







文章目录
《Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection》
1. 整体理解
主要就是两个模块,一个是Domain Diversification (DD),另一个是Multi-domain-invariant Representation Learning (MRL)
- Domain Diversification (DD) is a method which diversifies the source domain by intentionally generating distinctive domain discrepancy through these domain shifters. The diversified distribution of the labeled data encourages the model to infer among data with large intraclass variance discriminatively. Thus, the model is enforced to extract semantic features that are not biased to a particular domain. This allows the model to extract unbiased semantic features from the target domain, which is more discriminative than the source-biased features. With the better discriminativity of target domain features, we can assimilate the domains with less feature collapse, resulting in more desirable adaptation.
DD可以是采用CycleGan得到的各种各样的domain shifters,得到这些不同的domain,主要作用是使得网络学习到并不向某个特定domain偏移的语义特征。如图为不同的domain下的图片。

通过训练一个个Generators (G) 来得到不同domain下的数据集,但是由于G的容量足以学习多种多样的变化,因此本文在对抗损失的基础上加入一个“限制损失”保证G能够得到我们希望的变化。

- Multi-domain-invariant Representation Learning (MRL)
pseudo-label的方法会有大量的训练过程是依赖于tranlated s的,这样可能会带来另一种域偏移问题。本文设计对抗学习的方法MRL,促进学习域不变特征。
对于大多数其他的域适应方法,不同域的数据会被送入一个二分类器(源域/目标域分类),然而多个不同域的数据,如果只采用二分类器的话,会干扰网络的特征学习,因此本文采用n+2(n个生成器的变换域,源域和目标域)分类器来区分不同域。
传统的cross-domain adaption方法通过对抗学习来“骗过”判别器(discriminator),就是一个二分类器,这也就是尽可能使一个域的输出特征尽可能与另一个域的输出特征相似。然而对于有多个域的数据的话,判别器无法只采用一个二分类器,来使得网络学习某个域像另一个域的特征,因此通过gradient reverse layer (GRL)来迫使网络学习不像当前域的特征,使得网络学习到域不变的特性。
这里我要补充一点:GRL说白了,其实对抗的discriminator就是n+2的二分类器,判别器学习过程,学习是否属于当前类别;而生成器学习过程中,学习不属于当前类别的特征。

- 整体结构
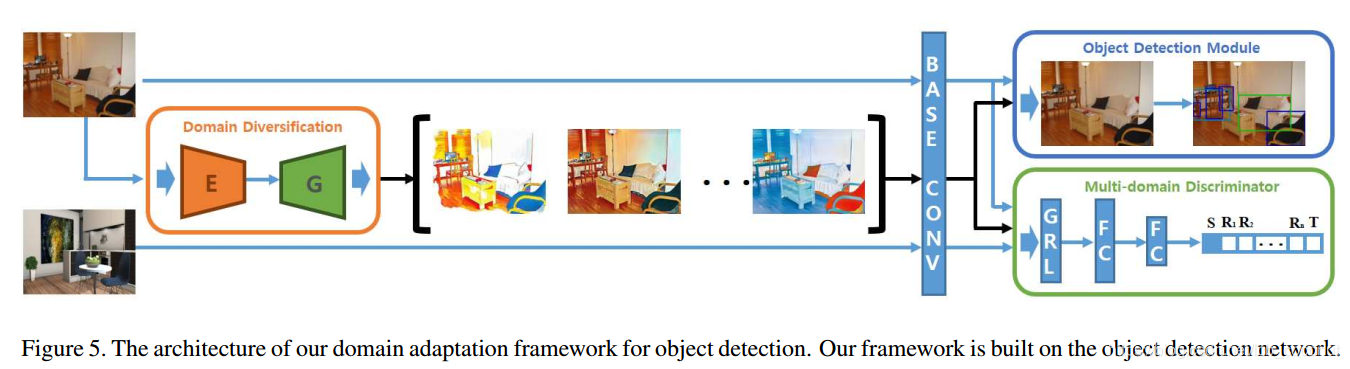
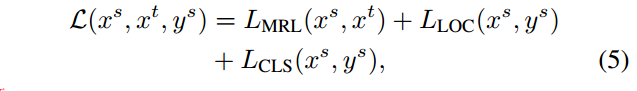
源域以及变换域参与到检测常用的“回归”+“分类”损失计算当中,而MRL损失是由所有源域+变换域+目标域的数据都参与计算,着重看公式(6)的损失计算,由公式(4)得到每一个域的分类损失。

2. 实施细节
2.1 DD模块
Domain shift considering color preservation 第一种用于颜色保留的限制损失:
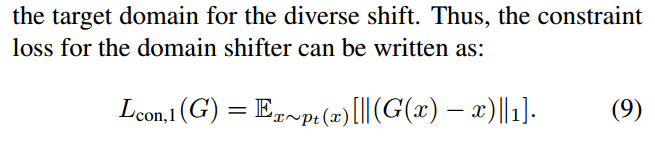
Domain shift considering construction 第二种用于重建的限制损失(其实完全来源于CycleGan):

第三种限制损失则为以上两种限制损失直接相加:
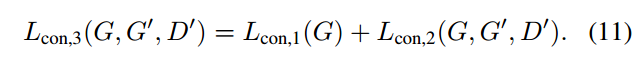
以上三种限制损失可以得到三种shifted domains,文章利用这三种限制损失分别得到三个domains的数据,用于训练检测模型。 作者发现n越大,也就是domains越多,效果越好。
2.2 MRL以及检测模块
训练是有个细节,batch size = n+2,代表shifted domains的种类。
3. 总结
- shifted domains数量越多,效果越好
- shifted domains数量多,会放大MRL的效果















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









