







文章目录
一、图片输入层面
1. 数据增强策略
-
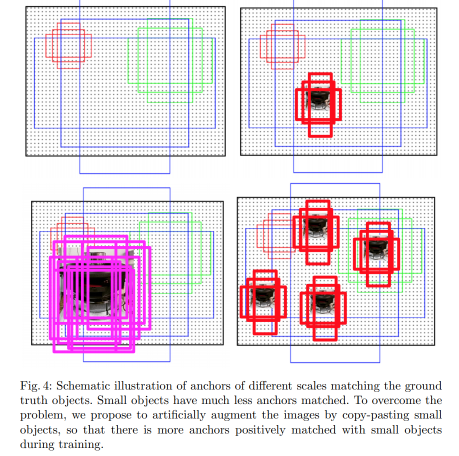
增加包含小目标样本的采样率,缓解了训练过程中包含小目标图片较少的这种不均衡;
-
将小目标在同一张图像中多拷贝几次;增加了匹配到小目标GT的anchor的数量;
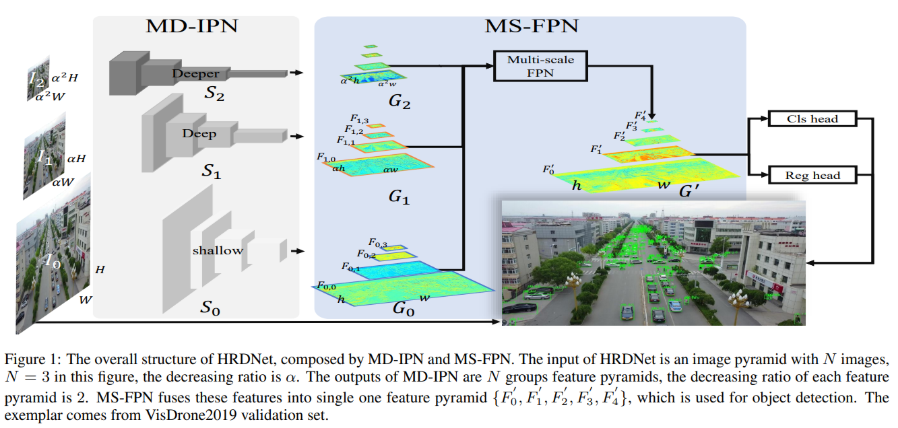
2. 多尺度输入
<HRDNet: High-resolution Detection Network for Small Objects>
多尺度输入分别送入独立的主干网络,然后再FPN层结合,最后输入,计算量太大;
3. SNIP
<An Analysis of Scale Invariance in Object Detection – SNIP>
作者先做了实验,得到在小尺度图像上训练的分类器,得到几个结论:
-
在高分辨率图像上训练的分类器,以低分辨率上采样图像作为输入,效果最差(因为训练和推理明显在scale层面存在domain-shift);
-
在低分辨率图像上训练的分类器,以低分辨率图像作为输入,效果会比CNN-B好很多;
-
在高分辨率图像上训练的分类器,用低分辨率上采样图像fine-tune,然后低分辨率上采样图像作为输入,效果最好。

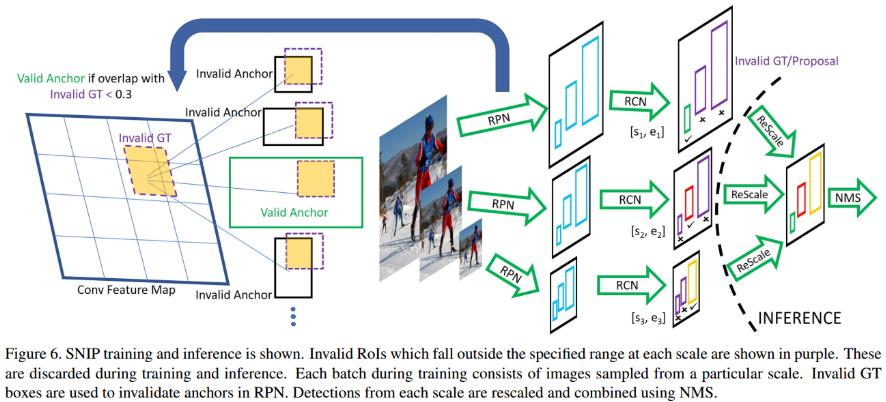
基于以上结论,采用多尺度训练过程中,要在避免那些极小的和极大的(多尺度后)带来的不好的影响时,考虑保证目标有足够的多样性。所以在进行多尺度训练过程中,将每种输入尺度下,不满足要求的proposal以及anchor忽略。论文中使用了三种尺度如图所示,比一般的多尺度训练的尺度跨度要大。

