







1. Motivation: residual connections work well for deep network ==> can be combined with
Inception (
Inception-ResNet)
a. replace filter concatenation of
inception with residual connection
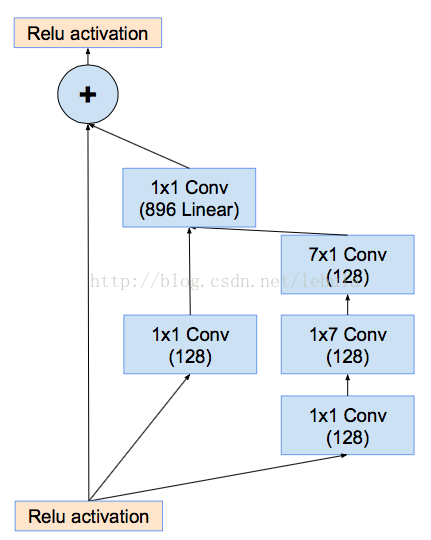
(the 1 x 1 conv after
inception layer aims to scale up the dimension before adding to the input)
b. scaling down the residuals (multiple scaling factor 0.1~0.3) before addition ==> stabilize the training (prevent weights from going to 0)
2. Batch normalization: on top of traditional layers (excluding summation layer to reduce computational cost), prevent saturating.
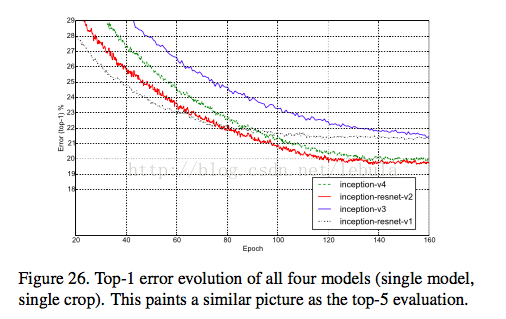
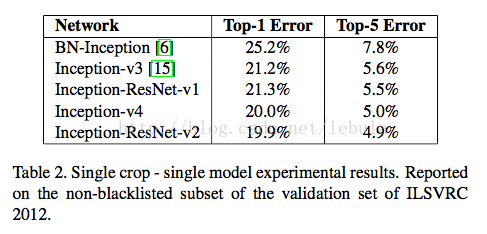
3. performance.(for detailed differences bw models, please refer to the paper)















 3433
3433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









