







文章目录
引言
经过多年实践经验后,总结了一下Face landmark的一些东西,在此记录一下。
技术路线
Face landmark预测技术路线主要有两种:
- Directly regression methods
- MTCNN:给出人脸框和5个人脸关键点
- PFLD:端侧好用,经过本人很早之前的复现,其实损失没必要写的那么复杂也可以达到同样的效果(甚至不需要角度监督),主要是丹要练得好。
- Style Aggregated Network (SAN)
- Deep Adaptive Graph (DAG)
- heatmap regression methods
- Style Aggregated Network (SAN)
- MobileFAN:降低模型参数,增加推理速度
- 当然结合两种的比如"Look at boundary" (LAB),效果确实好,但是速度慢
优秀损失
- L1/L2自然不用多说;
- Smooth L1,解决了L1损失在面临小误差时误差损失依旧很大,不稳定的问题;以及L2损失对outliers比较敏感(大误差损失很大)的问题;
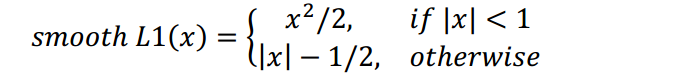
- Wing loss,L1针对大的误差,ln()针对小的中的误差。
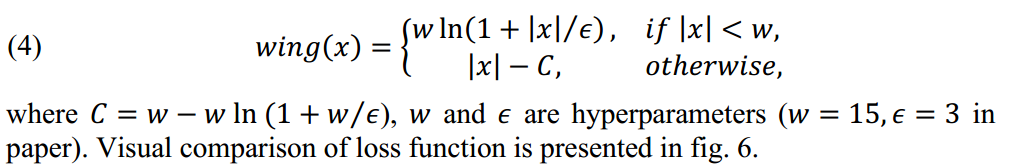
- AWing loss,自适应改变前景背景的热力图的损失,是Wing的改进款
文章阅读
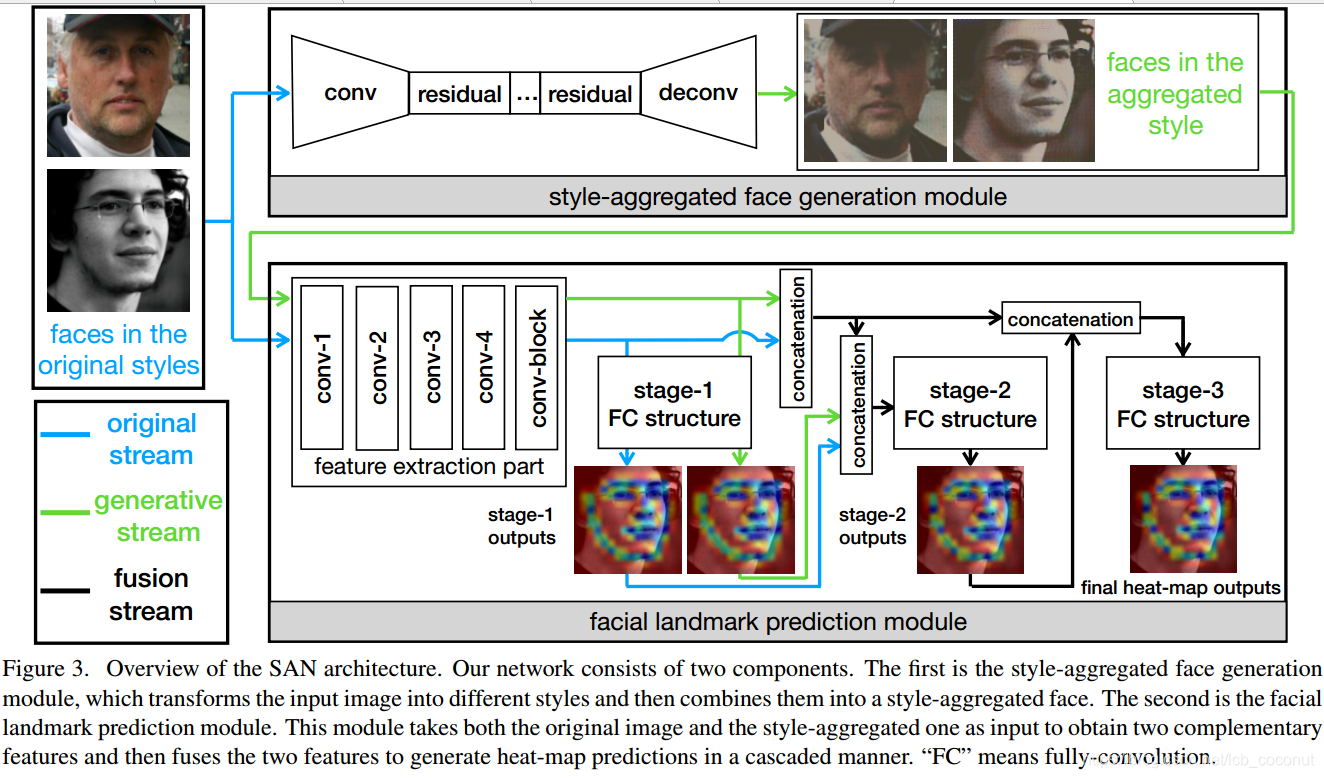
Style Aggregated Network for Facial Landmark Detection
原理
本篇文章主要是工程应用上会有些帮助,在实际应用中,有很多harsh light/style/pose/emotion/的情形,该文章通过cycleGan生成了多种模态的数据,增加关键点估计在多种复杂光照和图像风格中的泛化性能。
损失