-
训练第二阶段的proposals时,在某个图片输入分辨率下,那些不满足尺寸约束的proposals和GT将被忽略(既不是正样本,也不是负样本),这些ROI将是invalid;
-
对于invalid GT(GT也会分为valid和invalid),训练RPN过程中anchor和这些invalid GT交并比>0.3的将不参与训练;
-
推理时在某个特别的分辨率下,检测框的尺寸不满足要求也会被滤除;
4. SNIPER
略
二、 Neck部分(采用金字塔结构改进方案的)
1. 某种金字塔
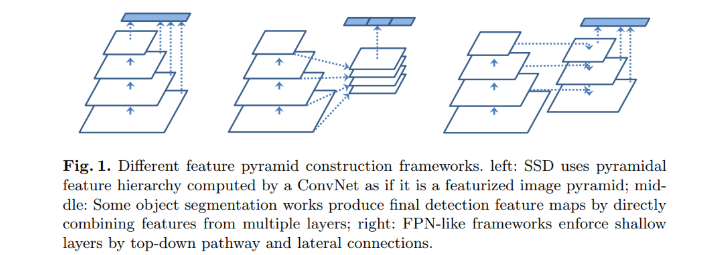
一般意义的FPN网络结构是最右边似的结构,而本文中采用的结构则是
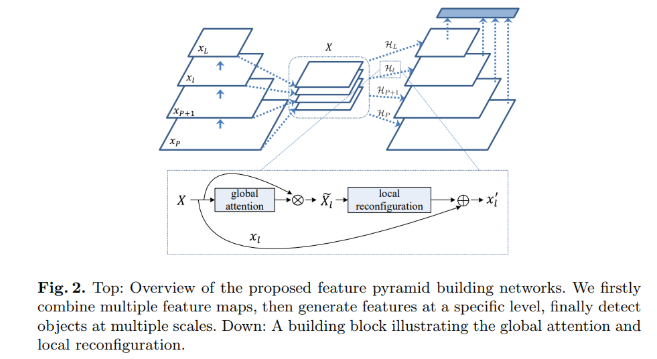
该方法首先无疑是增加了计算量,优点就是最终输出的每一层的特征不是一个线性的变换(应该想表述的说不是从一层特征直接到另一层特征),而是使用共享的多层特征。最终相比RetinaNet提升一个点左右吧,效果一般。VisDrone2020检测的冠军团队采用了这个结构
2. AugFPN
<AugFPN: Improving Multi-scale Feature Learning for Object Detection> 双阶段专用结构,忽略。
3. PANet
PANet 作为path aggregation network(用在neck部分,效果能够提升4个点左右):是基于Mask-rcnn的改进,主要三点贡献:
