




 本文是《从零开始做OpenCL开发》系列的第一篇,介绍了OpenCL作为异构计算标准的背景和意义。OpenCL提供了一个跨平台的框架,利用GPU的强大并行计算能力进行高效计算,模糊了CPU和GPU的界限。文章概述了OpenCL的硬件层、内存架构和软件层面的组成,包括Device、Context、Command queue、Program、Kernel等概念,强调了OpenCL在通用计算和并行处理中的潜力和应用前景。
本文是《从零开始做OpenCL开发》系列的第一篇,介绍了OpenCL作为异构计算标准的背景和意义。OpenCL提供了一个跨平台的框架,利用GPU的强大并行计算能力进行高效计算,模糊了CPU和GPU的界限。文章概述了OpenCL的硬件层、内存架构和软件层面的组成,包括Device、Context、Command queue、Program、Kernel等概念,强调了OpenCL在通用计算和并行处理中的潜力和应用前景。
多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/article/details/8880012
本文将作为我《从零开始做OpenCL开发》系列文章的第一篇。
1 异构计算、GPGPU与OpenCL
OpenCL是当前一个通用的由很多公司和组织共同发起的多CPU\GPU\其他芯片 异构计算(heterogeneous)的标准,它是跨平台的。旨在充分利用GPU强大的并行计算能力以及与CPU的协同工作,更高效的利用硬件高效的完成大规模的(尤其是并行度高的)计算。在过去利用GPU对图像渲染进行加速的技术非常成熟,但是我们知道GPU的芯片结构擅长大规模的并行计算(PC级的GPU可能就是CPU的上万倍),CPU则擅长逻辑控制,因此不只局限与图像渲染,人们希望将这种计算能力扩展到更多领域,所以这也被称为GPGPU(即通用处计算处理的GPU)。
简单的说,我们的CPU并不适合计算,它是多指令单数据流(MISD)的体系结构,更加擅长的是做逻辑控制,而数据处理基本是单流水线的,所以我们的代码for(i=0;...;i++)这种在CPU上要重复迭代的跑很多遍,但是你的显卡GPU则不是这样,GPU是典型的单指令多数据(SIMD)的体系结构,它不擅长逻辑控制,但是确实天生的向量计算机器,对于for(i=0;...;i++)这样的代码有时只需要跑一遍,所以图形世界中那么多的顶点、片段才能快速的并行在显卡中渲染处理
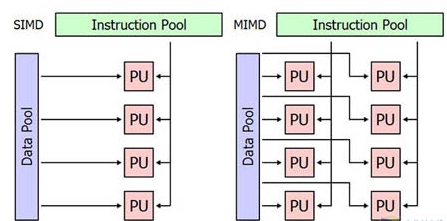
GPU的晶体管可以到几十亿个,而CPU通常只有几个亿,
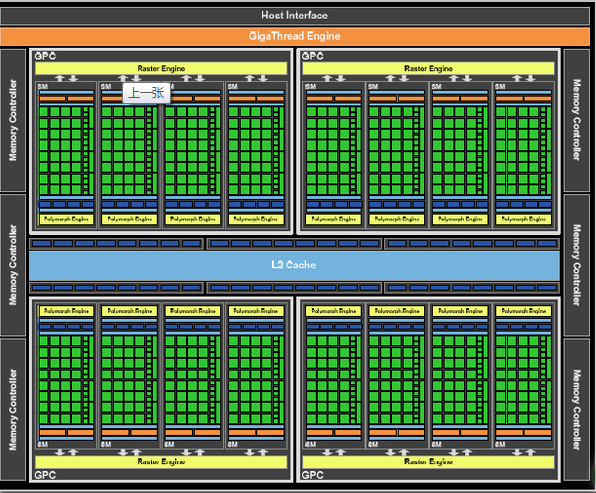
