







Convolutional Neural Networks: Step by Step
3 - Convolutional Neural Networks
3.1 - Zero-Padding
def zero_pad(X, pad):
"""
Pad with zeros all images of the dataset X. The padding is applied to the height and width of an image,
as illustrated in Figure 1.
Argument:
X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images
pad -- integer, amount of padding around each image on vertical and horizontal dimensions
Returns:
X_pad -- padded image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C)
"""
### START CODE HERE ### (≈ 1 line)
X_pad = np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),'constant', constant_values = 0)
### END CODE HERE ###
return X_pad3.2 - Single step of convolution
def conv_single_step(a_slice_prev, W, b):
s = np.multiply(a_slice_prev,W)+b
Z = np.sum(s)
return Z3.3 - Convolutional Neural Networks - Forward pass
def conv_forward(A_prev, W, b, hparameters):
(m, n_H_prev, n_W_prev, n_C_prev) =A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters['stride']
pad = hparameters['pad']
n_H = int(1+((n_H_prev-f+2*pad)/stride))
n_W = int(1+((n_W_prev-f+2*pad)/stride))
Z = np.zeros((m,n_H,n_W,n_C))
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m):
a_prev_pad = A_prev_pad[i,:,:,:]
for h in range(n_H-stride+1):
for w in range(n_W-stride+1):
for c in range(n_C):
vert_start = h
vert_end = h+f
horiz_start = w
horiz_end = w+f
a_slice_prev =a_prev_pad
[vert_start:vert_end,horiz_start:horiz_end,:]
Z[i, h, w, c] = conv_single_step(a_slice_prev,W[:,:,:,c],b[:,:,:,c])
assert(Z.shape == (m, n_H, n_W, n_C)
cache = (A_prev, W, b, hparameters)
return Z, cache4 - Pooling layer
4.1 - Forward Pooling
def pool_forward(A_prev, hparameters, mode = "max"):
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
f = hparameters["f"]
stride = hparameters["stride"]
n_H = int(1 + (n_H_prev - f) / stride)
n_W = int(1 + (n_W_prev - f) / stride)
n_C = n_C_prev
A = np.zeros((m, n_H, n_W, n_C))
for i in range(m):
for h in range(n_H):
for w in range(n_W):
for c in range (n_C):
vert_start = h
vert_end = h+f
horiz_start = w
horiz_end = w+f
a_prev_slice = A_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]
if mode == "max":
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":
A[i, h, w, c] = np.mean(a_prev_slice)
return A, cache5 - Backpropagation in convolutional neural networks (OPTIONAL / UNGRADED)
5.1 - Convolutional layer backward pass
def conv_backward(dZ, cache):
(A_prev, W, b, hparameters) = cache
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
(f, f, n_C_prev, n_C) = W.shape
stride = hparameters['stride']
pad = hparameters['pad']
(m, n_H, n_W, n_C) = dZ.shape
dA_prev = np.zeros((m, n_H_prev
dW = np.zeros((f, f, n_C_prev, n
db = np.zeros((1, 1, 1, n_C))
A_prev_pad = zero_pad(A_prev,pad)
dA_prev_pad = zero_pad(dA_prev,pad)
for i in range(0,m):
a_prev_pad = A_prev_pad[i]
da_prev_pad = dA_prev_pad[i]
for h in range(n_H-stride+1):
for w in range(n_W-stride+1):
for c in range(n_C):
vert_start = h
vert_end = h+f
horiz_start = w
horiz_end = w+f
a_slice = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c]
dW[:,:,:,c] += a_slice * dZ[i, h, w, c]
db[:,:,:,c] += dZ[i, h, w, c]
dA_prev[i, :, :, :] = da_prev_pad[pad:-pad, pad:-pad, :]
assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev))
return dA_prev, dW, db5.2 Pooling layer - backward pass
5.2.1 Max pooling - backward pass
def create_mask_from_window(x):
mask = (x==np.max(x))
return mask5.2.2 - Average pooling - backward pass
def distribute_value(dz, shape):
(n_H, n_W) =shape
average =dz/(n_H*n_W)
a = np.ones((n_H, n_W))*average