其中H是
R
(
k
+
1
)
∗
h
∗
w
R^{(k+1) * h * w}
R(k+1)∗h∗w
k是关键点数量,hw是图像输出高和宽。
思考
- 基于热力图的方法,输出的热力图每一channel层代表一个关键点的热力。
为何这种热力图的方式不会隐式的学习到关键点之间的空间位置约束?每个layer卷积也会将前layer的所有channel都用上,为啥还是没有学到空间约束?
难道是这种直接在feature上得到响应值的方式,要比起利用全连接层给到每个点的回归更独立一些? - 其实与其这么使用cycleGan生成的数据,不如增加分类模块,迫使网络学习域不变信息(真正的脸部关键点特征信息,与颜色、风格无关)好用!!!
Structured Landmark Detection via Topology-Adapting Deep Graph Learning (DAG)
原理
- 先学习一个透视变换矩阵,将标准人脸关键点经过预测,粗投影到人脸上;
- 再学习精细的变换:利用每个关键点的visual feature (D维) 和shape feature (2(N-1)维,是每个关键点和剩下N-1个关键点的二维向量) 结合成一个如下维度的数据。去学习一个移动向量;
R D + 2 ( N − 1 ) R^{D+2(N-1)} RD+2(N−1)
该文章较好的利用了点之间的结构关系,主要就是能解决遮挡问题下被遮挡关键点严重不准的问题。其实即使不使用这种结构关系,关键点之间的几何关系(空间位置约束)完全可以被隐式的学习到。PFLD训练得到的经验。
损失
可以看出第一步的粗损失采用L1距离,第二步的精损失也采用L1距离。

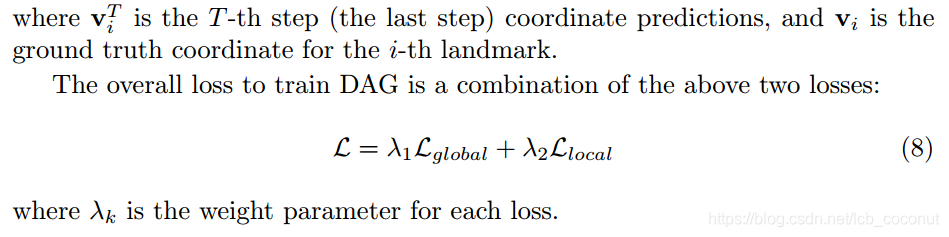














 3993
3993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