如上图是NVidia Femi100的结构,它有着大量的并行计算单元。
所以人们就想如何将更多的计算代码搬到GPU上,让他不知做rendering,而CPU只负责逻辑控制,这种一个CPU(控制单元)+几个GPU(有时可能再加几个CPU)(计算单元)的架构就是所谓的异构编程(heterogeneous),在这里面的GPU就是GPGPU。异构编程的前景和效率是非常振奋人心的,在很多领域,尤其是高并行度的计算中,效率提升的数量级不是几倍,而是百倍千倍。
其实NVIDIA在很早就退出了利用其显卡的GPGPU计算 CUDA架构,当时的影响是很大的,将很多计算工作(科学计算、图像渲染、游戏)的问题提高了几个数量级的效率,记得那时NVIDIA来浙大介绍CUDA,演示了实时的ray tracing、大量刚体的互相碰撞等例子,还是激动了一下的,CUDA现在好像已经发展到了5.0,而且是NVDIA主力推的通用计算架构,但是CUDA最大的局限就是它只能使用N家自己的显卡,对于广大的A卡用户鞭长莫及。OpenCL则在之后应运而生,它由极大主流芯片商、操作系统、软件开发者、学术机构、中间件提供者等公司联合发起,它最初由Apple提出发起标准,随后Khronos Group成立工作组,协调这些公司共同维护这套通用的计算语言。Khronos Group听起来比较熟悉吧,图像绘制领域著名的软硬件接口API规范著名的OpenGL也是这个组织维护的,其实他们还维护了很多多媒体领域的规范,可能也是类似于Open***起名的(所以刚听到OpenCL的时候就在想它与OpenGl有啥关系),OpenCl没有一个特定的SDK,Khronos Group只是指定标准(你可以理解为他们定义头文件),而具体的implementation则是由不同参与公司来做,这样你会发现NVDIA将OpenCL做了实现后即成到它的CUDA SDK中,而AMD则将其实现后放在所谓是AMD APP (Accelerated Paral Processing)SDK中,而Intel也做了实现,所以目前的主流CPU和GPU都支持OpenCL架构,虽然不同公司做了不同的SDK,但是他们都遵照同样的OpenCL规范,也就是说原则上如果你用标准OpenCl头中定义的那些接口的话,使用NVIDIA的SDK编的程序可以跑在A家的显卡上的。但是不同的SDK会有针对他们芯片的特定扩展,这点类似于标砖OpenGL库和GL库扩展的关系。
OpenGL的出现使得AMD在GPGPU领域终于迎头赶上的NVIDIA,但是NVIDIA虽为OpenCL的一员,但是他们似乎更加看重自己的独门武器CUDA,所以N家对OpenCL实现的扩展也要比AMD少,AMD由于同时做CPU和GPU,还有他们的APU,似乎对OpenCL更来劲一些。