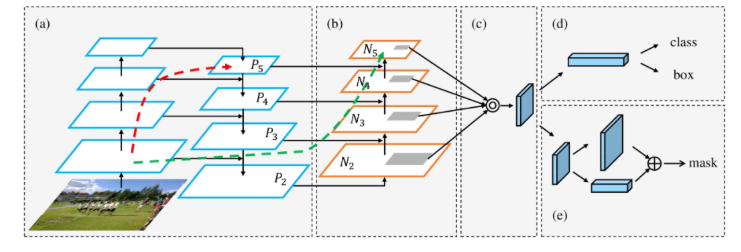
- 自底向上的路径增强,FPN只是将语义信息向下传递,没有对定位信息传递;本文则增加一个自底向上的金字塔,将浅层的定位信息再传递上去;
- 动态特征池化:FPN将每个Proposal根据大小分配到不同的特征层,文中解释大小相近的proposal可能分配到相邻的层;特征的重要程度可能与层级没关系,可以说是强行解释了。我认为这样的好处仅仅是每个proposal聚合了更多层的信息。动态池化也就是同一个proposal根据特征图相应缩放,取到特征后进行融合。(proposal是2-stage的名词,表示前景推荐框。RPN网络得到的ROI需要经过ROI Pooling或者ROI Align提取ROI特征,这一步操作中,其他方法都是单层特征,FPN同样也是基于单层特征。)
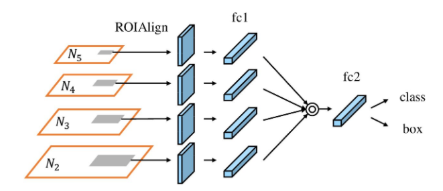
- 全连接层融合:如图所示。
4. M2Det
<M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network>
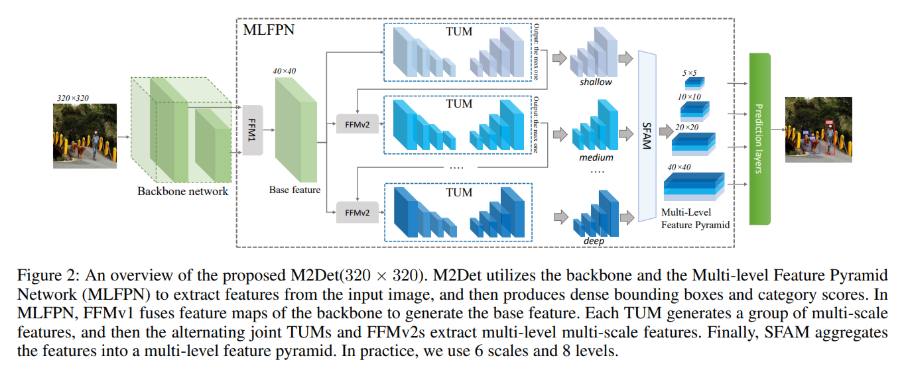
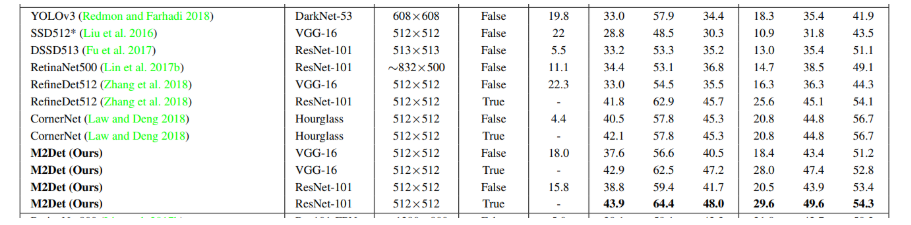
该文章利用多个TUM模块试图更充分构建的特征金字塔的网络结构,靠前的TUM提供浅层特征,中间的TUM提供中间层特征,靠后的TUM提供深层特征,通过这种方式能够多次将深层浅层特征融合,参数量多了。和RetinaNet对比可以看到,512输入,都不采用multi-scale推理,mAP由33提升到37.6,小目标精度也提升了一点;以参数量和计算量堆砌的精度提升,不是好方法。
