







 本文介绍了互金风控体系的构成,包括数据信息、策略体系和模型,并详细阐述了工业建模流程,强调了Y变量选取、样本选取和抽样的重要性。在模型监控部分,讨论了模型效果评估指标和常见问题。最后,提到了规则挖掘中CART树的应用。
本文介绍了互金风控体系的构成,包括数据信息、策略体系和模型,并详细阐述了工业建模流程,强调了Y变量选取、样本选取和抽样的重要性。在模型监控部分,讨论了模型效果评估指标和常见问题。最后,提到了规则挖掘中CART树的应用。
本文是《智能风控原理、算法及工程》第一章学习笔记。
互金风控体系
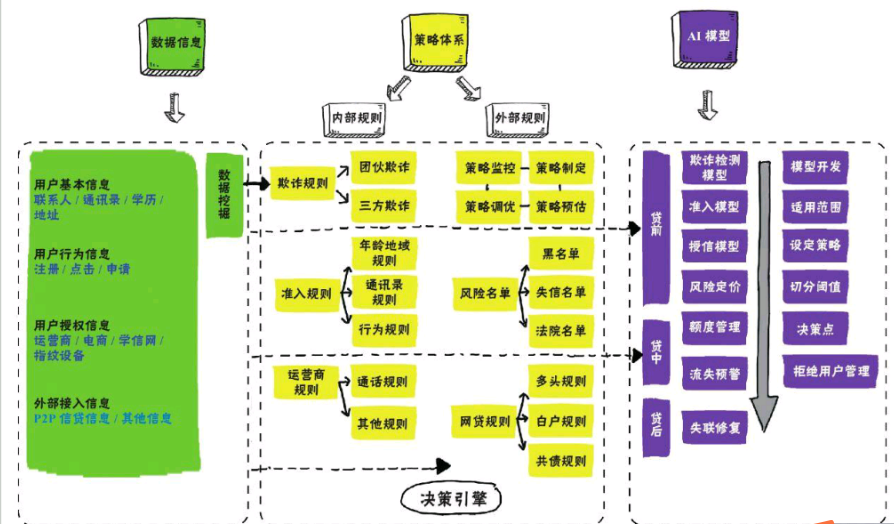
互联网金融风控体系主要由三大部分构成:
- 数据信息:包括用户基本信息、用户行为信息、用户授权信息、外部接入信息。
- 策略体系:包括反欺诈规则、准入规则、运营商规则、风险名单、网贷规则。
- 模型:包括反欺诈模型、准入模型、授信模型、风险定价、额度管理、流失预警、失联修复。
模型中,准入、授信、额度、流失属于二分类模型,失联修复和反欺诈需要使用社交网络算法,而风险定价则是用线性规划(后续学习)。整体的风控体系如下图:
工业建模流程
工业界完整的机器学习模型流程如下:
- 业务抽象成分类或回归问题。
- 定义标签,即选取Y变量。
- 选取样本并选取基本特征。
- 特征工程+模型训练+模型评估+模型调优(可能会有交互)
- 输出模型报告
- 上线与监控
在风控业务中,只有欺诈检测不是二分类任务,因为欺诈手段多变,应该属于多分类任务。欺诈检测可以使用异常检测的方法,如局部异常因子、孤立森林等方法。
Y变量选取
Y变量的选取需要根据模型的目的以及具体的业务形态、数据状况来确定。假定将逾期超过15天视为负样本。则一般不会直接将逾期小于15天作为正样本,而是将逾期小于5天和没有逾期作为正样本,将逾期5-15天作为“灰样本”,放入测试集中。这是因为逾期15天和逾期14天本质上很接近,正负样本的区别不是很明显,去掉中间一部分样本可以使样本分布更趋近于二项分布。
样本选取
评分卡建模通常要求正负样本的数目都不少于1500个,随着样本量的增加模型的效果会显著提升。
数据集在建模前需要划分为3个子集,训练集、测试集、跨时间验证集(OOT)。通常,训练集和测试集的比例为6:4或7:3,跨时间验证集用建模样本中时间切片的最后一段样本。
抽样
抽样分为欠采样和过采样。由于负样本通常较少,因此常对正样本进行欠采样。欠采样的方法分为:
- 随机欠采样:直接将正样本欠采样至预期比例。
- 分层抽样:保证抽样后训练集、测试集、跨时间验证集的正负比例相同。
- 等比例抽样:将正样本欠采样至正负样本比例为1:1。
采样后需要为正样本添加权重,比如正样本采样为原来的1/4,则采样后的正样本权重为4。因为后续计算模型的检验指标或者预期坏账时,需要将权重带入计算逻辑。
当负样本过少时,需要进行代价敏感加权或者过采样处理。
模型监控
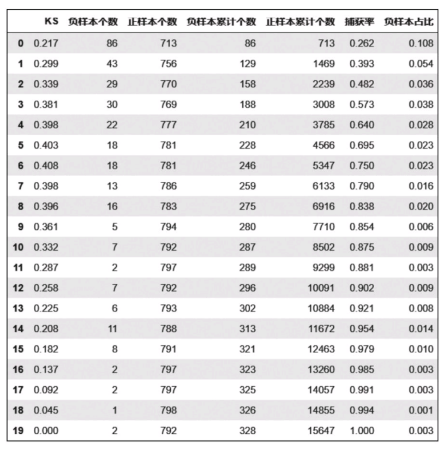
KS取得最大值的箱越靠前,模型的效果越好。
KS值为累计坏样本占坏样本比率-累计好样本占好样本比率,越靠前说明低分段积累的坏样本数相对越多,即捕获率就越大。所以这里的模型效果越好是指阈值以下的捕获率大(捕获率常用来度量模型抓取负样本的能力)。
模型常见问题
这部分问题也是面试过程中被问到较多的。
-
模型训练效果差
模型训练效果差最直观的表现就是KS值低,出现这种情况的主要问题在于特征,其次就是数据质量差。这个时候应该想办法衍生新的特征,尝试扩充数据集。 -
训练集效果好,跨时间验证集效果不好
如果测试集和跨时间验证集效果都不好,说明模型存在过拟合。可以尝试减少模型复杂度,比如减少特征数量等。
如果在测试集上表现较好但是在跨时间验证集上效果不好,这种情况为模型的跨时间稳定性较差。通常是因为特征的跨时间稳定性不好造成的,即随着时间的推移单个特征的取值分布有较大波动,需要提出一些稳定性较差的特征。 -
测试集和跨时间验证集效果都较好,上线之后效果不好
一种可能是过拟合。还有一种可能是线上模型的特征和线下逻辑不一致,需要仔细核对特征逻辑。 -
上线之后效果好,几周之后分数分布逐步失效
这种情况基本认为是特征的稳定性问题,解决方案在特征的跨时间稳定性。通常需要进行模型重构。 -
没有明显问题,但模型每个月逐步失效
这是业界普遍存在的问题,解决方法是模型迭代,一直使用较新的样本就可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