2.关于在GPU上写代码的那些事儿
OpenCL也是通过在GPU上写代码来加速,只不过他把CPU、GPU、其他什么芯片给统一封装了起来,更高了一层,对开发者也更友好。说到这里突然很想赘述一些在GPU上写代码的那些历史。。
其实最开始显卡是不存在的,最早的图形处理是放在CPU上,后来发现可以再主板上放一个单独的芯片来加速图形绘制,那时还叫图像处理单元,直到NVIDIA把这东西做强做大,并且第一给它改了个NB的称呼,叫做GPU,也叫图像处理器,后来GPU就以比CPU高几倍的速度增长性能。
开始的时候GPU不能编程,也叫固定管线的,就是把数据按照固定的通路走完
和CPU同样作为计算处理器,顺理成章就出来了可编程的GPU,但是那时候想在GPU上编程可不是容易的事,你只能使用GPU汇编来写GPU程序,GPU汇编?听起来就是很高级的玩意儿,所以那时使用GPU绘制很多特殊效果的技能只掌握在少数图形工程师身上,这种方式叫可编程管线。
很快这种桎桍被打破,GPU上的高级编程语言诞生,在当时更先进的一些显卡上(记忆中应该是3代显卡开始吧),像C一样的高级语言可以使程序员更加容易的往GPU写代码,这些语言代表有nvidia和微软一起创作的CG,微软的HLSL,openGl的GLSL等等,现在它们也通常被称为高级着色语言(Shading Language),这些shader目前已经被广泛应用于我们的各种游戏中。
在使用shading language的过程中,一些科研人员发现很多非图形计算的问题(如数学、物理领域的并行计算)可以伪装成图形问题利用Shading Language实现在GPU上计算,而这结果是在CPU上跑速度的N倍,人们又有了新的想法,想着利用GPU这种性能去解决所有大量并行计算的问题(不只图形领域),这也叫做通用处理的GPU(GPGPU),很多人尝试这样做了,一段时间很多论文在写怎样怎样利用GPU算了哪个东东。。。但是这种工作都是伪装成图形处理的形式做的,还没有一种天然的语言来让我们在GPU上做通用计算。这时又是NVIDIA带来了革新,09年前后推出的GUDA架构,可以让开发者在他们的显卡上用高级语言编写通用计算程序,一时CUDA热了起来,直到现在N卡都印着大大的CUDA logo,不过它的局限就是硬件的限制。
OpenCL则突破了硬件的壁垒,试图在所有支持的硬件上搭建起通用计算的协同平台,不管你是cpu还是gpu通通一视同仁,都能进行计算,可以说OpenCL的意义在于模糊了主板上那两种重要处理器的界限,并使在GPU上跑代码变得更容易。
3 OpenCL架构
3.1 硬件层:
上面说的都是关于通用计算以及OpenCL是什么,下面就提纲挈领的把OpenCL的架构总结一下:
以下是OpenCL硬件层的抽象
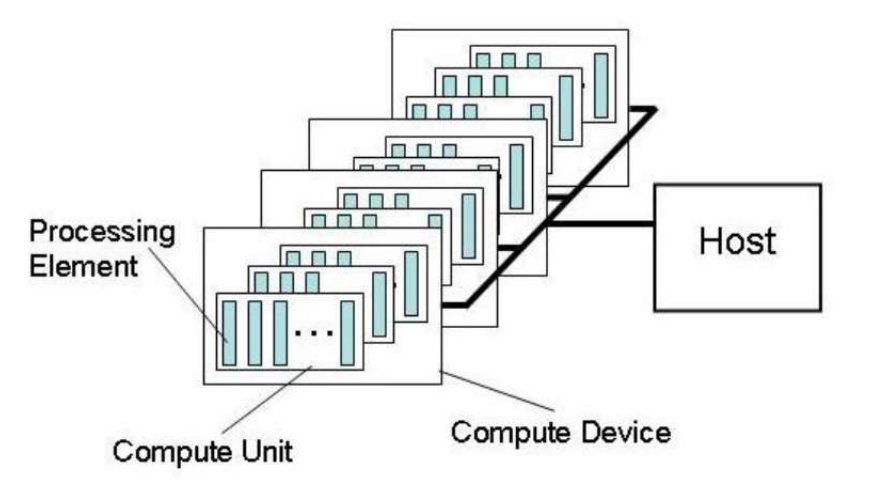
它是一个Host(控制处理单元,通常由一个CPU担任)和一堆Computer Device(计算处理单元,通常由一些GPU、CPU其他支持的芯片担任),其中Compute Device切分成很多Processing Element(这是独立参与单数据计算的最小单元,这个不同硬件实现都不一样,如GPU可能就是其中一个Processor,而CPU可能是一个Core,我猜的。。因为这个实现对开发者是隐藏的),其中很多个Processing Element可以组成组为一个Computer Unit,一个Unit内的element之间可以方便的共享memory,也只有一个Unit内的element可以实现同步等操作。
3.2 内存架构
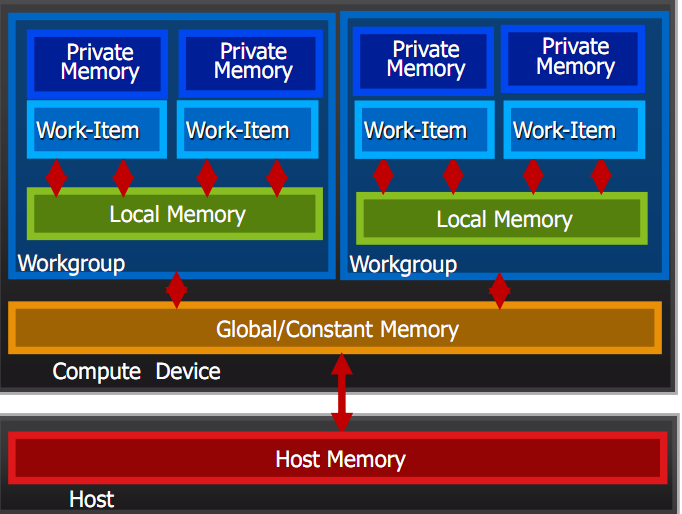
其中Host有自己的内存,而在compute Device上则比较复杂,首先有个常量内存,是所有人能用的,通常也是访问最快的但是最稀少的,然后每个element有自己的memory,这是private的,一个组内的element有他们共用的一个local memery。仔细分析,这是一个高效优雅的内存组织方式。数据可以沿着Host-》gloabal-》local-》private的通道流动(这其中可能跨越了很多个硬件)。
3.3软件层面的组成
这些在SDK中都有对应的数据类型
setup相关:
Device:对应一个硬件(标准中特别说明多core的CPU是一个整个Device)
Context:环境上下文,一个Context包含几个device(单个Cpu或GPU),一个Context就是这些device的一个联系纽带,只有在一个Context上的那些Device才能彼此交流工作,你的机器上可以同时存在很多Context。你可以用一个CPu创建context,也可以用一个CPU和一个GPU创建一个。
Command queue:这是个给每个Device提交的指令序列
内存相关:
Buffers:这个好理解,一块内存
Images:毕竟并行计算大多数的应用前景在图形图像上,所以原生带有几个类型,表示各种维度的图像。
gpu代码执行相关:
Program:这是所有代码的集合,可能包含Kernel是和其他库,OpenCl是一个动态编译的语言,代码编译后生成一个中间文件(可实现为虚拟机代码或者汇编代码,看不同实现),在使用时连接进入程序读入处理器。
