭喜来自國立陽明大學,北京天坛医院,北航的team上榜
Objective 1
TEAM | MAE | R | |
1 | BrainAgeDifference | 2.9043 | -0.3914 |
2 | BrainAGE | 3.0857 | -0.3423 |
3 | ARAMIS | 3.3284 | -0.2103 |
4 | Quantum Pika | 3.3315 | -0.3939 |
5 | sablab | 3.3716 | -0.2469 |
6 | DRAGN | 3.5464 | -0.3189 |
7 | Procrastination | 3.6026 | -0.3828 |
8 | Milan_buaa | 3.6358 | -0.3294 |
9 | inteneural | 3.6787 | -0.3861 |
10 | Mind the Gap | 3.7597 | -0.4271 |
Objective 2
TEAM | MAE | R | |
1 | BrainAgeDifference | 2.9503 | -0.0311 |
2 | BrainAGE | 3.7989 | -0.0867 |
3 | DRAGN | 3.9242 | 0.0205 |
4 | Quantum Pika | 3.9439 | -0.0147 |
5 | PACMEN | 4.7326 | -0.0147 |
6 | ARAMIS | 4.8320 | -0.0211 |
Winner’s solution
牛津的team, 用了CNN,Ensemble了45个模型, 使用了简单的回归解决bias的问题,获得了objective 1和2的第一。

最后说下参与的感受
由于在准备毕业论文,花了大概3-5天时间,做了简单的信号提取和建模。使用的全部是sklearn里的regressor,然后组装起来,用个人电脑进行训练,大概训练2-3个小时。最后的MAE是5.57,大概是57%的位置,基本满意。MAE比我们实验室另一名博士的项目的结果略好。他研究的就是cognitivereserve和brain age,使用了ElasticNet和全脑GM数据。
自己用的思路很简单
下载预处理好的GM数据,为了简单只用了GM。
用Dosenbach, MSDL和Power模板分别提取GM信号并且做PCA。
测试regressors,比如:

把表现好的regressor组装起来
看到winner’s solution,就会明白如果project不是做这个方向的话,还是以重在参与的心态参加比较好。首先,在建立的模型的时候可以使用自己已有的数据,也就是说完全可以用自己的数据不用训练集,或者将自己的数据加入到训练集中获得更大的数据集。这对于没有大数据access的参赛者并不公平。比如获奖者使用的T1-CNN模型是基于UK Biobank(n=14503)。其次,组织者应该提供服务器,并且规定服务器时间限额,而不是使用自己的设备训练数据。这对于使用个人电脑或者实验室设备一般的参赛者并友好。比如深度学习和2000+的训练集,没有性能强大的服务器是玩不动的。Cole et al., NeuroImage 2017的CNN用了4个Titan的GPU。最后,遗憾的是无法看到别人code。



















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