5. Effective FPN
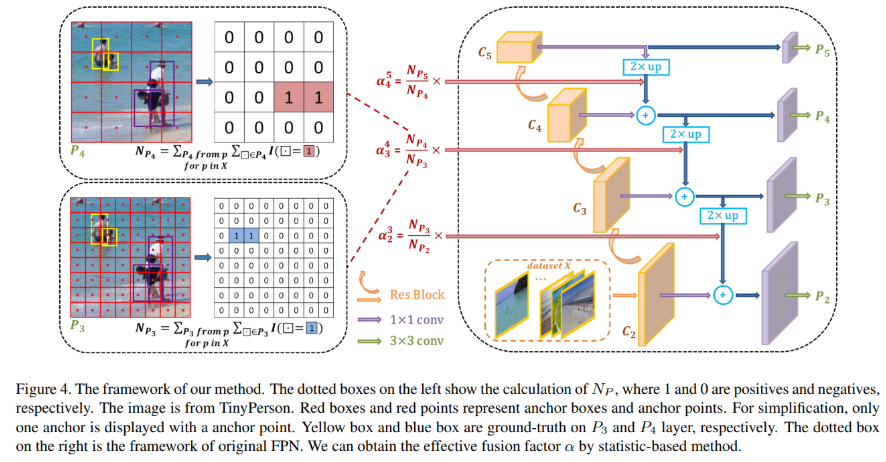
文章认为不同层的重要程度应该和目标的绝对尺度分布有关系,所以在FPN自上而下融合的时候,加入了一个尺度因子用来平衡金字塔不同层的重要性。个人感觉意义不大,实际提升也不明显。
6. MatrixNets
<MatrixNets: A New Scale and Aspect Ratio Aware Architecture for Object Detection>
1. 采用centerNet作为base:
* GT根据长宽比分配到具体的layer,再分配到最近的特征点,用来训练中心点热力图;
* 由具体的中心点来回归左上和右下角点;
* 采用的soft nms;
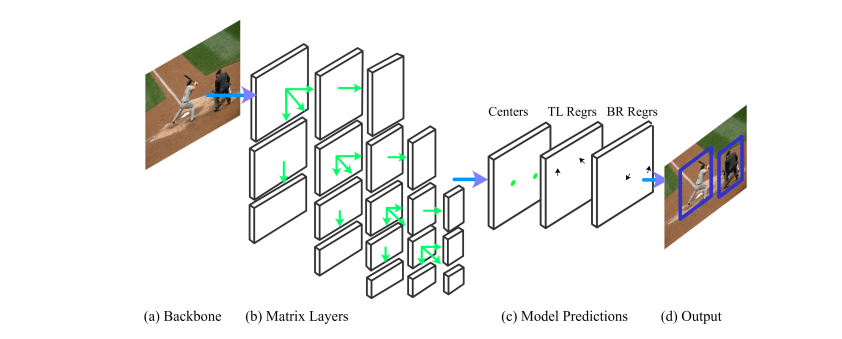
2. 采用cornerNet作为base: 略
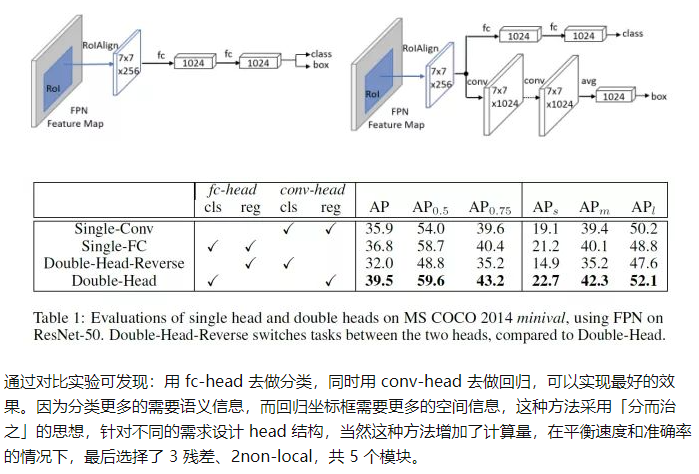
三、 Head部分的改进方案
在VisDrones上的冠军方案和若干其他方案都采用了这种“双头部”的方案。soft-NMS似乎可以提升几个点。
四、 其他
小目标目前检测不好,主要原因不是小,应该是小且和背景接近,对比度不高。所以可以借鉴伪装物体检测的思路;















 2829
2829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