Kernel:这是在element跑的核函数及其参数组和,如果把计算设备看做好多人同时为你做一个事情,那么Kernel就是他们每个人做的那个事情,这个事情每个人都是同样的做,但是参数可能是不同的,这就是所谓的单指令多数据体系。
WorkI tem:这就是代表硬件上的一个Processing Element,最基本的计算单元。
同步相关:
Events:在这样一个分布式计算的环境中,不同单元之间的同步是一个大问题,event是用来同步的
他们的关系如下图
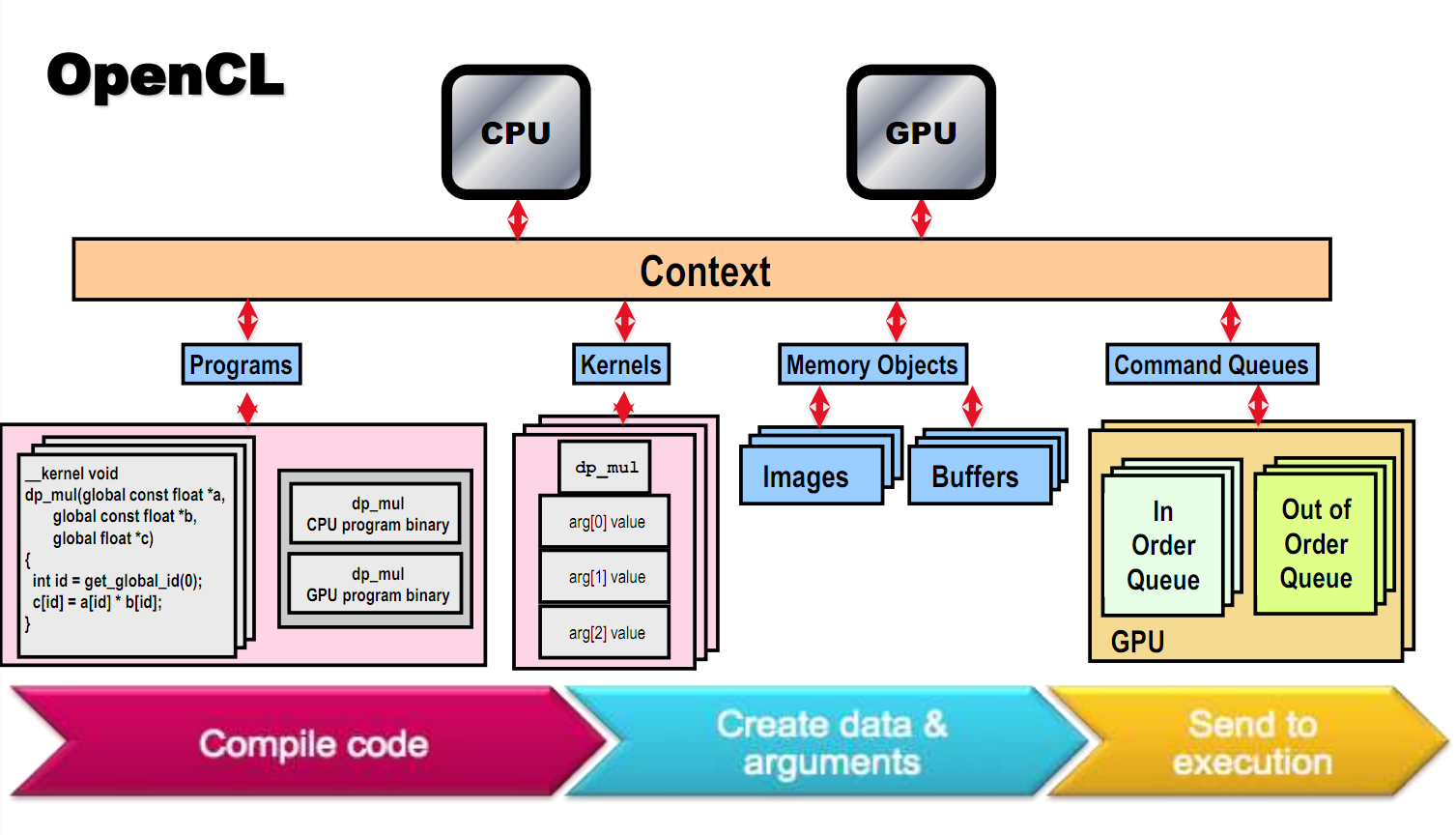
上面就是OpenCL的入门介绍,其实说实话在10年左右就跟踪过GPGPU相关的东西,那时很多相关技术还存在于实验室,后来的CUDA出现后,也激动过,学习过一阵,不过CUDA过度依赖于特定硬件,产业应用前景并不好,只能做做工程试验,你总不能让用户装个游戏的同时,让他顺便换个高配的N卡吧。所以一度也对这个领域不太感兴趣,最近看到OpenCL的出现,发现可能这个架构还是有很好的应用前景的,也是众多厂商目前合力力推的一个东西。想想一下一个迭代10000次的for循环一遍过,还是很激动的一件事。
在游戏领域,OpenCL已经有了很多成功的实践,好像EA的F1就已经应用了OpenCL,还有一些做海洋的lib应用OpenCL(海面水波的FFT运算在过去是非常慢的),另外还有的库干脆利用OpenCL去直接修改现有的C代码,加速for循环等,甚至还有OpenCl版本的C++ STL,叫thrust,所以我觉得OpenCL可能会真正的给我们带来些什么~
以下是一些关于OpenCL比较重要的资源:
http://www.khronos.org/opencl/ 组织的主页
https://developer.nvidia.com/opencl N家的主页
http://developer.amd.com/resources/heterogeneous-computing/opencl-zone/ A家的主页
http://www.khronos.org/registry/cl/sdk/1.2/docs/man/xhtml/ 标准的reference
http://developer.amd.com/wordpress/media/2012/10/opencl-1.2.pdf 必看 最新的1.2版本标准
http://www.khronos.org/assets/uploads/developers/library/overview/opencl-overview.pdf 必看,入门的review


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