return a5.2.3 Putting it together: Pooling backward
def pool_backward(dA, cache, mode = "max"):
(A_prev, hparameters) = cache
stride = hparameters['stride']
f = hparameters['f']
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
m, n_H, n_W, n_C = dA.shape
dA_prev = np.zeros((m, n_H_prev, n_W_prev, n_C_prev))
for i in range(m):
a_prev = A_prev[i]
for h in range(n_H-stride+1):
for w in range(n_W-stride+1):
for c in range(n_C):
vert_start = h
vert_end = h+f
horiz_start = w
horiz_end = w+f
if mode == "max":
a_prev_slice = a_prev[vert_start:vert_end,horiz_start:horiz_end,c]
mask = create_mask_from_window(a_prev_slice)
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += mask*dA[i,h,w,c]
elif mode == "average":
da = dA[i,h,w,c]
shape = (f,f)
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)
assert(dA_prev.shape == A_prev.shape)
return dA_prevmode = max
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0. 0. ]
[ 5.05844394 -1.68282702]
[ 0. 0. ]]
mode = average
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0.08485462 0.2787552 ]
[ 1.26461098 -0.25749373]
[ 1.17975636 -0.53624893]]
Convolutional Neural Networks: Application
1.0 - TensorFlow model
1.1 - Create placeholders
def create_placeholders(n_H0, n_W0, n_C0, n_y):
X = tf.placeholder(tf.float32,[None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32,[None, n_y])
return X, Y1.2 - Initialize parameters
def initialize_parameters():
W1 = tf.get_variable("W1",[4,4,3,8],initializer=tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable("W2",[2,2,8,16],initializer=tf.contrib.layers.xavier_initializer(seed = 0))
parameters = {"W1": W1,
"W2": W2}
return parameters1.2 - Forward propagation
def forward_propagation(X, parameters):
W1 = parameters['W1']
W2 = parameters['W2']
Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')
A1 = tf.nn.relu(Z1)
P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')
Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')
A2 = tf.nn.relu(Z2)
P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')
P2 = tf.contrib.layers.flatten(P2)
Z3 = tf.contrib.layers.fully_connected(P2,num_outputs=6,activation_fn=None)
return Z31.3 - Compute cost
def compute_cost(Z3, Y):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = Z3, labels = Y))
return cost1.4 Model
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,
num_epochs = 100, minibatch_size = 64, print_cost = True):
X, Y = create_placeholders(64, 64, 3, 6)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate = 0.009).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size)
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_ , temp_cost = sess.run([optimizer, cost], feed
_dict={X: minibatch_X, Y: minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
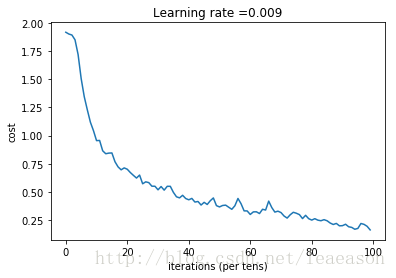
return train_accuracy, test_accuracy, parameters训练结果
Cost after epoch 0: 1.917929
Cost after epoch 5: 1.506757
Cost after epoch 10: 0.955359
Cost after epoch 15: 0.845802
Cost after epoch 20: 0.701174
Cost after epoch 25: 0.571977
Cost after epoch 30: 0.518435
Cost after epoch 35: 0.495806
Cost after epoch 40: 0.429827
Cost after epoch 45: 0.407291
Cost after epoch 50: 0.366394
Cost after epoch 55: 0.376922
Cost after epoch 60: 0.299491
Cost after epoch 65: 0.338870
Cost after epoch 70: 0.316400
Cost after epoch 75: 0.310413
Cost after epoch 80: 0.249549
Cost after epoch 85: 0.243457
Cost after epoch 90: 0.200031
Cost after epoch 95: 0.175452
Tensor(“Mean_1:0”, shape=(), dtype=float32)
Train Accuracy: 0.940741
Test Accuracy: 0.783333

















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









